

mRNA?別浪費時間,不值得做!
天啊,你知道在實驗室搞 mRNA 有多麻煩嗎?連呼吸都要小心耶!
而且在細胞裡的 mRNA 一瞬間就會被分解成碎片,比廢柴還廢,哪可能生成需要的蛋白質?各位泛糰們好,2023 年的諾貝爾生理與醫學獎是由卡塔琳・考里科以及德魯・韋斯曼兩位科學家獲得,他們獲獎的研究,是許多人現在已經很熟悉的 mRNA 疫苗開發技術,但你可能不知道,其實當初 mRNA 打入實驗小鼠體內,引發非常嚴重的免疫風暴,甚至可能打一隻死一隻。
這這這……設計要來救人的藥物,反而致命? 生醫獎得主考里科的同事甚至認為 mRNA 只是個「笑話」,這怎麼回事?
那個 mRNA 瘋女人來了?
你!渴望力量嗎?啊不,是想要合成 mRNA 嗎?我可以幫你喔!

由於屢屢爭奪印表機使用權僵持不下,故事的兩位主角就此破冰,當時是 1997 年,地點在美國賓州大學醫學院,此時身材高大、外向爽朗的女主角伸出了橄欖枝,正等待回答,男主角卻冷淡地說:「如果你成功了,我會試試。」難道故事就此結束嗎?當然沒有。
先回頭介紹一下考里科。她是匈牙利人,本來家境還不錯,但兩歲時,因為父親公開批評執政的共產黨政府,就此失去了工作,餘生只能打零工,全家住在沒自來水也沒電的磚房裡。遭遇這般變故的卡里科並沒有放棄自己,反而堅持鑽研科學,在匈牙利頂尖的塞格德大學取得了生物化學博士學位,並獲得博士後研究員的工作,投入 mRNA 研究。然而天要降大任,就有人要遭殃,大學的研究中心資金短缺,就把她給解聘了。

為了能讓自己的研究對世界產生影響,1985 年,她決定出國深造,移民美國,但由於政府嚴控資金外流,她把所有積蓄 1,200 美元偷偷縫進女兒的玩具熊裡,才能讓一家人在人生地不熟的紐約暫時安頓。雖然幾乎不會講英文,幸運的考里科很快在天普大學蘇多尼教授的實驗室找到工作,等等,我剛剛說幸運嗎?
對不起,我收回。她沒多久就被蘇多尼教授舉報為非法移民,只因她答應了約翰霍普金斯大學另一份薪水比較高的職位,要衰就衰到底,約翰霍普金斯大學隨即撤回了聘書,她跟先生還得花錢請律師來駁回引渡令,更別提因為蘇多尼繼續中傷她,她也找不到其他工作。

幾經波折,她終於在賓州大學醫學院找到了研究助理教授的工作。但由於她不是醫生,也不是正規職員,無法取得終身職,其他同事根本不把她當同事看,對她投入的 mRNA 研究自然也沒興趣。加上考里科雖然外向開朗,但也口直心快,換句話說,根本就是白目。她只在乎研究,不顧他人顏面,總是直言批評同事研究中的錯誤。她既不能升等、申請研究經費也屢屢失敗,沒辦法從細胞跟生物體中藉由 mRNA 生成治療性蛋白質,獲得數據,那就更沒辦法申請經費。
這時幸運的考里科獲得了一位同事支持,總算做出了一點成果,透過把 mRNA 插入培養皿的細胞裡,使細胞製造出「尿激酶受體」蛋白質。等等,我剛剛又說幸運嗎?對不起,我再次收回。卡里科雖然做出成果,她的熱臉依舊貼上了同事們的冷屁股,即使她主動替許多同事合成 mRNA,也只獲得了「那個 mRNA 瘋女人」的評價。1995 年她的先生因為簽證問題困在匈牙利好幾個月,她則被驗出長了腫瘤,得開刀。這時賓州大學的主管卻要她選擇離開或是接受降級。
為了讓女兒能獲得賓州大學的學費優惠,她嚥下這口氣,接受降薪,職稱變成從來沒人擔任過的——「資深研究調查員」,為什麼沒人擔任過?因為沒人被開除現職之後還願意繼續留在賓州大學裡,她是第一個。
越是山窮水盡,她越覺得解脫,就在這時她遇上了剛來到賓州大學的韋斯曼。

