



如果上圖有打中你,本文整理 2017 中央研究院 AI 月系列活動中,國內外專家分享的深度學習思維與應用。希望能讓深度學習成為各位小智的寶可夢,在人工智慧這條路上,走出樂趣與成就感。
深度學習:讓電腦長神經,教它判斷決策
1960 年代起,科學家就試著透過各種機器學習技術,教電腦擁有人工智慧,例如會下西洋跳棋的電腦程式。但這跟現在的 AlphaGo 相比似乎不算什麼?這部分拜賜於電腦運算效能大幅提升、大量供訓練使用的資料,以及深度學習技術近幾年的突破性進展。

從上圖可以看到,這是深度學習與傳統機器學習技術的最大差別:電腦有了四通八達的神經網路!透過層層非線性函數組成的神經網路、及精心規劃的權重訓練過程,電腦學會在未曾經驗過的情境下做出最適當的反應。
訓練深度學習模型就像教小孩,給予足夠的人生經驗,透過神經網路學習,讓電腦未來自己判斷怎麼做比較好。
若將深度學習比喻為手拉坏,陶土就是資料,陶碗成品是電腦自動找出來的函數(function),而目前有的「拉坯機」為 TensorFlow、PyTorch、Microsoft CNTK、Keras 等程式庫,其中 Keras 算是 TensorFlow 的官方介面,比較容易上手、適合初學者。而核心處理器 GPU 就像拉坯機的電源,若是 GPU 強大又穩定,深度學習的運算速度會更快。但最重要的是,身為手拉坏師傅的你,要如何教導電腦這位學徒。
「深度」在於神經網路的層層結構
小時候爸媽會拿著圖書,教你辨認 “1″ ,”2″, “3″ 每個數字的長相,若要教電腦辨識數字 “2” ,要先從該影像一個個像素 (pixel)開始分析,經由層層層層層層層層層層層層層層層層函數組成的神經網路運算,最後判斷出這個影像「最可能」為數字 “2” 。
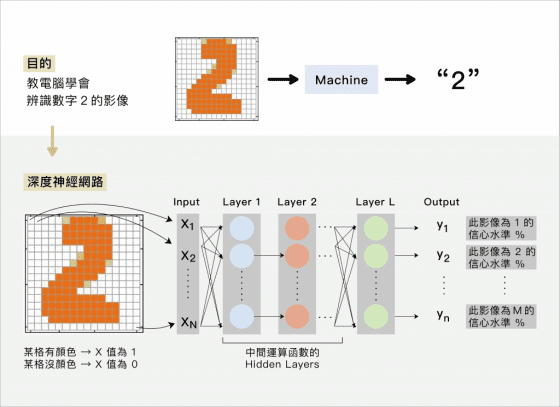
為了達到較高的信心水準,有兩個關鍵:給與足夠的訓練資料,以及設計出優秀的神經網路。
深度學習的神經網路結構,該長什麼模樣?目前主流作法有 CNN(Convolutional Neural Network)、RNN(Recurrent Neural Network)和 GAN(Generative Adversarial Network)等等 ,各有信徒支持的優點。
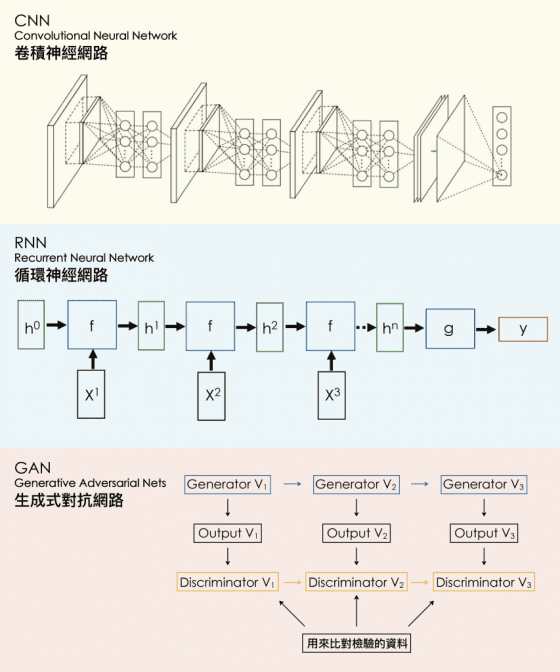
CNN 善於處理空間上連續的資料,例如影像辨識;RNN 適合處理有時間序列、語意結構的資料,例如分析 ptt 電影版的文章是好雷或負雷;而 GAN 生成器(generator)與鑑別器(discriminator)的對抗訓練模式可以輔佐電腦「觀全局」,不會忘記自己做過的步驟而發生窘況,像是教電腦自動畫皮卡丘時,忘記自己已經畫了一個頭,最後畫出兩個頭。
