

- 文/大家的語言學│在科技業闖蕩的語言學人,有感於社會大眾對於語言學的誤解,因此致力於將語言學知識科普化,帶領你發掘生活中無所不在的語言學大小事
最近和幾位準媽媽聊天,她們不約而同的都提到:醫生建議在孕期的後期,可以試著和肚子裡的寶寶說話,因為在這個時期,寶寶的耳朵已經聽得到外面的聲音了。作為辛苦的母親,能夠和肚子裡的寶寶互動,相信一定是非常欣慰的一件事。
然而,令人好奇的是,寶寶和外界隔著一層肚皮,即使聽得到聲音,真的能算是開始接觸語言了嗎?尤其是寶寶還在肚子裡,以目前的科技,無法直接探測到寶寶對語言的反應。儘管如此,學者專家們仍透過其他的實驗方式,試圖探討「嬰幼兒何時開始學習母語」這件事情。

感知磁吸效應:自動歸納出近似母語的發音
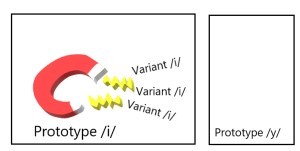
早在 1991 年,知名語言學家 Patricia Kuhl 就已經提出了感知磁吸效應 (perceptual magnet effect)。該效應認為,人們對於母音的感知,會以一個原型(Prototype)為基準。舉例來說,當說到中文的母音 /i/ 時,中文的母語者心中就會有一個標準,認為 /i/ 在感知上就應該是這樣唸、聽起來就應該是這樣。有趣的是,與這個原型音鄰近的音,母語者會自動歸納成同一個範疇,也就是說,每個人發的 /i/ 在聲學物理性上或許略有差異,但人們在感知上會自動忽略這些差異。
語言學家運用電腦合成技術,說明感知磁吸效應的存在。我們舉英語的 /i/ 為例,首先,用電腦合成一個原型的 /i/(Prototype),並創造出 32 個與原型 /i/ 鄰近的音(Variants)。接著,找來英語母語者為這 33 個音評分,聽聽看哪一個 /i/ 是他們認為最符合原型 /i/ 的音,並在一個 7 分量表中給予評分, 7 分代表是最符合原型的音, 1 分代表最不符合原型的音。
研究結果顯示,越接近原型的音,受試者給予的分數就越高,而離原型越遠的音,給予的分數就越低。因此,原型的音就像是一塊磁鐵(magnet),會把同一個範疇的音吸取過來,人們會將原型音及其範疇的音視為同一個音。原型音在兒童語言習得中,扮演重要的角色,能夠幫助兒童過濾其所聽到的聲音,哪些是原型音,哪些是可以歸納在原型音裡的變體音(variants),哪些是非原型音(也就是不屬於自己母語的音)。
六個月大的嬰兒已能分辨母語和非母語的發音
有了感知磁吸效應為基礎,語言學家 Patricia Kuhl 等人,進一步設計了一項實驗,測試六個月大的寶寶,是否在接觸母語短短六個月的時間,就已經開始能辨別母語和非母語的母音。實驗找來英語母語及瑞典母語寶寶,測試的音為英語原型母音 /i/(對瑞典語來說,/i/不是典型母音)和 32 個變體音,以及瑞典語的母音 /y/(似中文的ㄩ,對英語來說,/y/ 不是原型母音)和 32 個變體音。
實驗結果顯示,這兩個國家六個月大的寶寶,已經反映了顯著的感知磁吸效應。舉英語為例,六個月大的嬰兒會把原型 /i/ 和其變體音,歸納在同一類,但是,對於不屬於英語母語的 /y/ ,則會歸納在另一個類別。瑞典語的嬰兒則是會把原型 /y/ 及其變體音,歸納在同一類,但是不屬於瑞典語原型的 /i/ ,則被歸納在不同的類別。

