

大家有不小心把自己畫成白鼻心,或者是臥蠶畫成眼袋過嗎?有畫鼻影的時候有不小心把自己畫成阿凡達的納美人過嗎?原本就方方的臉有沒有好像覺得越畫越寬?相信很多人都有這樣的慘痛化妝經驗,特別是在新手期 XD

之前在分享過一些有關解剖結構的文章,希望大家對這些知識更有掌握,可以把妝化得更好。其實化妝品 「cosmetics」是希臘文的「kosm tikos」,翻譯過來大概是「裝扮巧妙,使自己更具魅力」。字首的「kosmos」的意思,就是裝飾。既然要裝飾成「某個樣子」,那你心裡面就不可能「沒有某個樣子」。對多數人來說,「某個樣子」通常代表「更年輕」、「更有吸引力」。以現在人的標準來看,更有吸引力通常代表「更立體」、「更精緻」的五官比例。
所以今天我想分享的是:
1. 光影如何影響人臉的視覺效果
2. 人類的臉部老化過程——比較年輕的臉跟老化的臉的差異
3. 符合東方美學概念的臉部比例
如果要保養,也必須知道到底哪些是可逆的,哪些是不可逆的。看懂之後就不用亂花錢囉!
累了嗎,我們聽首歌吧!痾,不是啦,先來看一下影片~片長兩分多鐘,大家看個三十秒就可以停了。
光線的顏色與明暗對人臉視覺上的影響
https://www.youtube.com/watch?v=uqTuo2yQBXM
從這部影片,你可以清楚看到,不同顏色、不同角度的光,對人臉在視覺上會產生很大的影響。如果全都是強光,沒有明暗,就不會有立體感。你想想看,這不就是化妝在做的事情嗎?另外你也可以知道,為什麼在某些餐廳、某些店家,照鏡子照起來就會特別好看?這除了鏡子的原因以外,光線的顏色跟角度也都有差喔!!!下次如果不小心又沈浸在某個讓自己看起來很瘦的鏡子前,趕快回想一下這篇文章,醒醒吧阿宅,這一切都只是幻覺啊!
人臉自然老化的過程
從一個小蘿莉,長成花樣年華的少女、再到輕熟女、然後熟透,然後過熟(誤),慢慢步入中老年的過程,到底是怎麼回事呢?我們來看一下這支影片,一分鐘帶你走過女人臉部的八十年。
https://www.youtube.com/watch?v=tTBlFC-oAnw
人的臉部老化是「全面性的」,從皮膚、皮下脂肪、肌肉到骨骼,都有各自老化的過程。
臉部皮膚的老化
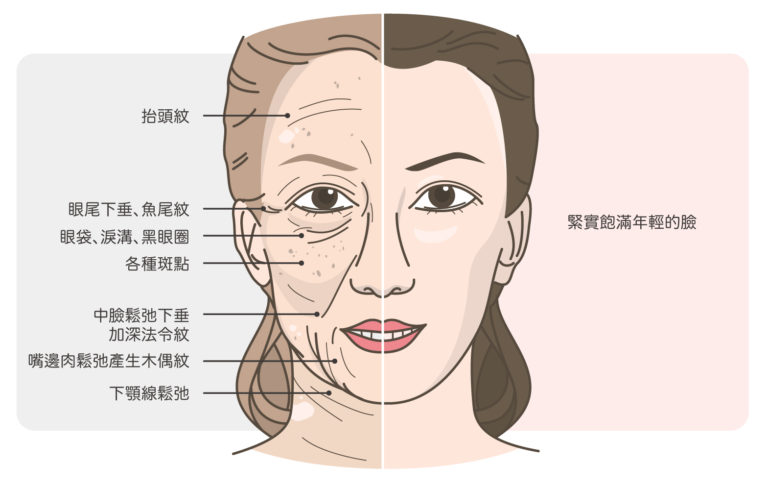
皮膚從外到內有很多層次,我們就由外而內說明:
皮膚變薄:老化過程中,膠原蛋白跟彈性纖維變性,結締組織也會流失,所以皮膚就會變薄。老人的皮膚常常一擦到就破,就是這個原因。
皮膚鬆弛:皮膚變薄加上重力的影響,臉部皮膚就會呈現鬆弛。
皮膚粗糙:表皮的角質層因為角化異常,就會導致皮膚粗糙。
乾燥:青春期腺體分泌旺盛,但老了就功能下降。皮脂腺和汗腺分泌不足,無法形成正常的皮脂膜,皮膚就會乾燥。
黑斑:正常的黑色素小體會均勻分布。但如果色素調節異常,就會出現局部的黑色素增加,產生黑斑或曬斑。
白斑:有時候某些黑色素細胞會退化,就會在它負責的區域產生一點一點的白斑。
老人斑:表皮細胞不正常的角化,會產生脂漏性角化症或俗稱的老人斑。
老年性紫斑:老年人血管及周遭的膠原蛋白跟彈性蛋白都減少,所以微血管變得脆、硬,很容易一碰撞就出現一大片的出血。年紀越大就越容易出現!
