


正所謂「人在江湖飄,哪有不挨刀」,同樣地,在職場上打滾的人兒們總會遇到些狗屁倒灶的事,坐辦公室的會遇到同事搞小團體,科技業會遇到機台狀況不穩定,服務業則會碰到某些澳洲來的客人。
而不論是各行各業,都會遇到一個共同的問題,乃「上司是個豬頭」也。
豬頭上司有兩種極端,其一是榨乾部屬不遺餘力,踩著別人的屍體往上爬;另一種則是尸位素餐、渾沌無知,最後「將帥無能,累死三軍」。針對後者,我們不禁要問「既知無能,何以為將帥?」此問題有很多可能的答案,也許他的祖墳會冒青煙、也許他做事無能,逢迎拍馬卻有能的很、也許他是之前有能,升官目的達到後就自動變無能。

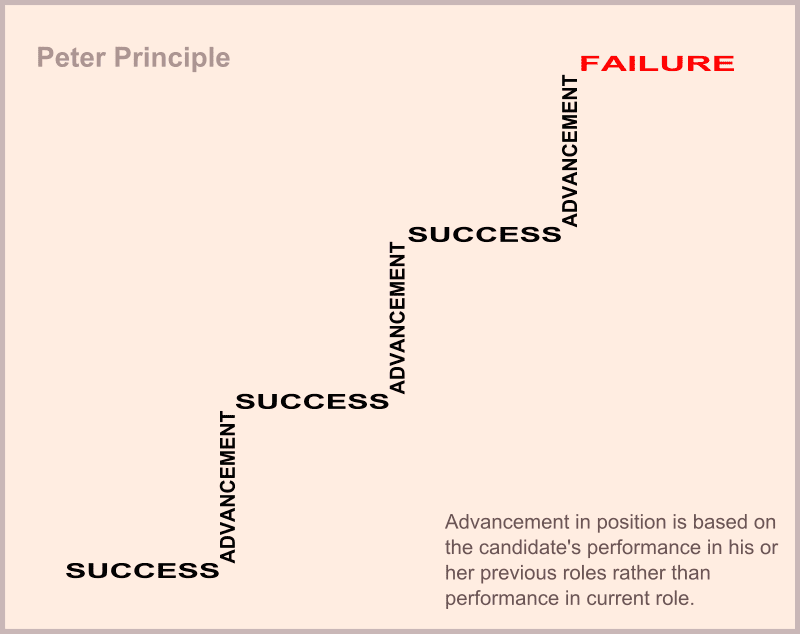
也許,就像上個世紀的管理學家勞倫斯.彼得所說的一般,這是等級制度下必然的產物。
勞倫斯.彼得於1969年提出了「彼得原理」,在維基百科上的註解為:「在組織或企業的等級制度中,人會因其某種特質或特殊技能,令他在被擢升到不能勝任的地步,相反變成組織的障礙物(冗員)及負資產」。這個原理奠基於一個假說,勞倫斯.彼得假設一個人在某個階級中的表現,和在其他階級中的表現其實沒啥關聯。
來源:wiki pedia(編輯者Nevit Dilmen)
比如說一間工廠中,一個好的學徒會認真打雜,卻不一定能成為好的技師;一個好技師要有專業技術,卻不一定可以當個好領班;一個好領班能靈活運用底下的人力,卻不一定能當個好監工;一個好監工能掌握工程進度,卻不一定能當個好廠長。
而在等級制度中,往往是表現好的學徒才會傳授技能,技術佳的技師才會被選為領班,以此類推,當成員在某個階級的表現不佳時,就會停留於那個階級不再前進;如果一個能擔當廠長大任的人才,陷於等級制度而淪為一個二流技師,那麼擇優晉升的策略反而會讓組織變得沒有效率。
但是,如果不去晉升表現好的人,又該晉升什麼人呢?
三個義大利的科學家(一個社會科學 + 二個天文學家)於是建立了一個金字塔等級制的組織模形,想找出最佳的晉升策略。這個金字塔狀等級制模型中,上層的人少、下層的人多,相對的,上層的人所肩負之責任權重較下層人高,每個人的能力(含效率、專業、工時等綜合考量)則化為數值,組織的總體效益為所有人的能力數值乘以其責任權重後之加總。

起初,每個人的能力數值呈現常態分佈,當人員晉升時到新的階級時,會給他一個新的能力數值。
若依一般的思維,人員晉升後的能力與其原階級的表現有關,所以用舊數值為基礎,再加、減一點點隨機的誤差值,就成為新階級的能力數值。若依「彼得假說」,晉升後則是由常態分佈函數再隨機賦予新的能力數值。
經過電腦程式模擬了上百個職缺產生和晉升替補的事件後,他們得到了下表的結果:
| 總體效益改變(%) | 擇優晉升 | 擇劣晉升 | 隨機晉升 |
| 一般思維 | +9% | -5% | +1.5% |
| 彼得假說 | -10% | +12% | +1.5% |
也就是說,晉升表現良好的人,那麼「彼得假說」組的整體效益反而會下降;若反其道而行地去晉升表現較差的人,「一般思維」組的總體效益就會下降;而採隨機晉升,則不論是「彼得假說」組或是「一般思維」組的整體效益都會微幅提升1.5%左右。
由此看來,我們應該要搞清楚組織成員的能力數值隨階級的變化到底是像「一般思維」還是像「彼得假說」,才能做出好的晉升決策。再說,無論如何,這只是基於幾個假設所做出的模型,現實社會中,還是依一般思維採擇優晉升比較保險,至少會產生一種激勵做用,讓各階級的成員努力求取好表現。(「激勵」云云,館主沒有去查詢相關科學證明,僅為「想當然爾」,為避免誤導視聽,特此說明。)
然而,這三位義大利科學家卻在他們的論文中表示,既然我們也分不清人們的能力變化是像「彼得假說」還是像「一般思維」,那麼隨機晉升就是最好的策略啦,至少它能讓組織的效益維持不墜。
挖賽!這樣的結論也太不勵志了吧!難到是在告訴大家工作表現不重要,靠擲骰子來決定誰晉升就好了嗎 ?義大利真不愧是一個適合慵懶生活的國度啊!
此研究成果發表於physica A期刊上,作者三人也因「從數學角度證明如果隨機地晉升人,團隊運作將更有效率」的成就,獲得了2010年搞笑諾貝爾的管理學獎。
順帶一提,physica A是物理學期刊,涵蓋領域為「統計力學及其應用」。這個偏管理學的研究可以刊在physica A上,除了因為其模型的數學架構有擦到「統計力學」的邊角外;另一個可能原因是負責此論文的責任編輯對其上司不滿已久,想藉由刊登「彼得原理」的文章來表達些什麼。(大誤)
本文轉載自吳京的量子咖啡館
參考資料:
- Pluchino, Alessandro, Andrea Rapisarda, and Cesare Garofalo. “The Peter principle revisited: A computational study.” Physica A: Statistical Mechanics and its Applications 389.3 (2010): 467-472.





























