全文提要
你相信命中註定嗎?究竟是相似的還是互補人在一起比較幸福?為什麼網路上有些心理測驗看起來都很準?這篇文章試著回答上述的問題。有鑑於每次都覺得文章太長,大家常常看到眼睛脫窗心生鬱卒,所以這次簡短(?)地寫了一個摘要,讓每秒數十萬上下的你能抓到重點:(1)交友網站有用嗎?首先,它並不如想像中有效,至少和你自己找差不了多少;(2)再來,各大網站速配指數的計算方式大多採用人格類型互補,或相似的配對計算方式,這些算法首先在計算上會產生一些弔詭與問題,而且(4)最大的問題不是算式本身,而是無法將後續許多變因納入考量。(4)但是,為什麼有些人還是會覺得有效?一種可能是巴納姆效應(The Barnum Effect)所造成。(5)在文化意義上,相對於選擇來說,相處還是比較重要。(6)結論:愛情造就了我們,但是我們也造就了愛情。
正片開始
「最新暗黑風格網頁遊戲!」、「外表壞沒關係,要以結婚為前提」、「有沒有錢不重要,對我溫柔就很好」。臉書玩到一半,右邊或左邊總是會跳出一些小視窗。除了總是愛盜用別人圖片的網頁遊戲之外,最常出現的就是「交友網站」的廣告了。這些網站總是用幸福成功的案例,以及可愛動人的正妹圖片吸引你,不過,到底實際上效果怎麼樣呢?
首先,這些標語在某種程度上其實是一種誇大不實--不要再相信你右邊沒有科學根據的廣告了。事實是:像照片中這麼正的女生,不「只會」要求你的外表或金錢而已,她還會要求你的個性、社會地位與權力(Buss & Shackelford, 2008)。
再來,配對成功率高嗎?按照各位科學人銳利的眼光和直覺,通常會預期得到一個否定的答案,不過,案情可能比你想像得還要複雜。如果你不想讓大腦進行太過複雜運轉的人,請參閱前陣子Jacky Hsieh言簡意賅的精闢文章《線上交友的科學缺陷》。
不久以前我們也試著跟一些交友網站合作,他希望我們利用統計媒合的方式幫忙他們設計一些問卷與算則,以期幫助他們的客戶,找到生命中重要的另一半。我覺得這個立意很好,也慶幸自己總算在長篇大論之外也能替社會做點實質的事情,於是找來整個實驗室對開啟關係(搭訕、認識、吸引力)最有研究,數學方程模型又最在行,帥氣挺拔風流倜儻的小風來一起規畫[1]。
我們目標很簡單,只有兩個:
(1)找出哪些人可能彼此吸引然後在一起
(2)找出哪些人可能會幸福快樂地在一起很久(happily ever after)。
可是,經過幾次晤談討論、徹夜的計算規劃之後,有天他突然冷冷地對我說:
「光靠那些問卷資料,根本不可能達到這兩個目的。」
我那時候心想?騙人的吧?如果我們做不出來,那麼國外的交友網站,以及對岸的婚配網等等,事業做這麼大,究竟是怎樣辦到的?
這個問題的答案,要從去年一月我們到美國參加心理學年會開始說起[2]。其中有一個親密關係研究專家才會參與的場次,由一個美國最大的交友網站協理與心理學家Gonzaga共同主持。雖然Gonzaga抱持著比較保留的態度,網站協理卻聲稱可以將人格分成幾個類型,然後找出人格「相似的人」推薦給你,幫你量身訂作屬於你的幸福(Gonzaga, Campos, & Bradbury, 2007)。

祕密壹:相似好還是互補好?