有可能比六個月還早嗎?
延續上述的實驗結果,語言學家們心想:六個月已經是最早的嗎?有沒有可能在六個月之前就出現感知磁吸效應?因此,包含語言學家 Patricia Kuhl 及其他心理學家的團隊,設計了一個特別的實驗,實驗的假設是,如果剛出生的寶寶就有感知磁吸效應,換句話說,已經能區分母語和非母語的母音,我們或許就能推測,寶寶早在媽媽的肚子裡時,就開始學習語言了。
實驗找來了二組受試者,其中一組是英語母語的新生兒,另一組則是瑞典語母語的新生兒,兩組分別都有 40 位受試者。新生兒平均出生 32.8 小時(分布從 7~75 小時);實驗所測試的音,延續上述的實驗,包含英語原型母音 /i/ 和 16 個變體音,以及瑞典語的母音 /y/ 和 16 個變體音。
實驗過程中讓受試的新生兒帶上耳機,播放上述英語及瑞典語的母音音檔,並讓新生兒吸吮奶嘴;奶嘴上安裝感應器,並連接電腦,記錄新生兒吸吮奶嘴的次數。下圖為實際的實驗照片:
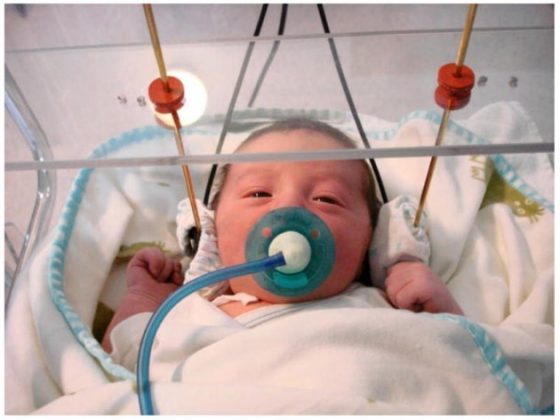
實驗人員根據所記錄下來的新生兒吸吮奶嘴的次數,經統計發現,當英語為母語的新生兒聽到瑞典語的 /y/ ,吸吮奶嘴的次數會多於聽到英語的 /i/ ;當瑞典語母語的新生兒聽到英語的 /i/ ,吸吮奶嘴的次數則明顯多於聽到自己母語 /y/ 。
嬰兒在媽媽的肚子裡,就已開始習得語言
根據實驗結果,學者提出幾個值得討論的重點:
- 新生兒吸吮奶嘴的次數,反應了他們對於外在刺激是否感到新奇。若是對於外在刺激感到習以為常,反應會比較平淡;若是對於外在刺激感到新奇,反應會較為明顯,吸吮奶嘴的次數會比較多。
- 新生兒對於自己的母語,不論是原型母音或是其變體音,沒有明顯的反應起伏,但對於不是自己的母語,不論是原型母音或其變體音,吸吮奶嘴的次數增多,反應較為明顯。有趣的是,這項結果也說明感知磁吸效應可能早在新生兒階段就已存在。
- 實驗中的新生兒平均剛出生30幾個小時,因此,對於實驗所呈現出來的結果,我們推判寶寶在母親的肚子裡,就已經開始接收到聲音,並開始對聲音做歸納分類。當還在媽媽肚子裡的時候,就知道哪些母音是屬於自己的母語,因此一出生,即便只有30幾個小時,已經能區分母語和非母語的母音了。
當然,實驗只測試了兩個語言,未來還可持續的擴充研究範圍。但無論如何,已經讓我們知道,語言習得可能比我們想像的還要早很多,早在還沒有呱呱墜地之前,寶寶就已經做好了準備,開始為語言發展之路熱身。
參考資料
- Kuhl, Patricia K. Human adults and human infants show a “perceptual magnet effect” for the prototypes of speech categories, monkeys do not. Perception & Psychophysics, 1991; 50: 93-107.
- Kuhl PK, Williams KA, Lacerda F, Stevens KN, Lindblom B. Linguistic experience alters phonetic perception in infants by 6 months of age. Science. 1992;255:606–608.
- Moon, C., Lagercrantz, H., & Kuhl, P. K. Language Experienced in Utero Affects Vowel Perception after Birth: A Two-Country Study. Acta Paediatrica, 2013; 102: 156-160.
本文轉載自〈大家的語言學〉,原文標題〈我們是從什麼時候開始學習母語?〉








































