- 採訪編輯|柯旂 美術編輯|張語辰
當藥物設計碰上電腦運算──節省成本又降低風險
中研院應用科學研究中心、生物醫學科學研究所合聘的林榮信研究員,同時也是台大醫學院藥學系與長庚大學工學院的合聘教授,與團隊以分子動力學、統計物理、結構生物等學問為法,藉由電腦的高速運算能力,模擬藥物分子如何與體內的標靶分子作用。此舉不但能縮減藥物研發的時間及成本,也有助了解藥物在人體中的生化反應,降低藥害風險。

現代的藥物研發流程,可簡要地敘述為以下步驟:1. 先透過大規模基因體學、與蛋白質體學實驗,找到可成為藥物的分子及治療標靶 → 2. 解出其分子結構 → 3. 依此分子結構來設計合成藥物化合物。雖然這過程幾行字就打完,但不僅需要生物醫學、藥理學、生物化學、藥物化學等跨領域團隊投入研究,也耗費超乎想像的金錢與時間。 一種藥物,從實驗室研發、臨床試驗、爾後上市的時程十分漫長,政府與科學家們皆在思考如何加速此流程,減少研發資源的錯置,並協助更多民眾緩於苦痛。
我們使用的藥物之所以有藥效,是因為藥物分子與體內的標靶分子(大多是蛋白質),產生交互作用所致。
以往主要是透過生物化學實驗、或生物物理實驗來了解此交互作用,但是這些實驗方式,並不能提供「藥物分子」與其作用的「標靶生物分子」之間作用的動態關係,而且大部分的實驗方法,無法提供原子尺度的資訊,因此對藥物設計的直接用處有限。要知道,許多藥物分子只要差了一個原子,其藥效就有可能截然不同。此外,這些藥物開發需要的實驗所費不貲,一個錯誤的決策,便會導致研究進度的推遲與研究資源的耗損。 有鑑於此,林榮信團隊的著眼點為:如果能夠在藥物研發初期,先利用電腦模擬藥物開發所選定的「標靶分子」,來快速篩選出有機會的「候選藥物分子」,高精度計算兩者相遇後會如何作用與運動,就能很大程度地協助實驗團隊少走冤枉路,減少藥物開發失敗耗損的人力、物力與光陰。 要達到這個目標,不僅有賴電腦逐年進步的高速運算能力,以及計算物理、化學界對計算方法的精進,也有賴科學家對於生物分子結構的了解。

藥物設計核心概念:蛋白質結構會隨時間改變
Q:藥物設計,最重要的觀念是?
藥物設計不能只停留在「結構」層次,也需把蛋白質的「動態」考慮進去。
要模擬藥物在原子、分子層次的藥理作用反應,需先得到會和藥物分子作用的體內蛋白質分子、或其他生物分子的結構。 雖然有蛋白質結構資料庫 (Protein Data Bank) 提供了許多利用 X-ray 結晶學、核磁共振學、低溫電子顯微術所決定出來的高解析度分子結構,但該資料庫裡的分子結構實質上仍只是模型。舉例來說,不可能分子裡面每個原子的 X, Y, Z 位置都真的固定在那裡,我們知道一般實驗條件中,蛋白質是相當動態的。因此,這需要有結構生物學的知識,來理解蛋白質結構資料庫中「分子結構」的真實意義。

我們做藥物設計,相當需要和結構生物學的團隊合作。我們以分子動力學 (molecular dynamics) 模擬出來的蛋白質動態資訊,需要透過進階的生物物理實驗,間接驗證所得到的動態訊息,例如:帶有時間解析度的 X 射線晶體學、甚至是自由電子雷射。不過,這些實驗技術雖持續有進展,仍然進展得十分緩慢。 學術研究有趣的現象是,學術界像個很大的生態環境,有些人會進來、有些人會出去;進來的時間點不同,看到的世界也很不同;而每個人獲得與提供的資訊都不太一樣,每次進來的人都會留下不同程度的進展。像這樣逐步推進,從歷史來看,通常要用二、三十年或以上的時間尺度,才比較看得出很突破性的研究進步。
用深度學習預測藥物和標靶分子反應活躍度
Q:目前實驗室的研究方向?