聽協理這樣說,或許你會問:「那麼互補呢?互補的人不是聽說也很幸福?」
University of Groningen的Dijkstra & Barelds會反問你:
「你真的知道,你想要的是什麼嗎?」
他們的一項研究中曾問參與者:「你想要找的,究竟是一個像你的伴侶(相似),還是能完整你的伴侶呢(互補)?」,然後以人格量表請他們評估自己以及「理想中」的伴侶各應該具有的特質,結果發現,大家都活在「互補的幻覺中」。85.7%的人都說,他們希望找到一個「能完整自己」的互補伴侶--但量表卻指出,他們理想的伴侶其實是和自己相似的,而且,大部分的女生都在尋找同樣一個男生:外向,體貼,做事謹慎而讓人有安全感(Dijkstra & Barelds, 2008)。
可是你或許會接著說,這個結果並不代表「相似的伴侶比互補的伴侶優」啊!沒錯,或許會讓你大失所望的是,這問題在會議當場並沒有被提出來--因為古早的時候這些做初始關係的人就吵過了:雖然相似和互補各有各的重要性,但長期來說,與相似的伴侶在一起,還是比互補的伴侶摩擦來的少,而且,更重要的是「你覺得」對方跟你像不像,而不是「實際上」對方跟你像不像(Lutz-Zois, Bradley, Mihalik, & Moorman-Eavers, 2006)。跟「你覺得像」的人在一起你會感到比較多幸福,而這種幸福感又會回過頭來讓你覺得你跟他越來越像(Morry, Kito, & Ortiz, 2011)。
總之,支持「互補」這一派人馬就會淚眼汪汪地跟「相似」說:「魔王,你贏了」[3]。但如果你發揮柯南精神,你會發現上面Dijkstra & Barelds的研究有一個地方好像怪怪的--大家的人格特質都不一樣,那和自己相似的「那個人」不是也會不一樣嗎?那我們如何喜歡「和自己相似」的人,又在尋找「同一個」人呢?其實,這牽涉到「相似」的計算方法。

祕密二:「契合度」究竟是怎麼算的?
這個部份需要花一點腦,如果你現在大腦跟牛仔一樣忙,可以先跳過這段中間直接看結論。過去研究計算相似性,大都是採用兩種方法[4]:
(1)以Profile Similarity的方式來看人格特質的相關程度。簡單地說,假設你在人格量表上1到5題的得分是5,5,1,4,1,小花也是5,5,1,4,1,那麼你跟小花簡直是天作之合--至少比得分是5,5,1,4,2的小熊適合你,因為你和小花比較「像」--而得分是1,1,5,2,5的小堅則完全不適合你,因為你跟他實在「太不像」了(圖一)。這類的計算方法在乎的是「整體起伏」的相似,他高你也高,你低他也低,那麼你們就是彼此的真命天子或天女。
(2)以Difference Score的方式來看兩者的差距,也就是把兩個人的分數相減,取絕對值。同樣的例子,假設你在人格量表上1到5題的得分是5,5,1,4,1,你和小花的差距就是0,和小熊的差距是1,和小堅的差距是18。你看,小堅果然很不適合你!這類的方法在乎的是程度,也就是你在某項特質的得分多寡。
一言以蔽之,我們一方面可以藉由Profile Similarity得分較高,或是Difference Score差距較小,找出和你相似的人,也另一方面可以單純計算「你覺得理想的情人應該具備哪些特質?」,找出得分最高,大家都重視的特質。這樣,Dijkstra & Barelds研究所說的:「大家都在找同一種人,但也在找與自己相似的人」的說法就可以說得通了--只是用不同觀點看同一份資料而已。
類似這樣的方法,甚至一直到近幾年的美國社會心理學年會中都還在延用,用來預測之後這個人會不會跟你在一起、你們會不會互相吸引(Luo, 2009)、在一起之後,相似的人就比較幸福嗎等等(Cheng & Chen, 2009)--遺憾地是這兩種方法都有問題。

圖一
小均的難題
舉例來說,倘若今天小均做完測驗得分是2,2,2,2,2,揪竟是得分1,1,1,1,1的阿傑,還是5,5,5,5,5的小竹是她的真命天子呢?Dr. Profile Similarity會預測這兩個人都一樣適合她,但是Dr. Difference Score會說:「傻瓜阿你,當然是阿傑阿!因為和阿傑差距是5,和小竹的差距是15耶!」。這樣看起來,似乎Difference Score的方法區辨力較佳,略勝一籌。
