


- 李蘭萱 (Lan-Xuan Li)/政治大學財務管理研究所碩士生,目前於產業分析研究崗位實習。主要專業領域為計量經濟、金融創新服務、ICT 數位化科技應用等。喜歡桌球,並認為必須結合統計、科技,才可以描繪出未來「以人為中心」的商業模式。
靠臉領錢辦得到嗎?其實科幻場景已很近
不知道大家有沒有遇過一種情況呢?急需用錢時站在 ATM 前準備提款,卻發現自己忘記金融卡密碼了,隨著身後排隊的人群愈來愈多,心也逐漸焦躁不安,與此同時,或許你的腦中會惱怒地想著:
「如果可以靠臉領錢那該有多好啊!」
這敘述乍看之下彷彿是僅存於科幻電影中的想像,但實際上,隨著科技發展,這種操作已非遙不可及。「只要站在鏡頭前刷臉就能提款轉帳」的未來,其實比想像中還要近。

想成為識別的特點,要既普遍又獨特
隨著電腦運算效能的演進、行動設備普及化,自動化的「生物識別系統」──尤其是指紋和語音識別,早已在近十年被廣泛使用。不過,即使指紋、語音等生物資訊已逐漸普遍,值得留意的是:除了一般性消費服務的應用之外,銀行、金融業者也嘗試將各種生物識別技術,導入銀行服務應用之中。
比如歐洲銀行業管理局 (European Banking Authority),在 2018 年發布的《EBA Report on the Prudential Risks and Opportunities Arising for Institutions from Fintech》報告中,便提到「生物識別」技術在「身分識別」的功能上,須具備幾個特點:
- 普遍性:確保每個人都有用來識別的特徵。
- 獨特性:特徵在個體間有所差異。
- 持久性:同個體的該項特徵不會隨時間有太大改變。
- 可收集性:與特徵獲取或測量方式的難易度有關;愈難取得則識別效果愈差。
- 規避難度:規避難度會影響技術的安全性和可靠性。
- 社會接受度:客戶對生物辨識的的接受或抵抗會嚴重影響方法的使用。
符合這些條件的生物特徵,大致上可以分成指紋、語音、虹膜、臉部等「外部生理特徵」以及「內部生理特徵」,例如靜脈、心跳。其中,又因為指紋辨識具有方便、快速、成本低廉的特性,所以無論是實體銀行和行動銀行都很常見到指紋辨識的應用,或者藉由指紋辨識,來擴大服務情境的內容。
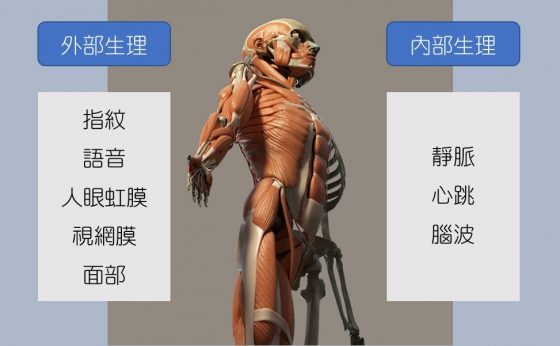
生物特徵雖然能夠鎖定個人的獨特性,但也並非無所不能。以如今已成熟化的指紋辨識來看,指紋這項生理特徵的應用,也有幾項明顯的侷限性。首先,並非所有人的指紋都能夠被機器識別;其次,指紋的辨識與取得,目前仍必須直接仰賴特定的臨場感應器;再次,感應器上的指紋印痕也具有被有心人士複製的風險。
整體來說,指紋辨識技術仍有可靠性 (reliability) 不足,以及使用臨場設備的限制,因此,除了指紋辨識之外,銀行與金融業者也積極投入其他生物辨識的應用。
遠端身分識別、消費者體驗需求,帶動人臉辨識技術導入服務
衡量生物識別可靠性的指標分為兩類,分別是錯誤接受率 (False Acceptance Rate, FAR) 及錯誤拒絕率 (False Rejection Rate, FRR)
- 錯誤接受率:非法使用者被機器錯誤接受、通過認證的比率。
- 錯誤拒絕率:合法使用者被機器錯誤拒絕的比率。
這兩個比率太高都會產生負面影響,前者高意味著安全性不佳,後者高則影響使用意願。
同樣在歐洲銀行業管理局 (EBA) 報告中,比較了不同的生物辨識技術,發現到:在一般的情況之下,人臉辨識與語音識別的錯誤接受率 (FAR) 較高,指紋、虹膜和視網膜識別則較低,但確切數據會隨著不同使用目的而變動。正因如此,現在的人臉辨識技術尚未普遍成為銀行金融服務的主要導入技術。