藥物分子如何與體內的生物分子結合、交互作用,是我們研究的核心主題。
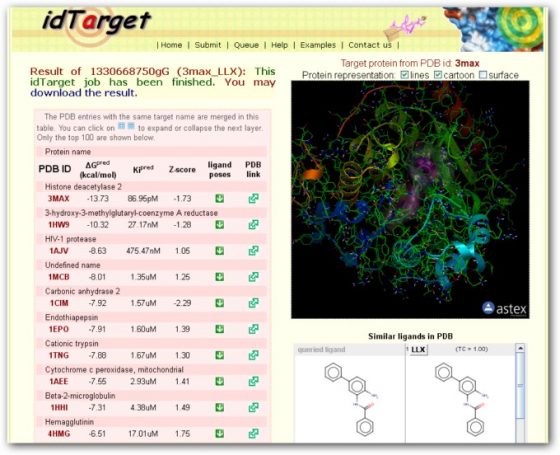
例如,若要開發天然物 (Natural product) 製成現代西方醫學的藥物,過往要從古籍或文獻去看某種草藥或複方有什麼可能的活性,接著萃取、純化出有效化合物之後,要再透過生化實驗測試其生物活性,這是一個很漫長的測試過程,期間也需要很多的推測。 這幾年來,我們發展出計算藥物分子和不同蛋白質系統反應的程式,並建構成 idTarget 「藥物標靶預測平台」,開放給大家運用,方便其他研究人員探索藥物可能的作用標靶。 我們的想法是,要多多重視、運用結構生物學近二十年的大量結構資料,配合藥物分子和蛋白質結合的自由能計算,先找出藥物分子和那些蛋白質較有可能作用。我們知道,化學上一個反應會不會發生、或多容易發生,可以由自由能來預測。因此,生物系統上快速、準確的自由能計算,一直是我們實驗室的核心基礎課題。我們最近也運用深度學習,來開發自由能計算的方法。
我們實驗室另一個重點,是將傳統常見的藥材以科學方法再研究,這也是目前醫藥研究的重要方向之一。 例如,本草綱目記載「天麻」具有安神與鎮定的效果,而現職中國醫藥大學的林雲蓮教授團隊發現,天麻中有個叫作 T1-11 的新的分子,與過去較熟知的天麻素有很不同的作用;另一方面,中研院生物醫學研究所的陳儀莊博士團隊則發現, T1-11 分子能用於治療亨丁頓舞蹈症。基於這些研究發現,我們實驗室透過電腦設計適合的藥物分子,並由台大化學系的方俊民教授團隊將藥物合成出來。這就是一種新藥開發的跨領域合作方式。
不受限於科系,從高中點滴為未來鋪路
Q:您以前讀物理,怎麼會跨領域至藥物設計?
我想要研究藥物設計,不是某天靈機一動決定的,而是做研究的路上漸漸地朝這方向發展。 一開始,也就是讀台大物理系時,某次導生聚會中,那時的導師陳永芳教授對我們說:「21 世紀的物理,應該是生物物理 (Biophysics) 」,那次以後我心中就一直有個想法,覺得日後研究「生物物理」會是個不錯的方向。 後來,大三時開始發現統計力學 (Statistical mechanics) 是很有意思的領域,因為這門學問關注如何理解所謂的複雜系統。很多物理是關注比較單一的系統,例如原子鑽進去有夸克;但有另一個物理研究方向,是去看如何處理很大、很複雜的問題。現在我研究藥物設計,也是關注體內的生物分子和藥物分子之間,整個系統如何產生複雜的反應。 時間點再往前一點回顧,我在建中時很幸運地得以參加第一屆的「北區高中理化學習成就優異學生輔導實驗計畫」,每兩個禮拜的週末,要從台北坐車去清華大學受訓一整天。當時由清華大學物理系、化學系的各六位老師(包含:李怡嚴、陳信雄、王建民、古煥球、劉遠中、張昭鼎、儲三陽等教授),教我們很多不是高中課本裡的知識。比較早接觸這些大學才能學到的物理和化學,我們就能提早思考將來有興趣的是什麼,因為那時候高中還沒分系,沒有框架綁住自己,這算是蠻難得的人生經驗。
不同的課程,會提供不一樣的世界,如果沒有接觸,就不會知道有那種思考的存在。