但是如果今天半路殺出了5,1,2,2,1分的阿泰(差距也是5),那他要選誰呢?當Dr. Difference Score在苦惱時,Dr. Profile Similarity就可以神氣地說:「當然是阿傑阿!因為圖型的pattern比較像。」(請見圖一)
簡單地說,這兩種算法都有問題,也都有優缺,也就是:這兩種相似的計算方式,在實務應用上是互補的(噢,這句話好有深度)。你可以舉出更多例子,使得兩位Doctor都無法作出決策--只是,心理學家現在還普遍用這樣的做法。那麼,這兩種有缺陷的做法有效嗎?哪一種效果比較好?答案是:至少契合的人比起不契合的人更幸福滿意自己的關係,而兩種作法的預測力差不多(Luo, 2009)。
祕密三:更簡略的算法
不幸中的不幸是:上述這兩種差強人意的方法,還只有「比較用心」的交友網站會採用--也就是說,更多的網站用更偷懶的方法。
故事又要從去年底我們參加的華人心理學家學術研討會說起了。會議當天我們發現北大心理學院許燕院長的一個學生在進行對岸最大的婚配網站配對系統研究[5],在研討會結束後,便巴著她一同討論著這交友商業市場界的秘辛。許燕老師表示,雖然那是她滿久之前做的研究,結果有些忘了,不過大致上發現一重要的事情:門當戶對。
「首先家庭背景要相仿,好比說一個是高知識份子家庭出身,一個是工人階級,我們幾乎很難相信他們是可以溝通的。咱們中國不是有句話說門當戶對嗎?你知道什麼是門當嗎?」我搖搖頭,她笑了會兒,停頓一下接著說。她笑的樣子,讓人有種心底花蕊被澆了幾滴水的感覺。
「以前宅院兒大門前頭都會有一塊大石頭,有錢人家的石頭逼角大(比較大),愈是有錢,石頭愈大,如果你是窮苦人家呢,可能連塊石頭都沒有。總之,是一種財富的象徵。在嫁娶的時候,左鄰右舍都會咕噥相互逼角(相互比較),看男方女方家的門當是不是一般大。」她操著流暢的北京口音,說起話來卻同時兼顧山東大妞的豪邁與文人的婉約溫柔,讓我無法不想起以前一位可愛的女朋友(拭淚)。
「是阿,在台灣的情況也是。結婚其實是兩家庭的事情,雙方的家長占了非常大的影響力。」影響力有多大呢?一項研究指出,雖然我們看起來像是在自由戀愛,但真正談到結婚的話,家人,親戚,朋友等等你身邊週遭的人大概占了五成以上的因素(Zhang & Kline, 2009),包括要不要跟這個人結婚、持續這段婚姻等等。

那麼,大陸的婚配網究竟是怎樣幫會員配對的呢?通常,加入會員之後都會要求填一份簡短背景資料與量表,先按照興趣,經濟能力,外貌等「吸引力」進行分組,把「近水樓台」與「門當戶對」的人分到同一群組。接著,把你分類到幾種類型中的某些類別[5]。比方說,小潔的測驗結果是「科學家」型,喜歡分析事情,追根究柢,好奇心很強,與耐心、善於傳授、說明事情的「教師」型非常速配,於是從小潔所在的群組中挑選「教師」型的人推薦給她。
當然,每個網站所用的類型名稱不盡相同,有的用動物,有的以星座,有的幫你的感情風格取非常夢幻的名字,如「深情迷戀」、「炙熱瘋狂」、「冷若冰霜」等等,有的採取相似論的觀點,有的採取互補論的看法,但是共通點都是:用很少的資訊,把你分類,分組,標籤。他們甚至沒有邀請Dr. Score Difference與Dr. Profile Similarity一起參與決策。而且,最大的缺憾是:沒有信度可言。
什麼是信度呢?信度是指一個測量工具的可信程度。舉一個講解心理測驗的時候,老師常常會用的例子,如果你早上量體重是48公斤,中午吃完量是50公斤,晚上睡前量是49.2公斤,那某種程度上你可以相信這個體重計,因為它每次量不會差太多。可是,如果你三次測量的體重是80,20,52,那你可能會懷疑是不是體重計壞了,或是你產生了幻覺之類的。
只是,這些交友網站的問卷為了減少填表人的不耐煩,有的甚至連讓你測量兩次的機會都沒有:大多數的特質只用單題來測量。試問,如果你好久沒有量體重,站到體重計上發現自己變成60公斤,然後體重計不知為什麼就從人間蒸發了,無法讓你測量第二次,那麼你會相信自己真的是60公斤嗎?
