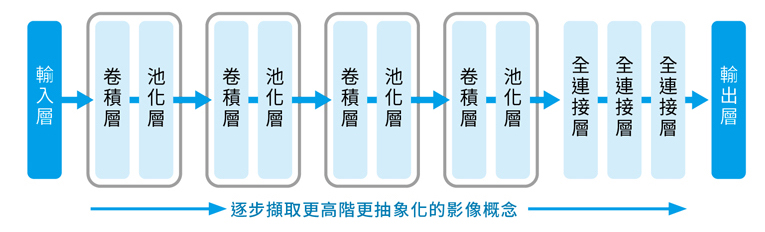
當前,像是企業、醫院、學校內部的伺服器,個人電腦,甚至手機等裝置,都可以成為「邊緣節點」。當數據在這些邊緣節點進行運算,稱為邊緣運算;而在邊緣節點上運行 AI ,就被稱為邊緣 AI。簡單來說,就是將原本集中在遠端資料中心的運算能力,「搬家」到更靠近數據源頭的地方。
-----廣告,請繼續往下閱讀-----
那麼,為什麼需要這樣做?資料放在雲端,集中管理不是更方便嗎?對,就是不好。
當數據在這些邊緣節點進行運算,稱為邊緣運算;而在邊緣節點上運行 AI ,就被稱為邊緣 AI。/ 圖片來源:MotionArray
第一個不好是物理限制:「延遲」。 即使光速已經非常快,數據從你家旁邊的路口傳到幾千公里外的雲端機房,再把分析結果傳回來,中間還要經過各種網路節點轉來轉去…這樣一來一回,就算只是幾十毫秒的延遲,對於需要「即刻反應」的 AI 應用,比如說工廠裡要精密控制的機械手臂、或者自駕車要判斷路況時,每一毫秒都攸關安全與精度,這點延遲都是無法接受的!這是物理距離與網路架構先天上的限制,無法繞過去。
第三個挑戰:系統「可靠性」與「韌性」。 如果所有運算都仰賴遠端的雲端時,一旦網路不穩、甚至斷線,那怎麼辦?很多關鍵應用,像是公共安全監控或是重要設備的預警系統,可不能這樣「看天吃飯」啊!邊緣處理讓系統更獨立,就算暫時斷線,本地的 AI 還是能繼續運作與即時反應,這在工程上是非常重要的考量。 所以你看,邊緣運算不是科學家們沒事找事做,它是順應數據特性和實際應用需求,一個非常合理的科學與工程上的最佳化選擇,是我們想要抓住即時數據價值,非走不可的一條路!
邊緣 AI 的實戰魅力:從工廠到倉儲,再到你的工作桌
知道要把 AI 算力搬到邊緣了,接下來的問題就是─邊緣 AI 究竟強在哪裡呢?它強就強在能夠做到「深度感知(Deep Perception)」!