韋斯曼雖然冷淡,但他不是只對考里科冷淡,而是對所有人都很冷淡,他根本不聊八卦,只在乎研究,加上他才來不久,因此根本不知道考里科有多慘,也不在乎別人怎麼說考里科的壞話。韋斯曼早年曾當過安東尼佛奇實驗室的研究員,研究愛滋病,他目睹許多研究員因為無法獲得經費,而遷怒於不願幫忙的佛奇,藉由媒體傳播關於佛奇的負面消息,這讓他極為重視科學研究的誠信與純粹。
韋斯曼雖然對人冷淡,卻是個標準貓奴,他女兒會從收容所把病貓跟棄養貓帶回家,他還曾為了幫貧血的貓打針補充紅血球生成素,差點趕不上重要會議。他也是個偶爾會對同事亂講話的人,但不是因為他也白目,而是因為患有第一型糖尿病,血糖劇烈變化影響了他的認知功能,甚至會突然昏倒。
儘管對 mRNA 沒什麼興趣,正在研究愛滋病毒疫苗的韋斯曼的確用得上 mRNA,而考里科也真的很懂 mRNA。於是,韋斯曼跟考里科這兩支樹枝孤鳥竟然在 1998 年開始合作。幸運的考里科終於……等等?我剛剛說幸運嗎?
COVID-19 疫情帶來的契機
在解釋 mRNA 如何應用前,我們複習一下分子生物學的重要概念:中心法則 (central dogma),也就是 DNA 轉錄成為 mRNA,再依據 mRNA 編碼,將對應的胺基酸組裝起來成為蛋白質。
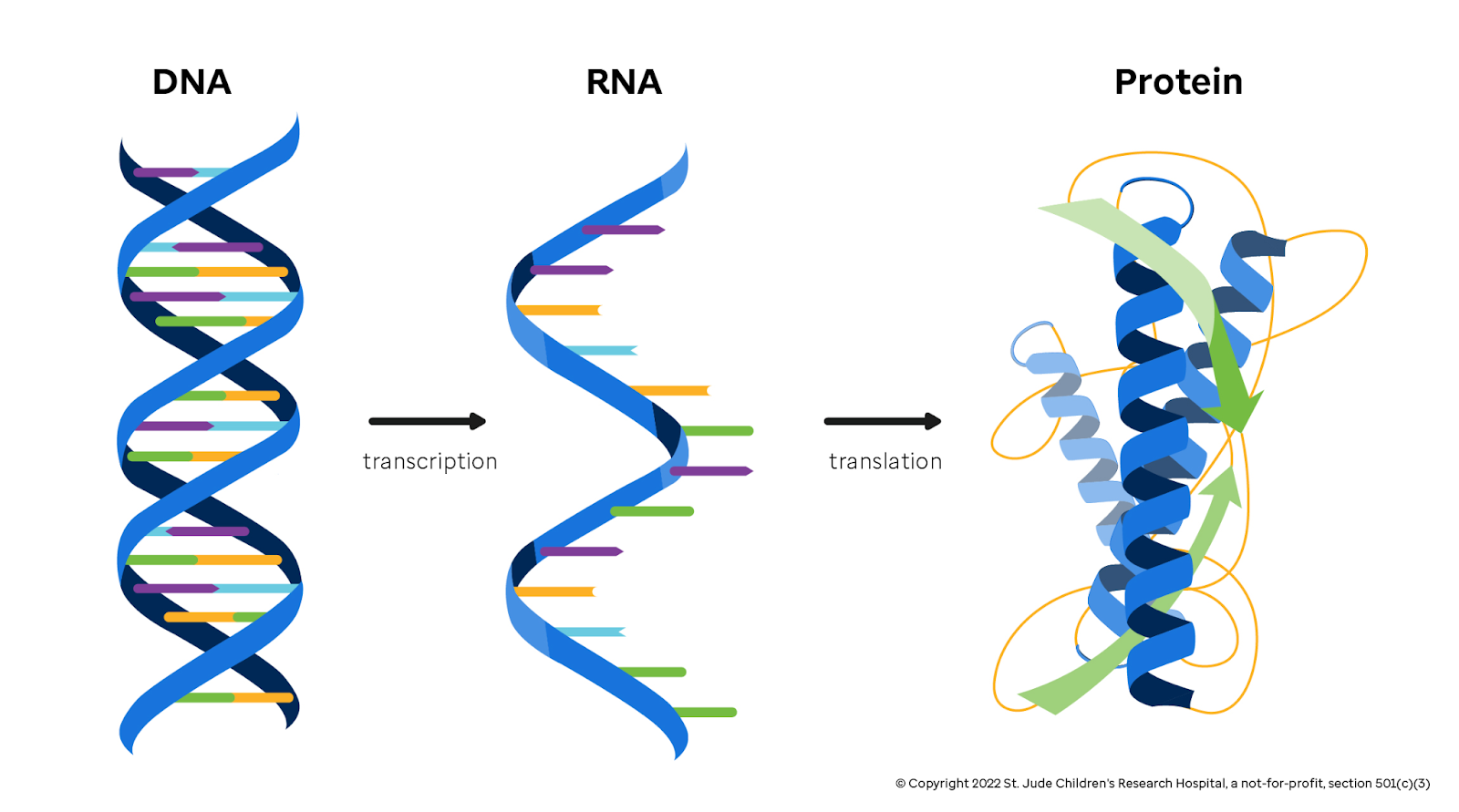
如果我們可以合成 mRNA,只要修改 mRNA 上的編碼,再將這些 mRNA 送入人體細胞內,直接將細胞當作生產蛋白質的工廠,使人體自己產生正確的蛋白質,不就可以治療遺傳疾病了嗎?!
另外,疫苗也是一個應用方向,mRNA 就像是傳令兵,它帶著敵軍病毒的情報交給如同將領的樹突細胞,產出帶有病毒特徵的蛋白質,進而刺激整個免疫系統備戰,並培養出有長期保護力的記憶型 B 或 T 細胞大軍。
剛剛說到,兩人一開始合作是針對愛滋病疫苗的研發,但是當韋斯曼將 mRNA 打入小鼠後,驚訝的發現這些小鼠會一直生病,甚至死亡,免疫反應強到把本體都幹掉了,如果 mRNA 注射會導致死亡,這故事要怎麼說下去?