祕密四:選擇性注意的陷阱
不過交友網站這樣的做法其實相當有「表面效度」--看起來滿有效的。為什麼呢?半個世紀前有一個心理學家Forer (1949)做了一個有趣的實驗,我在這裡稍稍改良一下,讓大家玩玩看:
如果有人送你一束花,你會將它放在家中的哪裡呢?請用直覺立刻回答!
A.客廳 B.臥室 C.廁所 D.玄關 E.餐廳

準備好了嗎?
要公布答案了喔!
「選A的人,你需要別人喜歡你與欣賞你,但你通常對自己很嚴苛。你雖然有個性上的缺點,但通常會加以彌補。你有很多實力沒有好好發揮成你的優勢、你的外在表現很有自律也很自制、內心卻比較焦慮不安。有時候你會比較懷疑自己是不是做對決定或事情。你比較喜歡事情有多一點改變與多樣性,而且受到拘束或限制時,你會感到不滿。你覺得自己是個獨立思考者,為此感到自豪。在沒有令人滿意的證據下,你不輕易接受別人的說詞。你也覺得對別人太過坦白是不智的。有時候,你是外向、好親近、和善的,但有時你也比較內向、謹慎、沉默寡言。噢,還有,你有些夢想比較不切實際一些。」(引自Wiseman, 2008, pp. 30-31)
先解到這邊,選A的人覺得準嗎?大約有幾成準?如果你是選A的人,請你把準確性用0%~100%默寫在心裡。

實際上,那個花瓶題目是我胡謅的。而且, 我並沒有為選其他選項的人量身訂做任何答案。在Forer(1949)的研究中,所有的參與者都拿到像上述內容一模一樣的解測報告書,可是,縱使用這種荒謬的做法,還是有超過一半的人認為這測驗很準--這意味著,人總是選擇性地注意自己認同的事情與資訊。
下次看爽報或P-Paper的時候,你可以把星座名稱遮起來,單看每個星座的描述或運勢,你同樣會發現:要命!每個都好像在說自己。這就是有名的巴納姆效應(The Barnum Effect)。
所以,這些網站只要用一些花俏的插圖,甚至只要重複、誇大、模稜兩可地擴寫你曾經在問卷中回答過的東西,很容易讓你在做完測驗後有非常準的錯覺。如果,這個網站又有知名學校的老師背書,可信度又會上昇許多。
如果你辛苦讀到這裡都沒跳過,那麼你可能翻桌用原住民(?)的口吻大吼:「交友網站到底有沒有用阿到底?!」。有鑑於再拖下去我會被揍,讓我們召喚一下Northwestern University的Eli J. Finkel替我們回答。
「結果是,迄今為止的網路交友企業,並沒有交出一張漂亮的成績單,他們用看似最科學的方法,用數理模型,用所謂的匹配算則,讓會員們相信他們可以在這裡找到屬於他們的命中注定。」Finkel和其他幾位親密關係界研究的大咖在最新一期<Psychological Science in the Public Interest>中,針對過去交友網站線上約會(online dating)研究們進行系統性回顧與批判,發現這些業者不是言過其實,就是誇大其詞。
Finkel等人透過兩個研究,試圖回答兩個問題:
(1) 線上交友所產生的戀愛關係,跟一般戀愛關係一樣嗎?