但是,我第一次在研究上真的從事「生物物理」相關的題目,已經是 1996 年到德國于利希研究院 (Forschungszentrum Jülich) 讀博士班的時候了。在這之前,我在台大物理碩士班的研究領域是計算物理 (Computational physics);到了德國,我的指導教授 Artur Baumgaertner 原本是研究高分子物理,其博士後的指導教授是著名的 Prof. Flory,他那時已經跨足在生物物理做了十年左右的研究,問我對生物物理有沒有興趣?我一聽也覺得不錯,便一頭栽進去了。那時研究的題目,是探討像蜂毒蛋白這樣的多胜肽大分子,究竟是透過什麼物理機制穿過細胞膜這樣的屏蔽。 德國的于利希研究院 (Forschungszentrum Jülich) 的型態很像中研院,由三十幾個不同的研究所組成,擁有超過 5000 位研究員,在廣大的校園內,走幾步就到另一個所,非常容易做跨領域合作。這裡在當時有全歐洲最大的超級電腦中心,因此對我的研究非常有幫助。我 2007 年回去訪問,他們剛添置了 72 座 IBM 剛推出的 Blue Gene P,因此我與同事在這新建置的機房留影。

2000 年博士畢業後,我在美國加州大學聖地牙哥分校的霍華休斯醫學研究所工作,2001 年初,有天指導教授 J. Andrew McCammon 發了一封郵件到實驗室群組,問:「我有個新的藥物計算方法的初步構想,有沒有人想開發這個方法?」之前我就希望我的研究成果能有較大的產業價值,因此很快就回應,而我也成為這個方法開發的小組領導人。 當時的藥物計算程式,剛得到一個很大的進展,但仍只考慮蛋白質等生物分子為一個靜態的結構。我們在那時首度將「藥物設計」的計算與「分子動力學」結合,這剛好是我德國博士班時的專業,我又剛好具備許多寫程式及平行計算的經驗,就將所需要的不同計算工具整合在一起。
無所畏懼擁抱跨領域新知,藥物設計一點也不難
Q:「藥物設計」很難學嗎?
我發現其實現在學生們學習速度非常快,一旦他決定想進到這個領域,便會盡其所能去學,只是目前國內還沒有適當的藥物設計課程,提供完整的訓練。 因此,2018 年 3 月我們在中研院舉辦了「計算藥物設計方法與應用的前沿進展」工作坊,除了回顧藥物設計的重要文獻,介紹藥物設計的程式工具,也選了一些藥物分子與其作用的蛋白質分子讓學生們上機演練,了解其中的計算細節、眉眉角角。 如果對這領域有興趣,千萬不要認為看起來很難,想等到研究所再來了解。其實越早學習、並習慣接觸跨領域的學科,絕對是事半功倍。 延伸閱讀:
- 林榮信的個人網頁 (中研院應用科學研究中心)
- 林榮信的個人網頁 (中研院生物醫學科學研究所)
- 〈挑戰神奇子彈—高效能計算與藥物設計〉,作者:林榮信
- 〈中藥西用新魔彈〉,作者:吳美枝
- 【科學人特別企畫】高速計算模擬,開發新藥最佳利器
- 【歷史講座資訊】計算藥物設計方法與應用的前沿進展
本著作由研之有物製作,原文為《高效能計算藥物設計:更精準的新藥開發》以創用CC 姓名標示–非商業性–禁止改作 4.0 國際 授權條款釋出。
本文轉載自中央研究院研之有物,泛科學為宣傳推廣執行單位
 在網站上看不過癮?研之有物出書啦! 《研之有物:穿越古今!中研院的25堂人文公開課》等著你來認識更多中研院精彩的研究。
在網站上看不過癮?研之有物出書啦! 《研之有物:穿越古今!中研院的25堂人文公開課》等著你來認識更多中研院精彩的研究。