大家要注意的是,上面有些事情是你可以阻止的,例如防曬;但有些就幾乎難以預防,只能順其自然。有些廠商會隨便宣稱他的東西有療效,聽聽就算,不要浪費錢。
臉部脂肪的老化
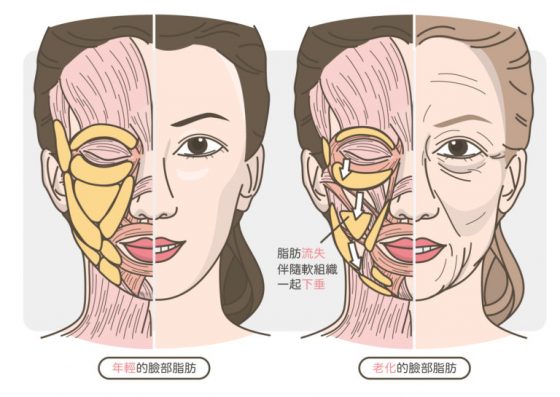
臉部在老化的過程中,脂肪會流失,另外也會伴隨著軟組織一起下垂,所以逐漸就從一個倒三角的 V 臉,變成一個正三角形的下垂臉了。年輕的女生常常在哭自己有嬰兒肥,你不知道那是甜蜜的負荷啊!等你老了,該有肉的地方沒肉,肉都垂到不該有的地方你就欲哭無淚啊……。
臉部肌肉的老化:張力增加
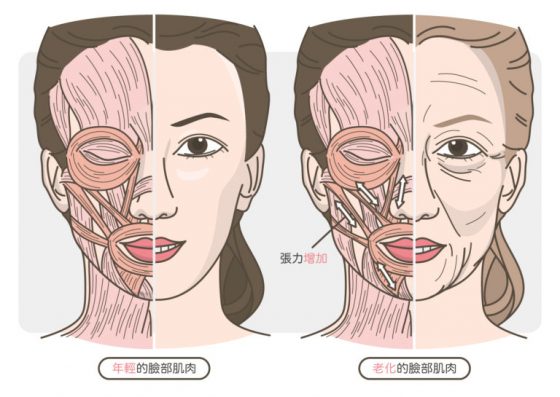
有句玩笑話,什麼是老男人:就是該軟的都硬了,該硬的都軟了……該硬的不硬,不該硬的血管啊、攝護腺啊通通都硬了。但肌肉這件事情更是老天爺的玩笑,四肢的肌肉常會因為老化萎縮,但臉部的表情肌反而會因為老化而張力增加……,經年累月的拉扯加上過強的肌肉張力,就會出現很多表情紋路。像是抬頭紋啊、魚尾紋啊、法令紋啊、皺眉紋之類的,讓我忍不住想起這首歌啊:如果說一切就是天意,一切就是命運,終究……(透露年齡…)。
臉部骨質的老化
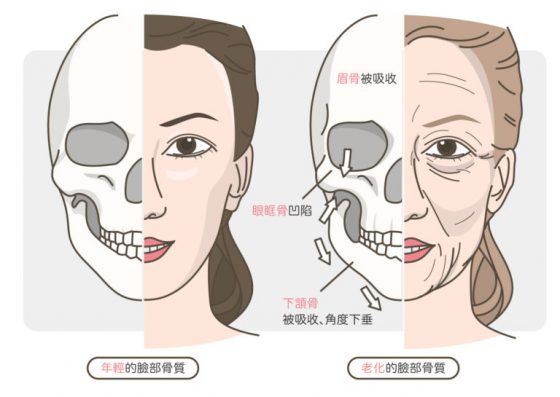
大家可能比較難想像,骨頭這麼硬的東西也會變?其實骨頭是「活的」,隨時都有「生骨細胞」在製造新的骨質,也隨時有「蝕骨細胞」在吃掉老化的骨質。老了之後,製造新骨的能力低於蝕骨的能力,就會慢慢看到骨質流失了。在臉部常可看到眉骨被吸收、眼眶骨更凹陷,下頷角更往下垂等現象。可以對照骨骼圖看:
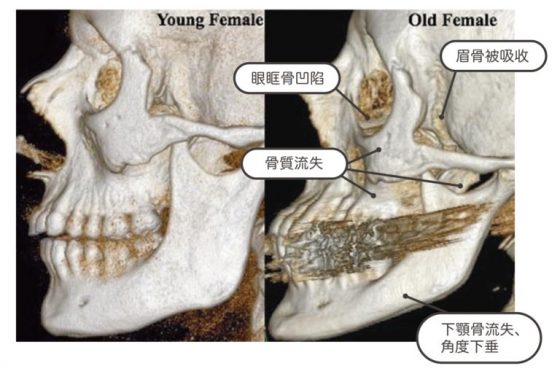
年輕的臉 VS 老化的臉
所以一張年輕的臉,基本上會是:
1. 皮膚緊實、平滑
2. 肌肉張力不過強,沒有皺紋
3. 輪廓呈現一個倒三角形(inverted triangle face)