(2) 線上交友精挑細選的戀愛關係,是不是比一般戀愛關係帶來更好的結果?

關於第一個問題,答案是否定的。不論是約會、互動、溝通媒介,這些兩種戀愛關係都大異其趣,這個大家應該很好想像。
但是關於第二個問題,答案是:Yes and no。Yes的部分,主要是針對溝通。線上交友的方式可以透過網路進行對談、傳訊息等方式(Computer-Mediated Communication,CMC),迅速地拓展一個人的交友圈,在見面之前就先了解彼此--雖然這種方式並不是適合所有人。
在No的部分,主要是針對前面所談的「配對」(Matching)這個概念上--我們對「速配」抱持太多的期待了,畢竟一開始的速配並不保證後來的幸福(matching do not always improve romantic outcomes)。Finkel指出:「他們都忽視了,多年以來親密關係研究的『重要關鍵』。」他們可能用幾個成功案例當成「楷模」,或是列出一些超有吸引力的帥哥正妹照片,讓你相信你也可以找到適合的對象。因為這些帥哥正妹有月暈擴散效果:讓你覺得他或她除了帥或正之外,個性也不錯(Brand, Bonatsos, D’Orazio, & DeShong, 2012),甚至把這樣的想像擴散到別人身上,想像其他的成員一定也很優。
祕密五:為什麼無法為幸福掛保證?
那麼,效果到底怎麼樣呢?首先,線上問卷的資料最大的問題就是:非常可能造假(Ellison, Hancock, & Toma, 2012; Guadagno, Okdie, & Kruse, 2012; Toma & Hancock, 2012)。男性喜歡造假自己的身世背景與社會地位,女性最愛造假的則是體重(Hall, Park, Song, & Cody, 2010)。
就算大家都很誠實、也姑且不論他們推薦給你的命中情人是用什麼樣的方式計算出來的,在手上有的資料非常有限的情況下,仍然不可能「保證幸福」。
為什麼呢?過去大量的研究顯示,在一段關係中,重要的並不是你的樣子或她的樣子,而是你們在一起的時候,吵架的時候、聊天的時候、去玩的時候、互訴心事的時候、分享生活點滴的時候,究竟呈現出什麼樣子(e.g.:Rusbult & Van Lange, 2003; Uysal, Lin, Knee, & Bush, 2012; Woodin, 2011)。
你可能一個人的時候是一個樣子,跟朋友在一起又是另一個樣子;跟超級死黨相處是一個樣,與爸媽出去又是另一個樣。
更重要的是:雖然幼時被撫養照顧的經驗,以及與前一段情人的關係,會影響你和現任伴侶的相處方式(Busby, Walker, & Holman, 2011),可是在每一段戀情裡面、每一段關係當中,你都會有一些不一樣,甚至呈現出不同面向的你(Gosnell, Britt, & McKibben, 2011; Horberg & Chen, 2010),一輩子面對不同的階段與對象,你詮釋戀愛事件與戀愛的方式也不盡相同(Dykas & Cassidy, 2011)。
如果你的前男友支配慾很強,可能會讓你從外向活潑變得退縮,讓你在找下一個情人的時候小心謹慎一點,甚至是找一個可以給你多一點自由的人;如果你女朋友常常人間蒸發,那麼就算原先你是一個很有安全感的人,也會被她搞得焦慮不堪;如果你是一個害怕孤單的人,不過對方能夠多花一些時間照顧你,給予不斷的保證關懷,你也會變得比較能忍受寂寞。
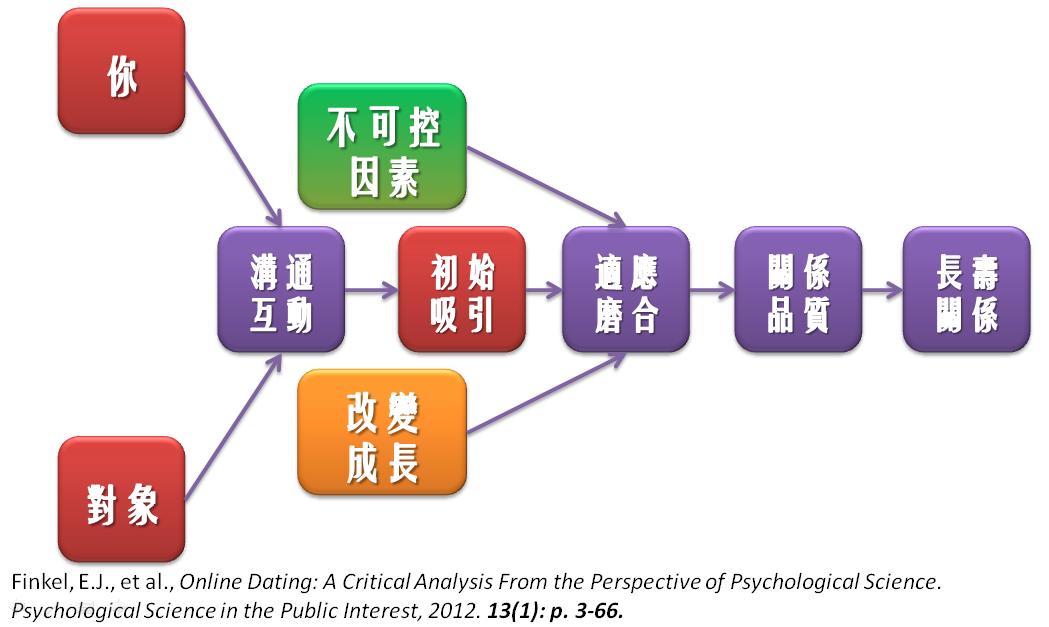
Finkel等人(2012)所說的「重要關鍵」,其實就是:愛情改變了我們,我們也改變了愛情。我們可以看上面這張圖二:兩個人一開始像不像、配不配、會不會被吸引只占了整張圖的很小部份(紅色框處),更重要的是中間的相處過程,以及當中面臨的壓力與轉變(紫色框處)--但這些,交友網站幾乎都沒有納入考量。例如,文首提及的Gonzaga 和他的同事們在另一份研究中發現,雖然人格相似性與關係滿意度有關,但是隨著相處時間的增加,相愛的兩個人會越變越像,願意為對方有意識或無意識地「修剪」自己,更重要的是,彼此的情緒也會跟著同步,為對方的眼淚傷心,幸福著彼此的幸福(Gonzaga, et al., 2007)。
最後的祕密:幸福是製造的,不是光靠尋找的
其實之前跟許燕老師的談話還有後續,而且正好與Finkel主張的相當一致。
「所以,我們的研究解析出第二個可以預測婚姻幸福的因素,就是這個人的彈性。揪竟一方可不可以溝通、願不願意改變、遇著困難時習不習慣換個角度想想等等。雖然門當戶對很重要,我們能自由選擇的成份看似變少了,但也因為這樣,咱還有一項滿好的優勢是:當關係不若我們預期的時候,我們會選擇調整改變自己。」許燕老師在趕著回飯店、打包去日月潭的行李時前跟我說。