即使如此,仍可以看到部分銀行金融服務業者,比如匯豐銀行、新加坡華僑銀行等,近年開始嘗試將人臉辨識,導入於相關服務中。人臉辨識技術雖然尚未成熟,卻讓各大銀行願意花費昂貴成本和風險引進,倘若我們彙整這些業者的服務論述,大致可歸納為兩點:
- 提升安全防護:只有傳統密碼的情況下,一旦客戶的卡片密碼被不肖人士取得,可能就會造成客戶損失。然而若增加人臉辨識系統在 ATM 等設備上作為防護,不僅會使得盜領難度大增,銀行也能夠「即時」獲得警訊,未來在合理的法律規範下,還可以和警方合作,用來打擊犯罪。即時性防護,對於注重安全性的金融機構而言,人臉辨識提供的保護功能,會是最大的投入誘因。
- 增加客戶體驗、吸引客群:在網路銀行普及的同時,由於業務上仍有部分限制,實體據點的存在還是有其必要性。因此,透過人臉辨識提供優良的體驗以吸引客戶,對銀行來說會是一項誘因,例如 Pepper 機器人、Video Teller Machine、迎賓互動牆等等。這也意味著:銀行業者在因應行動服務等需求的同時,會需要非臨場、遠端臨場的身分識別技術。而在智慧型手機的鏡頭效能不斷增進的趨勢下,人臉在裝置上的映照與投射已成消費者最熟悉的使用習慣之一。



倘若我們觀察現有的案例,可以發現銀行業者對於人臉辨識的應用導入,包括手機銀行登入、臨場的身分識別等。而從消費者使用經驗的層面來看,則可進一步分為兩種類型:
- 「主動辨識」:可在辨識目標(消費者)無知覺的情況下運作,常被用來監控特定範圍內的動態目標
- 「被動辨識」:需經過辨識目標主動觸發,系統才會開始運作,而由於目標是靜態的,所以受到環境因素干擾的程度會較低,使辨識可靠性提升
但無論何種應用服務(如:登入手機 APP 使用行動銀行,或是在櫃檯協助行員辦理金融服務)對「可靠性」的需求都被視為銀行服務的核心,其中,又以被動辨識中涉及到的線上登入、支付等服務對於系統可靠性的需求最高,因為稍有不慎便可能造成金錢損失,或將個人資料外洩。
- 註:銀行休息室的主動辨識功能,其需求是截然不同的,休息室使用人臉辨識的目的,是在客戶沒有意識到的情況下提供貼心的接待服務,對銀行來說偶爾辨識錯誤的影響不大,這種情況下主動的人臉辨識反而比較適合。
然而,若就現有的案例來看,目前在銀行服務中,單獨使用人臉辨識作為身份認證的服務仍有限,使用安全性需求高的功能,仍然還是會搭配「密碼」輸入,人臉辨識只作為多重認證的一環。但可以確定的是,未來人臉辨識能否完全取代其他身分認證的方式,甚至成為主流認證方式,辨識的可靠性會是一個很重要的關鍵。
人臉辨識導入金融服務的爭議與挑戰
使用人臉辨識革新金融服務的同時,銀行要考量的不僅僅是技術的使用方式、成本等等,還要注意伴隨著創新而來的爭議與挑戰,接下來將分別說明可能遇到的問題。
技術可靠性仍有待提升,且需要有在地特徵的分析模型

對銀行來說,是否採用人臉辨識技術,或者更進一步決定技術運用的方式及程度,其中最大的關鍵在於可靠性,這些問題包括──究竟人臉辨識系統能不能準確分辨出長相相近的不同用戶?膚色與性別是否會導致辨識錯誤機率提高?
以目前當紅的 Face ID 為例,Apple 坦言雙胞胎和 13 歲以下的兒童用戶,辨識錯誤機率的確較高,並且建議他們使用密碼驗證,坊間也可看到民眾成功騙過系統的案例。學術研究方面,Buolamwini 與 Gebru 在 2018 所發表的「Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification」一文中針對 3 款人臉辨識 API 進行測試,結果發現性別和膚色均會對準確度造成影響,可能原因除了膚色和燈光影響資料擷取外,資料收集時的偏誤也會降低人工智慧模型的判斷能力。假如資料中的白人男性偏多,模型對於白人男性的訓練量足夠,會有較佳的辨識能力,而相對的,其他特徵的使用者就比較容易出現誤判。
如果是用於一般的消費性電子產品,目前的人臉辨識技術對於提供用戶良好的使用體驗或許綽綽有餘,然而金融業對於安全的要求極高,在進一步提升技術可靠性之前,人臉辨識技術仍無法全面取代密碼作為主流驗證方式。
臉部特徵作為個人資料,如何兼顧資料安全性