整張臉也不是只有一個大的倒三角,你可以把它拆解很多個,把整張臉用很多個倒三角來設計 。例如把整個臉當一個大的倒三角,或者眼睛一區、嘴巴下巴一區之類的都可以。 總之臉上可以區分成很多三角,但一定是倒三角 ,絕對不能是正三角 !不然就是老的臉……。
近年也有人提出好看的臉是大小兩個心形:
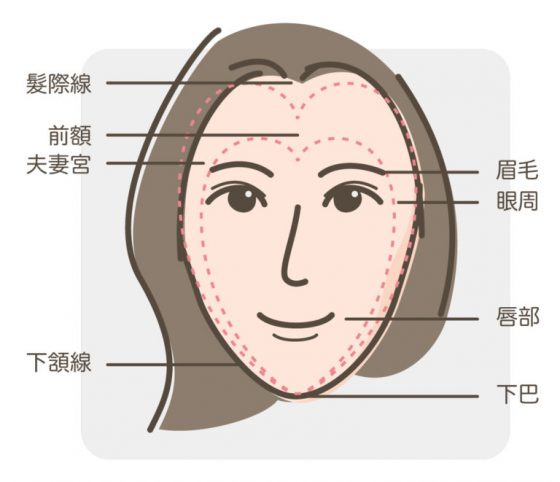
不管是哪種,照著這樣的輪廓去化妝,或者是作為保養、治療的目標方向就對了。所以接下來的目標,就是讓他趨近倒三角,或所謂大小雙心的結構!我們能做的,就是光影的明暗效果,或者是立體效果。亮的顏色就是顯大,暗的顏色就是顯小。越立體你看上去就是小,越平面你看上去就是大。 要讓他變寬,就讓他平面化發展 ;要讓他看起來窄,就讓他立體化發展 。
這有點像是一個三角做圖法,你可以在臉上取兩個不會動的點,例如兩邊的眉尾,然後選定一個第三點去動作。不管是化妝還是整形。
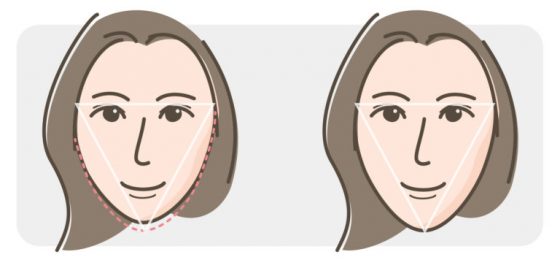
像是上面這張圖,左邊的女生下巴就短了一點點,不管是用拍照角度、化妝或是整形拉長了比例,就變更好看了。
所以最好看的臉就是又小又精緻又立體。 大家想想看喔,如果你臉白,就會顯大。所以要在螢幕上,又白、看起來又小,那就必定要有立體的五官。有沒有這種人呢?有一個歷史上很標準的正妹:

但這只是一個美的典型,別忘了美是有很多很多種的喔!而赫本當然也抵擋不了老化的力量,大家可以觀察其中的變化。
符合東方美學的臉部比例:三庭五眼和各種黃金比例
大家可能會想知道,符合東方美學的臉部比例是什麼樣子?其實也是有些客觀的分析標準,有興趣的朋友可以看隆鼻懶人包第一集,有更完整的角度介紹。但這邊就先讓大家看個最基本的三庭五眼圖。
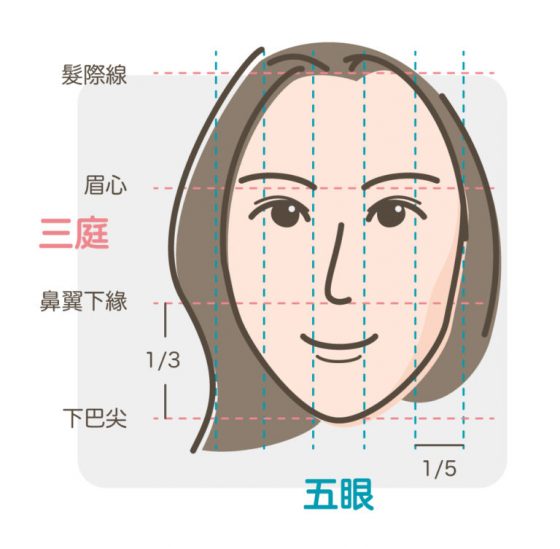
記住,整型是非必要的,化妝、髮型、微整形、手術都是可能的選項,當然要花你比較多錢,或承擔比較多風險的,就一定要想清楚喔!