事隔半年,幾個月前世新大學社會心理系辦一場研討會,邀請來的文化與親密關係研究的大師Susan Cross蒞臨演講也談到:相對於美國人,我們更相信好事多磨,進入一段關係本來就有捨有得,性格相似性的效果更低;相反地,美國人在乎一個人的獨特性,希望能找到一個「能完整自己的人」,如果關係破裂,那就放棄找下一個(Wu, Cross, & Tey, 2012)。他們會認為,對方根本不適合自己。

可是我們不同,華人更重視「關係」與「相處」。本來就沒有完全適合自己的人,我們需要做的,就是找到一個願意接納不完美、願意改變的人,陪自己走一段路。
總而言之,交友網站或許讓我們增加了好多認識別人的機會,拓展了我們的交友圈,可是,沒有任何的指標能保證幸福不分手,也沒有任何人能幫你訂做一段只屬於你和他的關係。
它們只是開啟了一些可能,至於這些可能要通往哪裡,還是得自己去經營、去摩擦、去感受、去爭執、去妥協,並且在一次一次的砥礪之中,找尋繼續前進的動力。
Reference
Aube, J., & Koestner, R. (1995). Gender characteristics and relationship adjustment – another look at similarity complimentarily hypotheses. Journal of Personality, 63(4), 879-904. doi: 10.1111/j.1467-6494.1995.tb00319.x
Brand, R. J., Bonatsos, A., D’Orazio, R., & DeShong, H. (2012). What is is beautiful is good, even online: Correlations between photo attractiveness and text attractiveness in men’s online dating profiles. Computers in Human Behavior, 28(1), 166-170. doi: 10.1016/j.chb.2011.08.023
Busby, D. M., Walker, E. C., & Holman, T. B. (2011). The association of childhood trauma with perceptions of self and the partner in adult romantic relationships. Personal Relationships, 18(4), 547-561. doi: 10.1111/j.1475-6811.2010.01316.x
Buss, D. M., & Shackelford, T. K. (2008). Attractive Women Want it All: Good Genes, Economic Investment, Parenting Proclivities, and Emotional Commitment. Evolutionary Psychology, 6(1), 134-146.
Cheng, W. C., & Chen, J. W. (2009). Love Style Similarity, Conflict Management and Relationship Satisfaction. Paper presented at the New Directions in Research on Close Relationships, Lawrence, Kansas, U.S.
Dijkstra, P., & Barelds, D. P. H. (2008). Do People Know What They Want: A Similar or Complementary Partner? Evolutionary Psychology, 6(4), 595-602.
Dykas, M. J., & Cassidy, J. (2011). Attachment and the processing of social information across the life span: Theory and evidence. Psychological Bulletin, 137(1), 19-46. doi: 10.1037/a0021367