講到這,我相信大家都明白了,這兩位科學家都不太幸運,但他們還有一個共通點,就是不知道放棄兩個字怎麼寫。
他們想,一般細胞每天也都會製造 mRNA,為什麼這些 mRNA 不會被免疫系統當成入侵者,引發嚴重的發炎反應,造成細胞死亡?
他們後來在實驗中發現注射 tRNA 的小鼠不會有這樣的免疫反應,而 tRNA 與其他 RNA 最大的差異就是有大量的鹼基修飾,難道說關鍵就是修飾?
卡里科擁有非常好的RNA修飾合成的技術,那有沒有可能透過修飾,找到不會引發嚴重免疫反應,卻同時可以順利轉譯出蛋白的 RNA 分子呢?最後他們發現將 RNA 分子中的尿嘧啶核苷「U」修改成為假尿嘧啶核苷分子「ψ」,就能夠躲過免疫反應又可以產生蛋白質,並且在 2005 年時,他們將這個方法應用在猴子身上,修改後的 mRNA 不僅可以躲過免疫系統的攻擊,也能夠有效產生蛋白質。
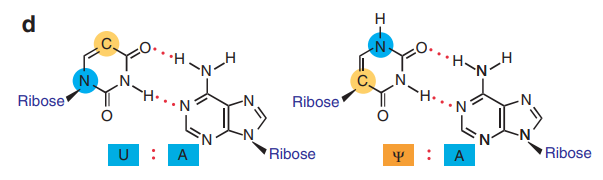
原來卡里科和韋斯曼找到的方法,其實就是免疫系統透過檢視 RNA 裡修飾的型式或比例,藉此判斷敵我的設計機制,因為通常病毒的 RNA 不會經過修飾,所以當體外合成的 mRNA 注射進入人體中,就會被免疫系統辨識成外來病毒,引發體內的免疫反應。
這時只要將外來的 mRNA 經過足量修飾,就可以「騙」過細胞,讓細胞正式成為你的蛋白質工廠。
雖然卡里科與韋斯曼確信自己已經攻克了 mRNA 應用的難題,但很多的科學家仍然對 mRNA 的應用感到疑慮,這些科學家認為這麼不穩定的分子,不容易量產和使用,2013 年,卡里科從日本參加完研討會回來,甚至發現連自己的研究室被清空,讓給了別的研究員,他們兩人的重大發現彷彿被全世界遺忘。
不,他們的研究沒有被遺忘,在史丹佛大學的 Derrick Rossi 和 Luigi Warren 在幹細胞研究中,同樣遇到了 mRNA 應用的困難,直到 Rossi 和 Warren 得知了卡里科與韋斯曼的研究,才突破難關,成功透過加入特定 mRNA,將皮膚細胞轉變成多功能幹細胞,之後在 2010 年,Rossi 成立了世界第一家 mRNA 公司,也就是現在我們熟知的莫德納公司的前身。
而在得知莫德納將與英國的 AZ 合作開發血管內皮因子 mRNA 後,卡里科認為在大學繼續待下去也無法應用她在 mRNA 上的長才,於是前往德國,與 BNT 的創辦人烏爾.薩欣會面,並加入成為副總裁,保留兼任老師的資格。那年是 2013 年,BNT 還是個連網站都沒有的小生技公司,卡里科的決定也因此被學校的主管嘲笑。然而快轉到 2019 年,接下來的事大家都知道了。