強大的 AlphaGo 如何深度學習?
與 AlphaGo 對弈的柯潔曾表示:「與人類相比,我感覺不到它(AlphaGo)對圍棋的熱情和熱愛。我會我用所有的熱情去與它做最後的對決」。若以情感面來探討,確實為難 AlphaGo 。
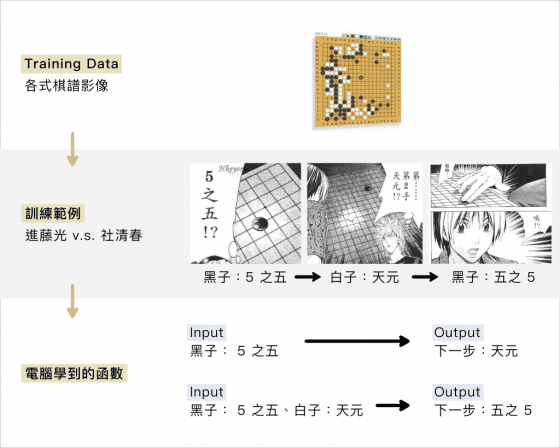
因為在 AlphaGo 深度學習的過程中,訓練的資料並沒有任何熱血動漫或情書情歌,而是一張又一張專業的棋譜影像資料。台大電機系李宏毅教授以《棋靈王》漫畫的棋譜比喻說明,請見下圖。
異質神經網路 (HIN):教電腦找到不同種資料的關連
除了「深度」,也別忘了「廣度」,把不同類型的資料整合在一起,可讓分析結果更精準。
來自伊利諾伊大學芝加哥校區的俞士綸教授點出,通常企業機關擁有的數據,是從各種不同管道蒐集而來,往往屬於不同型態。例如 Google 呈現搜尋結果建議時,除了看搜尋的關鍵字,也會參考使用者平常 Gmail 常用哪些字,或使用者正位於 Google Map 上的哪個位置。
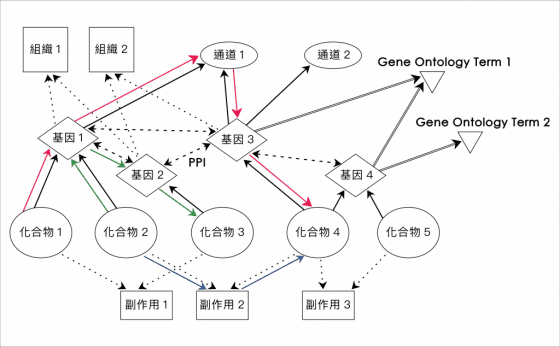
這需要透過 HIN 異質神經網路(Heterogeneous Information Networks)技術,來理解並串連不同種類資料之間的關係。
俞士綸教授以藥物研發為例,在藥物合成或試驗前,可先透過深度學習分析相關資料,瞭解化合物的藥效會控制哪個基因、該基因和哪個通道有關係,或了解某個副作用會由哪兩種化合物引起 (註一)。這些深度學習的分析結果,再搭配和生醫或化學專家討論,有助縮減研發藥物的時間和花費。
深度學習,超幅提升電腦視覺能力
1960 年代,人工智慧先驅者 MIT 教授 Marvin Minsky 曾說「給我三個月,還有一位大學生,我要讓電腦可以辨識影像」,但當時電腦的聰明程度只會畫一些簡單的圓形、正方形,後來 Marvin Minsky 和學生 Gerald Sussman 宣告這個挑戰失敗。
到了 1990 年代,電腦視覺(Computer Vision)有更進步的發展,例如由 David Lowe 發表的 SIFT(Scale-Invariant Feature Transform)演算法,用來描述影像中的局部特徵,藉以偵測影像或影片在位置、尺度、角度上的對應及變異。
現在大家常用的 panorama 全景攝影、3D 模型建立、VR 影像縫合等技術,皆應用到 SIFT 或類似的演算法;而 NASA 在外太空拍下火星地景照片時,也是透過 SIFT 演算法來比對地景特徵。