Ellison, N. B., Hancock, J. T., & Toma, C. L. (2012). Profile as promise: A framework for conceptualizing veracity in online dating self-presentations. New Media & Society, 14(1), 45-62. doi: 10.1177/1461444811410395
Finkel, E. J., Eastwick, P. W., Karney, B. R., Reis, H. T., & Sprecher, S. (2012). Online Dating: A Critical Analysis From the Perspective of Psychological Science. Psychological Science in the Public Interest, 13(1), 3-66. doi: 10.1177/1529100612436522
Forer, B. R. (1949). The fallacy of personal validation – a classroom demonstration of gullibility. Journal of Abnormal and Social Psychology, 44(1), 118-123. doi: 10.1037/h0059240
Gonzaga, G. C., Campos, B., & Bradbury, T. (2007). Similarity, convergence, and relationship satisfaction in dating and married couples. Journal of Personality and Social Psychology, 93(1), 34-48. doi: 10.1037/0022-3514.93.1.34
Gosnell, C. L., Britt, T. W., & McKibben, E. S. (2011). Self-presentation in Everyday Life: Effort, Closeness, and Satisfaction. Self and Identity, 10(1), 18-31. doi: Pii 918012183
10.1080/15298860903429567
Guadagno, R. E., Okdie, B. M., & Kruse, S. A. (2012). Dating deception: Gender, online dating, and exaggerated self-presentation. Computers in Human Behavior, 28(2), 642-647. doi: 10.1016/j.chb.2011.11.010
Hall, J. A., Park, N., Song, H., & Cody, M. J. (2010). Strategic misrepresentation in online dating: The effects of gender, self-monitoring, and personality traits. [Article]. Journal of Social and Personal Relationships, 27(1), 117-135. doi: 10.1177/0265407509349633
Horberg, E. J., & Chen, S. (2010). Significant Others and Contingencies of Self-Worth: Activation and Consequences of Relationship-Specific Contingencies of Self-Worth. [Article]. Journal of Personality and Social Psychology, 98(1), 77-91. doi: 10.1037/a0016428
Kenny, D. A., & Acitelli, L. K. (2002). Measuring similarity in couples (vol 8, pg 417, 1994). Journal of Family Psychology, 16(3), 337-337.