想要將人臉辨識導入金融服務,那麼生物資訊的蒐集是無法避免的,因此,個資法的規範範圍是否影響技術的使用?這是銀行必須審慎評估的。這也意味著:除了技術層面以外,法律規範也是銀行引進服務前需要思考的。
首先,台灣的個人資料保護法中規定,無論公務機關或非公務機關,如要在未取得當事人同意的情況下蒐集資料,則需要基於執行法定職務或義務等必要情況,並且處理與利用資料同樣只能在法律規範的幾種特例下所使用,例如為了公共利益或是學術研究。
國外的法律規範更嚴謹,歐盟號稱史上最嚴的個資法 GDPR (General Data Protection Regulation) 於 2018 年 5 月 25 日開始實施,適用的範圍相當廣泛,不僅是歐盟境內,只要客戶、員工、供應商、政府機關等和歐盟公民相關就會受到 GDPR 的規範。受保護的資訊囊括了一切個人數據,從基本資料、宗教信仰、政治立場、網路瀏覽紀錄到指紋、虹膜、面部等生物特徵都在範圍內。這些法律上的限制意味著銀行引進人臉辨識前,必須謹慎評估使用情境是否合法,避免在追求便利服務的同時帶來更多額外的風險及成本。
技術不成熟引發的社會爭議

人臉辨識的運用也引發了敏感的社會爭議。英國倫敦、南威爾斯等幾個地區的警方,自 2017 年開始在一些節慶、比賽或是流量大的十字路口使用人臉辨識系統,系統即時辨認鏡頭前是否出現和警方持有照片一致的面孔,若配對成功則會發出警報。
然而,其結果不盡理想,依據目前的測試結果,警報超過九成都是錯誤的,這讓英國民間的公民自由組織 Big Brother Watch 非常不滿,認為這項不準確又昂貴的系統,對於抓捕真正的罪犯幫助有限,反而會造成無辜人民的自由受到侵害。同樣的問題也可能出現在銀行,如果銀行逕自使用人臉辨識系統分辨客戶,而未經過所有出現在鏡頭前的人同意,不論結果是否準確恐怕都難避免爭議。
整體而言,依據歐洲銀行業管理局 (European Banking Authority) 的觀點來看,人臉辨識的技術仍有相對較高的錯誤接受率 (False Acceptance Rate, FAR),換言之,對於銀行金融此種需要有高度可靠性、安全性的服務場域來說,技術仍然未能滿足,因此在目前,人臉辨識仍屬於多重辨識的一種(如搭配密碼、人臉資訊等)。
但相對於虹膜、指紋、靜脈等生物辨識技術來說,人臉辨識擁有較高的遠端臨場特性,也就是使用者可以在非臨場情境中使用銀行金融業者所提供的服務,確實在行動服務普及化趨勢之下,是業者願意投入的主要誘因。此外,倘若相關技術可以取得更多的在地化資料模型,並結合深度學習 (Deep Learning) 等技術,在未來仍可以降低錯誤識別的機率。
不過,其實人臉辨識能否成功導入於銀行金融服務,其最核心的問題仍在於:消費者是否信賴?這個問題所包含的個人資料保護,以及生物資訊第三方使用的正當性,才是這個議題最需要解決的課題。
一個只需要刷臉就可以登入的銀行帳戶,你的想法是甚麼呢?
參考文獻
- Buolamwini, J., & Gebru, T. (2018). Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification. Proceedings of Machine Learning Research 81, (pp. 1-15).
- EU GDPR. GDPR Key Changes. Retrieved 11 23, 2018, from EU GDPR.ORG: https://eugdpr.org/
- European Banking Authority. (2018). EBA Report on the Prudential Risks and Opportunities Arising for Institutions from Fintech. European Banking Authority.









































{kind=link}