時間來到 2017 年,受惠於深度學習的進展,電腦視覺技術彷彿從單細胞生物進化到智人,發展出優異的影像辨識及理解技術,並成功應用於各行業與生活中。例如:在生產線上辨識紡織品花紋的瑕疵,以及網美愛用的修圖 APP ──辨識痘痘的位置並套上讓肌膚平滑的濾鏡。

運用深度學習教電腦辨識視覺特徵,發展到極致可望革新人類的生活。Viscovery 研發副總裁陳彥呈博士在演講中分享,現今 NVIDIA 的自動駕駛系統,從頭到尾只教電腦一件事:「辨認哪裡還有路可以開,才不會撞上」。秉持這個單純的概念,擴增訓練的影像資料、優化深度學習的神經網路,NVIDIA 自動駕駛系統的影像辨識正確性、反應速度和駕駛時速,不斷提升到可以上路的程度。


用 100 張違規停車的照片,加上 100 張依規停車的照片,透過 150 層的 ResNet 深度神經網路來訓練電腦,辨認出違規停車。聽起來是很棒的點子。
陳彥呈以過來人的經驗分享,這最大的挑戰在於:第一層輸入訓練電腦的影像資料中,「機車」和「腳踏車」的視覺特徵變異,遠大於地上「白線」和「紅線」的視覺特徵變異,會讓電腦誤以為要學習辨認「機車」和「腳踏車」的不同,而無法辨認出「白線」和「紅線」。
就像要教小狗「坐下」,但卻說了很多不同語言的「坐下」,或同時伴隨華麗的手勢,會混淆小狗究竟該辨認哪個特徵,無法做出正確的反應。
一開始準備訓練深度學習模型的資料時,就要處理乾淨,有助於後續神經網路的運算表現。
深度學習:一天 24 小時不夠用 QQ
中研院資訊所陳昇瑋研究員在演講中說明:深度學習讓電腦具備從繁雜資料中歸納規則的能力,但電腦畢竟不像人腦直覺,過程中還要教電腦處理各層函數的權重(weights)與偏差(bias)。
台大電機系李宏毅教授分享教電腦辨識 ”2” 的經驗,需要餵給電腦一萬張以上的手寫數字影像資料。而若要訓練電腦自動畫出二次元人物頭像,為了達到看起來會想戀愛的精美程度,至少要運算 5 萬回合(epoch),而每跑 100 回合可能就耗費大半天光陰。

打算將鐵杵磨成繡花針的老婆婆,曾經感動李白奮發向上,而若李白來到這個時代,看到電腦科學家不屈不撓的「深度學習」精神可能會雙膝一軟。若您是某企業的高階長官,千萬別對軟體工程師說:「這有資料,現在深度學習不是很紅嗎?試試看,一個禮拜後報告。」任何人工智慧技術,都需要時間淬煉。
XXX 工作會消失?天網會消滅人類?

隨著科技發展,現在有音樂串流平台,可以排解工作煩悶。早上也能透過智慧手機鬧鐘,讓自己在降低起床氣的旋律中睜開眼睛。這些是在留聲機及鬧鐘尚未出現前,曾經有的人工服務,但現在圖中的工作都已經消失了。
「唯一不變的,是變的本身。」 (Change is the only constant.) -- 古希臘哲學家 Heraclitus
幫助人們完成做不到的任務、解決心有餘而力不足的問題,這是自始至終發展人工智慧的目標。
以中研院「106 年度資料科學種子研究計畫」正在進行的研究為例 (註二),人工智慧可望幫忙解決生活中許多問題,包含:透過行動上網訊號來觀測人口流動,並預測傳染病的傳染區域途徑;藉由分析近年來交通事故的地方法院民事判決,歸納出法官如何衡量肇事責任的分配;亦可透過電腦視覺分析蛾類的體色,了解體色變化與氣候變異的關係。
現階段人工智慧受惠於深度學習,雖然相當強大,但尚有許多限制有待突破,電腦科學家們仍在蒐集訓練資料、優化神經網路、改善運算效能這條路上馬不停蹄。對於想踏入深度學習領域的初心者,李宏毅教授在演講中說出相當真實的心聲:
你看別人做手拉坏好像很容易,但自己做下去會有各種崩潰,深度學習也是一樣。心法在於你要相信自己一定做得出來!

看完這篇文章,當媒體下標天網要消滅人類、機器人發展自己的語言嚇壞工程師時,相信你已了解深度學習的能力與發展可能性。來自美國南加州大學的郭宗杰教授,在演講中笑著說:「因為不懂,會把它(深度學習)講得非常強;但如果懂了,就會知道它其實相當地有限,不要被外行人的說法嚇到。」
無論何種身分,若對於人工智慧和深度學習的最新發展感興趣,後續中央研究院資料科學種子研究群的活動現場有個位子,留給未來的你。
延伸閱讀
- 2017 中研院 AI 月活動
- 註一. “PathSim: Meta Path-Based Top-K Similarity Search in Heterogeneous Information Networks”, PVLDB, 2011.
- 註一. “Integrating Meta-Path Selection with User Guided Object Clustering in Heterogeneous Information Networks”,. ACM KDD, 2012. (Best Paper)
- 註二. 106 年度資料科學種子研究計畫最終核定名單
- 迎接AI,先做到「AI Ready」。作者:陳昇瑋
- 人工智慧、機器學習與深度學習間有什麼區別? 作者:Michael Copeland
- 執行編輯|林婷嫻
- 美術編輯|張語辰
![]()
本著作由研之有物製作,以創用CC 姓名標示–非商業性–禁止改作 4.0 國際 授權條款釋出。
本文轉載自中央研究院研之有物,泛科學為宣傳推廣執行單位






