同場加映:視錯覺原理在化妝與整形的應用
講到化妝或整形,就不能不知道「視錯覺原理」。它可以分成由感覺器官引起的「生理錯視」,以及由心理原因導致的「認知錯視」。詳細的視錯覺成因跟機制可以講到很複雜,但這邊先簡單說,基本上視錯覺原理就是個愚蠢的「人類自行腦補的故事」。
好啦,也不能這麼片面把人類當作這麼愚蠢啦~人類的認知功能是有限的,必須在很短的時間做出判斷,然後把認知功能專注放在重要的事情上,所以對於很多事情我們會傾向直接腦補……所以你就會出現錯覺。視錯覺廣泛出現在我們生活中,這邊我們舉幾個可能用得上的例子吧~
案例一:A 和 B 兩個長方形,哪個比較長?
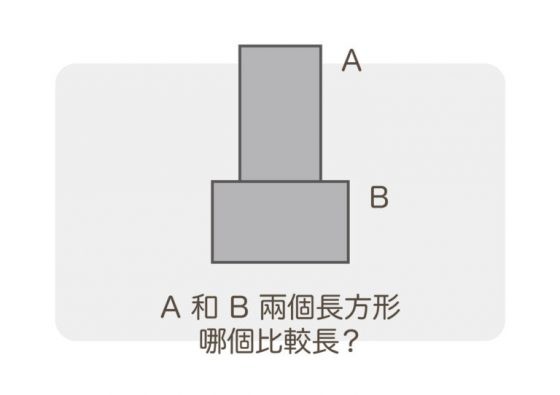
其實這是兩個一模一樣的長方形。人在看兩個相同的長方形時,會傾向於把 A,擺成豎起來的這個看得更修長。所以可以在化妝時或穿搭時,設計一些豎長的線條,都會顯得比較修長。這道理很簡單,叫胖子穿橫條紋就是個悲劇不是嗎……。
案例二
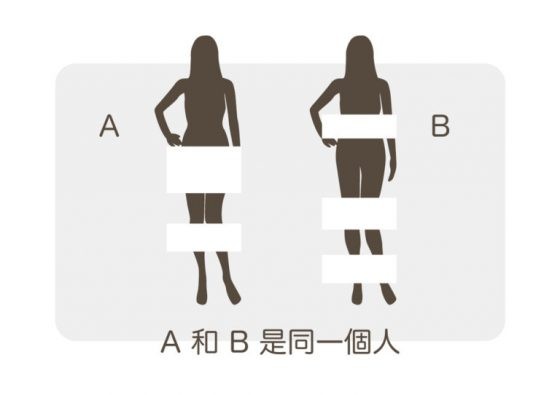
A 和 B 其實是同一個人。只要把其中一部分地方遮住,只露出剩下的部分,人們就會腦補被遮住的畫面。所以不管在穿衣服還是化妝還是設計髮型的的時候,想辦法露出自己最瘦的地方,或者遮住自己最胖的地方,或者顯露出五官最立體的部分,遮住比較平或角度不好看的部分,大家就會把你腦補成又瘦又五官立體的正妹惹(無誤)。
案例三:這兩個女孩哪個比較高?