2019 年的 12 月 1 日,首例新冠病毒感染個案在中國武漢發生,隔年 1 月 5 日,新冠病毒全基因體解序完成,向全世界發布。2 月,新冠疫情開始往全球散播。
1 月 25 日莫德納公司的 Stephane Bancel 與美國國衛院國家過敏與傳染病研究所所長 Anthony Fauci 進行會議,2 月底莫德納完成 mRNA-1273 疫苗的動物試驗,同時,BNT 開發出二十多隻 mRNA 候選疫苗,從新冠病毒完成基因體解序後的第 66 天,3 月 16 日,世界上第一位 mRNA 疫苗臨床受試者開始施打,這是人類首次能夠在短時間內,製作出對抗新興傳染病的疫苗的時刻。
而這一切,若不是當年卡里科與韋斯曼的努力不懈,突破 mRNA 的應用限制,使 mRNA 疫苗成為可能,那麼 COVID-19 所造成的死亡人數會遠遠高於現在統計的 695 萬人。
擇善固執還是冥頑不固
在科學研究中,我們常常看到戴著光環的成功案例,但不被失敗擊倒,其實才是科學的真實樣貌。

相較過往,這次諾貝爾奬很「快」頒給了 mRNA 研究,為什麼說快呢?因為諾獎往往是在論文發表後幾十年才會頒布,慎重到必須是寫進教科書等級的實證研究,才有資格。所以研究者不僅研究厲害,也要活得到頒奬,這次能夠這麼快受到諾貝爾奬肯定,代表 mRNA 疫苗確實是終結疫情的重要功臣,有目共睹,實至名歸。
卡里科在獲獎的當下表示,儘管最近幾年得到很多肯定,但其實這一路上並不是一帆風順,所以說獲獎的瞬間還不太相信,甚至覺得這是不是個 Joke,根據法新社報導,卡里科說只有他母親對他很有信心,每年都會聆聽諾貝爾委員會宣布得主,卡里科 Karikó 回應說:「我當時只能苦笑一下,因為我從未得到過研究資助,也沒有一個固定的團隊。我甚至都不是一名正式的教授,因為我被降了職,所以我並不抱什麼期望。我回答她說,『這是不可能的』。」
很遺憾的,卡里科的母親在 5 年前離世,沒能看到她真的獲得諾貝爾獎。
聽完卡里科跟韋斯曼的故事,最後我想問問你,如果你轉生成卡里科,你覺得哪個時刻會讓你最想放棄呢?
- 當然是 2013 年,一回國竟然發現連研究室都被清空那時候。
- 應該是罹患腫瘤,丈夫又在匈牙利,學校還要開除我那時候。
- 光是出生在共產時期的匈牙利,我就想放棄了。
等等,要是你放棄,我們就沒有 mRNA 疫苗了耶,你想清楚啊!
歡迎訂閱 Pansci Youtube 頻道 獲取更多深入淺出的科學知識!
參考資料
- https://www.nobelprize.org/prizes/med…
- 《疫苗商戰:新冠危機下AZ、BNT、輝瑞、莫德納、嬌生、Novavax的生死競賽》
- https://learngenomics.dev/docs/biolog…
- https://www.sciencedirect.com/science…



































{kind=link}
{kind=link}
{kind=link}
{kind=link}