- 【科科愛看書】你覺得自己是明辨是非、智慧超群的科青,但面對五花八門的商品就是無法割捨?購物車裡總是堆滿待買清單、每到月底就感到扼腕……這到底是什麼疾病啊啊啊!還請各位莫急莫慌莫害怕,容《用大腦行為科學玩行銷:操控潛意識,顧客不自覺掏錢買單,賣什麼都暢銷》向你道出決策之後的腦科學,相信在了解潛意識的力量之後,無論你是消費者或是行銷人,都能夠荷包滿滿、財源滾滾來呀~
預測行為、寫出腳本,就能將消費者握在掌心!
在人物行銷中,將象徵目標市場的參考使用者設定為「人物」(persona),配合這個人的特徵、行動來開發商品或構思行銷方案。此即針對這個人物,找出讓報酬預測誤差拉到最大的方法。
如大家所知,「persona」的原意是「面具」,在心理學用語上是指人類對外的面相(對於周圍的適應狀況)。不論是誰,為了適應周圍環境,多少都會戴上一些面具,並且會因為個性而大大左右這個面具的呈現。在市場行銷上設定人物時,比如說住在都市的三十五歲單身女性,注重時尚與健康……等等,經常看到這種設定,但重要的是內在的真正性格,那才是最為左右購買行動的人物本質。

行銷腳本也是相同的。因為是推測目標對象會有什麼樣的行動來撰寫行銷腳本,也就是如何拉大腦袋中的報酬預測誤差,且是考量大腦的學習效果所進行的預測。
腦科學揭開「購物決策黑箱」
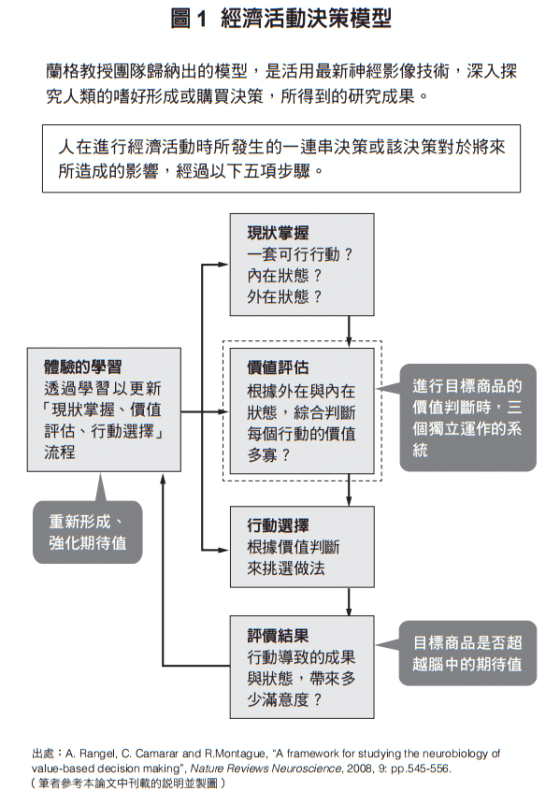
活用最新的神經影像技術來研究腦部活動圖像,可獲得許多與購買決策有關的知識,也可以清楚了解人類形成習慣或嗜好時的大腦運作模型。當中,美國加州工業大學蘭格教授(A.Rangel)的研究團隊,在綜合檢視眾多腦科學論文後彙整出的模型,應該是目前最能簡潔說明「決策到購買行動」其間運作的理論,我想這在商務上十分具有值得參考的地方,以下將簡單地說明。
夏天就想喝冰飲料?都是大腦叫我去買的!
人腦隨時會參考天氣、溫度等自然環境條件,或是用餐時間、與顧客見面等外在環境所賦予的各種資訊,或是感覺肚子餓、腳痛等身體內部的各項資訊,因應當下狀況作出對於腦部最好的決策。結果大腦就會做出各種行動命令,像是走路、進食或開會等身體行動。
購買東西的時候,當然會經由與此相同的腦部運轉,而進行購買東西的決策,並向肌肉作出行動命令,成為身體行動展現出來。
以上的過程,「掌握現狀」成為行動起點。假設在便利商店買東西──正好是中午時間,肚子也餓了,再加上外面天氣很熱,因此想喝點冰涼的飲料。這時候身體外的環境條件和身體內的變化,會引起空腹感或口渴的感覺,又剛好發現便利商店,並且決定到裡面看看。

腦並非是無意識地做出所有的指令,而是經由讓人有所意識,促使可以順暢地進行去便利商店的這項行動。這時候可能有好幾間便利商店,或是也有速食店或餐廳,要從其中進行選擇,不過在這裡先簡化,選項就設定為只有眼前的便利商店。
奶茶好還是紅茶好?大腦的價值評估會告訴你
便利商店裡面有許多的食品和飲料。這時候,腦中開始思考要選擇哪項商品,這就是「價值評估」。也就是針對目標商品來進行價值判斷。這時候,腦中應該有三種系統在運轉。
根據這個價值判斷,進行商品挑選,並產生拿起商品的行動,這是「行動選擇」的階段。這時候,如果成為選項的商品種類很多,彼此之間價值沒有太大差異的話,為了選擇出價值更高的商品,需要花費更多的作業時間。
吃下所選擇的商品,感覺「很好吃」或「味道普通」的過程,就是「評價結果」。對於所選擇商品的期待值越大,品嘗之後的結果若比期待值來得低,就會覺得這個商品不好吃,但如果比期待值高的話,當然就會認為這項商品很美味。
並且,如果感覺非常美味,就會想到「下次也要買這個商品」,也就是所說的「上癮」。如果覺得味道普通,那可能會覺得「再買一次也可以」。如果比原本想得還要「難吃」,也就是說比期待值還低,對於金錢付出的這項行為無法獲得滿足感,反而感受到損失,相信就不會想再買一次同樣的商品了。

不讓你失望,你就會對商品深深上癮
現在這個時代,在商店販賣的商品,幾乎沒有難吃的東西,如此一來,若商品比期待值稍微來得低,就可能讓顧客產生極大的損失感。果然,追求美味這件事,是能延伸到創造回客率的重要課題。像這樣經由「評價結果」的過程,重新進行價值觀或期待值的形成與強化,就是「經由體驗學習」。
所謂的「厭倦」,某種角度來說就是報酬預測誤差越來越小,獲得的結果開始感覺低於期待值。因此,如何讓顧客不感覺厭倦,就是勝負關鍵。
這種時候,當然不讓人厭倦的美味很重要,但要在怎樣的時機點,讓顧客形成怎樣的期待值,則至為關鍵。
販賣商品時,要讓商品成為長紅人氣商品,並不只是依靠食品本身的味道而已,也不是單靠包裝、設計、行銷方案或廣告就能做到的。需要研究部門、商品開發部門、市場行銷部門和營業部門的負責人員成為一個團隊,將這些要素有策略性地打造出腳本,並加以實踐。
經常聽到由品牌經理人領導各部門的專業菁英來組成團隊的重要性,從大腦的運作模式來思考的話,或許這是非常理所當然的事情。

本文摘自《用大腦行為科學玩行銷:操控潛意識,顧客不自覺掏錢買單,賣什麼都暢銷》,方言文化出版。