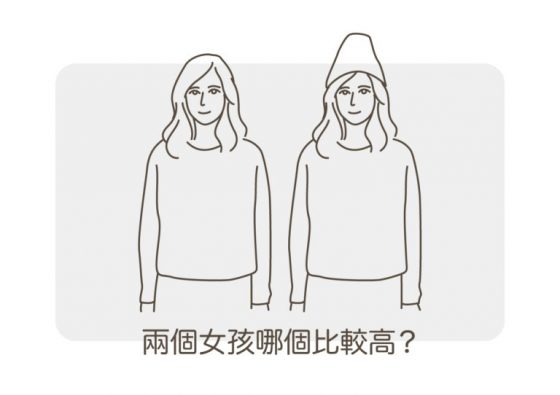
答案是一樣高。但大家都覺得戴帽子的那個高。這就是「視覺動線」的作用,這是一個利用「顯眼的視覺焦點」,大家就會把視覺動線往上拉,或者是往下拉,這個戴帽子的女孩就是因為你的視覺動線上移所以看起來高。當然也可以往左拉,或往右拉(但這類運用較少)。例如有個寬臉妹子,又同時帶了很亮眼的耳環,你在看她的時候,視線跟著耳環左右移動,恩,那就悲劇惹。所以如果你的臉部比例不是標準的三庭五眼,都可以利用這招,不管是用帽子、髮型、首飾等小心機做出效果喔~
案例四:哪條線比較長?
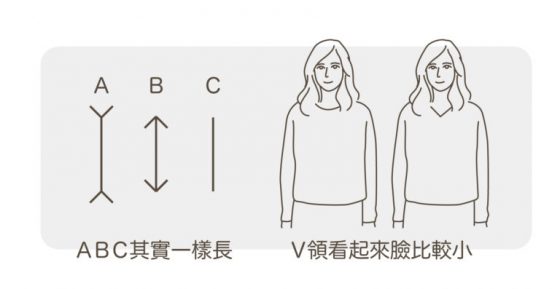
最後一定要介紹一下上港有名聲,下港有出名的「萊依爾錯視」。三根線明明一樣長,但在箭頭的作用下,B 顯得最短,A 顯得最長。
這個可以解釋非常多事情!!!在穿搭上這就是V領衫可以顯得臉小的原理。在臉型上,這就是 V 臉為什麼看起來臉小的原理。活用這個錯視,你可以搞出一大堆變化!一統自拍界指日可待啊哈哈哈哈哈!
今天這篇文章是希望讓大家知道,化妝跟整型都是可以很科學、很醫學的。有更多的知識,就可以用更低的成本,達到更好的效果。不會因為不懂成分,結果買了一堆可怕的產品毀掉自己的臉,如果要整形也不會因為搞不清楚狀況,接受了一個根本不適合你的手術。
另外也希望大家正確認知「老化」這件事情,但不是要大家害怕老化,然後趕快去亂買抗老產品。知道什麼是老化、理解老化的機制,接下來我們會慢慢找機會補上其他相關機制,告訴大家哪些對預防老化是「實證有效的」,哪些是「持續爭議中的」,哪些是「根本沒效不要再被騙的」。錢跟時間是你最需要掌控的。把這兩樣東西運用好,人生就會有餘裕。但要把錢跟時間運用好,其實是需要很多正確的知識啊!!!
所以拜託千萬不要隨便放棄治療,或者是手滑亂買東西啊……。腦袋空空,錢包就會空空,這是不變的真理啦!!!科學其實沒這麼難,希望大家卸下心防,讓我們幫助你輕鬆學習,然後實際應用在日常生活中~
看完這篇文如果覺得有幫助,趕緊用底下按鍵分享給所有好朋友吧!不傳的沒朋友啊啊!(不夠要好的就不用傳了,認真。因為化妝或整形就是一種競爭,如果大家都超正,就顯不出你的正了…科科)
助人省錢,功德無量,阿彌陀佛~~~
編按:愛美是每個人的天性,不過對你而言光是看滿架的化妝品、保養品,各種醫美產品就令你眼花撩亂,更別說還有玻尿酸、膠原蛋白、類固醇這些有聽沒有懂的名詞來搗亂嗎?如果你想要聰明的美,不想要被各種不實廣告唬得團團轉,那麼泛科學這位合作夥伴 MedPartner 美的好朋友,就是你我的好朋友。
本文轉載自MedPartner 美的好朋友








