Luo, S. (2009). Partner selection and relationship satisfaction in early dating couples: The role of couple similarity. Personality and Individual Differences, 47(2), 133-138. doi: 10.1016/j.paid.2009.02.012
Lutz-Zois, C. J., Bradley, A. C., Mihalik, J. L., & Moorman-Eavers, E. R. (2006). Perceived similarity and relationship success among dating couples: An idiographic approach. [Article]. Journal of Social and Personal Relationships, 23(6), 865-880. doi: 10.1177/0264407506068267
Morry, M. M., Kito, M., & Ortiz, L. (2011). The attraction-similarity model and dating couples: Projection, perceived similarity, and psychological benefits. Personal Relationships, 18(1), 125-143. doi: 10.1111/j.1475-6811.2010.01293.x
Rusbult, C. E., & Van Lange, P. A. M. (2003). Interdependence, interaction, and relationships. Annual Review of Psychology, 54, 351-375. doi: 10.1146/annurev.psych.54.101601.145059
Toma, C. L., & Hancock, J. T. (2012). What Lies Beneath: The Linguistic Traces of Deception in Online Dating Profiles. Journal of Communication, 62(1), 78-97. doi: 10.1111/j.1460-2466.2011.01619.x
Uysal, A., Lin, H. L., Knee, C. R., & Bush, A. L. (2012). The Association Between Self-Concealment From One’s Partner and Relationship Well-Being. Personality and Social Psychology Bulletin, 38(1), 39-51. doi: 10.1177/0146167211429331
Wiseman, R. (2008). 伯特倫。弗爾教授與夜店筆跡學家 (洪慧芳, Trans.) 讓你瞬間看穿人心的怪咖心理學—-史上最搞怪的心理學實驗報告(Quirkology:how we discover the big truths in small things) (pp. 30-31). 台北: 漫遊者文化.
Woodin, E. M. (2011). A Two-Dimensional Approach to Relationship Conflict: Meta-Analytic Findings. Journal of Family Psychology, 25(3), 325-335.
Wu, T.-F., Cross, S. E., & Tey, S.-H. (2012). Dating relationship success in the U.S. and Taiwan: Does similarity or parental approval matter? Manuscript in preparation for publication.
Zhang, S. Y., & Kline, S. L. (2009). Can I Make My Own Decision? A Cross-Cultural Study of Perceived Social Network Influence in Mate Selection. Journal of Cross-Cultural Psychology, 40(1), 3-23. doi: 10.1177/0022022108326192

[1]所以,我們現在也還在找找看有沒有更好的測量方法,比方說,將兩個人的互動納入考量。
[2]按此下載會議章程:www.spspmeeting.org/archive/SPSP2011_Program.pdf
[3]不過,也有人提出解套的說法是:價值觀相似會產生吸引沒有錯,可是,兩個人越像,就越會調整彼此的行為(adjustment),或盡量「補」上對方(Aube & Koestner, 1995)。這就是傳說中有名的「相似生互補假說」 (similarity complimentarily hypotheses)。
[4]這方面文獻非常多,算法的變形也不少,這裡列出基本的兩種做法,如果你懶得看太多篇,數學也不錯,建議讀Kenny & Acitelli (2002)這篇回顧。
[5]這項研究也發表在去年的亞洲社會心理學研討會上。For more information: http://act.baihe.com/event/1108vote/
[6]如果你對於這些交友網站有興趣,有一個調查匯集了多交友網站與其特色,歡迎造訪這裡。
[7] 噢,對了,你可能已經發現了,這篇文章裡面主要引用到Finkel的研究,在是四月《PanSci:看見驚奇–從開始到最初的愛》演講的時候也曾聊過,如果你對這些研究有興趣,但又不想看這麼多字的話,可以點選影片來看,也再次推薦Jacky Hsieh言簡意賅的文章《線上交友的科學缺陷》。
[8]Pictures credit : 非主流圖片