-----廣告,請繼續往下閱讀-----
所謂深度感知,並非僅僅是對數據進行簡單的加加減減,而是透過如深度神經網路這類複雜的 AI 模型,從原始數據裡面,去「理解」出更高層次、更具意義的資訊。
以研華科技為例,旗下已有多項邊緣 AI 的實戰應用。以工業瑕疵檢測為例,利用物件偵測模型,快速將工業產品中的瑕疵挑出來,而且由於 AI 模型可以使用同一套參數去檢測,因此品管上能達到一致性,減少人為疏漏。尤其在高產能工廠中,檢測速度必須快、狠、準。研華這套 AI 系統每分鐘最高可處理 8,000 件產品,替工廠節省大量人力,同時確保品質穩定。這樣的效能來自於一台僅有膠囊咖啡機大小的邊緣設備—IPC-240。
這樣的效能來自於一台僅有膠囊咖啡機大小的邊緣設備—IPC-240。/ 圖片提供:研華科技
此外,在智慧倉儲場域,研華與威剛合作,研華與威剛聯手合作,在 MIC-732AO 伺服器上搭載輝達的 Nova Orin 開發平台,打造倉儲系統的 AMR(Autonomous Mobile Robot) 自走車。這跟過去在倉儲系統中使用的自動導引車 AGV 技術不一樣,AMR 不需要事先規劃好路線,靠著感測器偵測,就能輕鬆避開障礙物,識別路線,並且將貨物載到指定地點存放。
當硬體資源有限,大模型卻越來越龐大,「幫模型減肥」就成了邊緣 AI 的重要課題。/ 圖片來源:MotionArray
模型剪枝(Model Pruning)—基於重要性的結構精簡
建立一個 AI 模型,其實就是在搭建一整套類神經網路系統,並訓練類神經元中彼此關聯的參數。然而,在這麼多參數中,總會有一些參數明明佔了一個位置,卻對整體模型沒有貢獻。既然如此,不如果斷將這些「冗餘」移除。
這就像種植作物的時候,總會雜草叢生,但這些雜草並不是我們想要的作物,這時候我們就會動手清理雜草。在語言模型中也會有這樣的雜草存在,而動手去清理這些不需要的連結參數或神經元的技術,就稱為 AI 模型的模型剪枝(Model Pruning)。
-----廣告,請繼續往下閱讀-----
模型剪枝的效果,大概能把100變成70這樣的程度,說多也不是太多。雖然這樣的縮減對於提升效率已具幫助,但若我們要的是一個更小幾個數量級的模型,僅靠剪枝仍不足以應對。最後還是需要從源頭著手,採取更治本的方法:一開始就打造一個很小的模型,並讓它去學習大模型的知識。這項技術被稱為「知識蒸餾」,是目前 AI 模型壓縮領域中最具潛力的方法之一。
知識蒸餾(Knowledge Distillation)—讓小模型學習大師的「精髓」
想像一下,一位經驗豐富、見多識廣的老師傅,就是那個龐大而強悍的 AI 模型。現在,他要培養一位年輕學徒—小型 AI 模型。與其只是告訴小型模型正確答案,老師傅 (大模型) 會更直接傳授他做判斷時的「思考過程」跟「眉角」,例如「為什麼我會這樣想?」、「其他選項的可能性有多少?」。這樣一來,小小的學徒模型,用它有限的「腦容量」,也能學到老師傅的「智慧精髓」,表現就能大幅提升!這是一種很高級的訓練技巧,跟遷移學習有關。
但是!即使模型經過了這些科學方法的優化,變得比較「苗條」了,要真正在邊緣環境中處理如潮水般湧現的資料,並且高速、即時、穩定地運作,仍然需要一個夠強的「引擎」來驅動它們。也就是說,要把這些經過科學千錘百鍊、但依然需要大量計算的 AI 模型,真正放到邊緣的現場去發揮作用,就需要一個強大的「硬體平台」來承載。
-----廣告,請繼續往下閱讀-----
邊緣 AI 的強心臟:SKY-602E3 的三大關鍵
像研華的 SKY-602E3 塔式 GPU 伺服器,就是扮演「邊緣 AI 引擎」的關鍵角色!那麼,它到底厲害在哪?
三、可靠性 SKY-602E3 用的是伺服器等級的主機板、ECC 糾錯記憶體、還有備援電源供應器等等。這些聽起來很硬的規格,背後代表的是嚴謹的工程可靠性設計。畢竟在邊緣現場,系統穩定壓倒一切!你總不希望 AI 分析跑到一半就掛掉吧?這些設計確保了部署在現場的 AI 系統,能夠長時間、穩定地運作,把實驗室裡的科學成果,可靠地轉化成實際的應用價值。
-----廣告,請繼續往下閱讀-----
研華的 SKY-602E3 塔式 GPU 伺服器,體積僅如後背包大小,卻能輕鬆支援語言模型的運作,實現高效又安全的 AI 解決方案。/ 圖片提供:研華科技