


- 文/雅文基金會聽語科學研究中心 研究助理 王璽鈞
當你聽到另一半說「喔,好呀!」時,要如何正確解讀這個回答才能毫髮無傷、全身而退?這個「好」到底是開心的好?不甘願的好?還是我皮在癢的好?要能順利使用口語溝通,聽懂字句意義是基本功,此外我們還需透過其他線索脈絡才能絲毫不差地解讀訊息,了解對方真正的意圖。

喜怒哀懼的聲學特徵
在解讀意圖的過程中,言語調律(prosody)的戲份就十分吃重,它像是聲音的調色盤,讓說話者的情緒一目瞭然。大家可以想一想,聽Google小姐講話跟聽一般人說話有什麼不同?沒錯,就是少了一股「人味」,Google小姐聽起來就像機器人般,講話呆板,讓人摸不透她的喜怒哀懼。而這「人味」就是言語調律,包含了說話者的音調高低、音量大小、語速快慢、重音及節奏。這些元素編譜出的「抑、揚、頓、挫」不僅能抓住聽者的注意力、增進理解,也能讓人掌握訊息的情緒和意圖,對於人際互動的影響力不容小覷[1]。
開心、生氣、害怕、難過等這麼多種不同的情緒裡,我們如何正確解讀呢?難過為什麼聽起來是難過?是有「一點點」開心還是「非常」開心?其實聲音情緒有不同的聲學特徵,如音高、時長及音強等[2]。
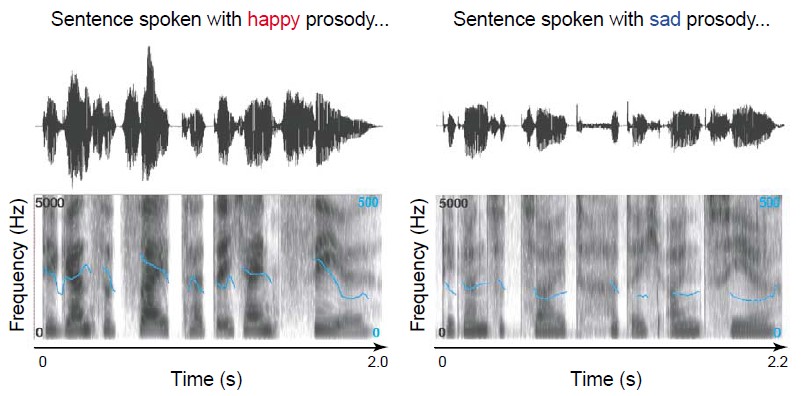
音高(pitch)是指聲帶振動的頻率,也就是基礎頻率(fundamental frequency),而我們對話中的語調(intonation)變化,則是反映在基礎頻率的高低起伏,通常依據講話的情緒或訊息重點而有不同的表現[3]。時長(duration)則是時間性的訊號,是指說話時所使用的時間,花費的時間越短代表說話者的語速越快[3]。最後,音強(intensity)是聲音的大小聲,和聲帶振動的幅度有關,振幅愈大,分貝音量愈大[3]。如圖一所示,「開心」具有較高的平均基礎頻率,此時音高上揚,語速變快,音量也變大;而「難過」平均基礎頻率則較低,語速變慢,音量也會變小。透過這些聲學特徵,我們就可以推論對方的情緒[4]。
情緒語調處理三階段
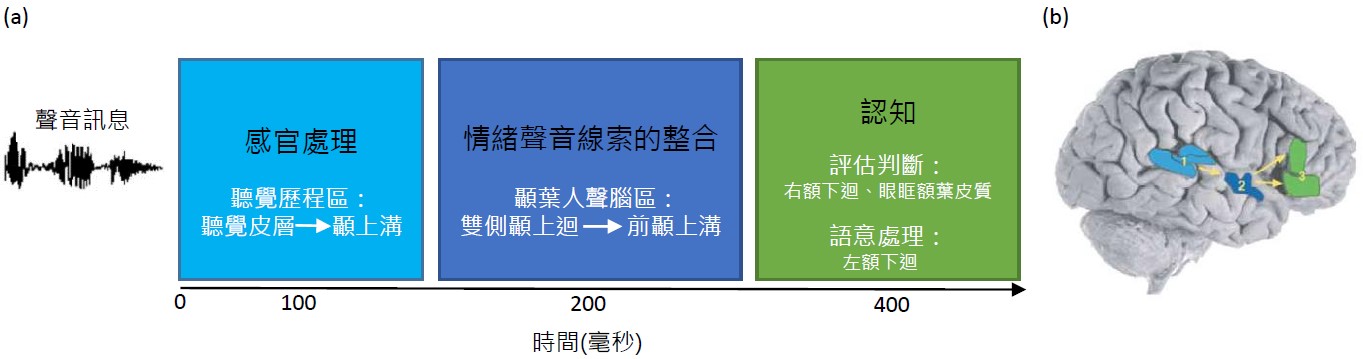
那麼問題來了,那為什麼還會有「白目」或「讀不懂空氣」這樣的字眼存在?是故意唱反調嗎?還是在抓取這些情緒語調的訊息上面有困難呢? 其實若想正確解讀情緒語調是需要生理和認知活動參與進行整合分析的[5]。如圖二所示,有研究假設提出情緒語調的處理包括三個階段[4]:
- 第一階段「感官處理」:
聽覺系統接收聲音刺激後,將訊號透過丘腦(thalamus),送至聽覺皮層,並由聲音特質決定活化的神經元數目與位置。處理後再將訊息送往與情緒辨識有關的腦區—顳上溝(superior temporal sulcus)。 - 第二階段「情緒聲音線索的整合」:
處理語言及伴隨的言語調律,整合情緒相關的聲音線索。這個迴路由顳上迴(superior temporal gyrus)傳至前顳上溝(anterior superior temporal sulcus),被稱為「顳葉人聲腦區 (temporal voice-selective area)」,是對人聲特別有反應的區域。 - 第三階段「認知」:
訊息繼續傳遞至前額葉進行後續認知的歷程處理,例如情緒語調的判斷會涉及右額下迴(right inferior frontal gyrus)與眼眶額葉皮質(orbitofrontal cortex),而情緒語調的語意整合則涉及左額下迴(left inferior frontal gyrus)。
聽力會影響情緒解讀
由上述可知,情緒語調辨識涉及多個處理階段,若任一環節受阻,則可能導致無法準確解讀[6]。舉例來說,若有聽知覺上的限制,像是聽力損失,在辨識情緒語調的第一階段就可能得花些心力。不同語音的能量可能集中於不同的頻率帶,例如ㄙ、ㄑ屬於高頻音,ㄨ則為低頻音;而語調通常則透過低頻來展現。聽損者可能由於某些頻率的聽力受限,使得語音訊息的接收不完整,導致他們的頻率區辨能力不如聽力正常者,進而影響情緒語意和語調的理解[8]。
雖然聽損者可以透過助聽器或人工電子耳幫助他們知覺聲音,但這些輔具仍然有頻譜解析(spectral resolution)的限制,讓接收聲音的解析度不佳[6],增加情緒辨識的困難,進而影響生活品質[7]。
最近因防疫需要,時常得戴著口罩說話,不僅遮蔽了說話者的臉部表情,也讓聽覺線索的傳遞更困難[9],使得重音或語氣的辨識更不易,例如一不小心就有可能將語氣上揚的疑問句誤聽為語氣平穩的直述句,讓人答非所問,好不尷尬。由此可見聽力在情緒辨識上的重要性。
運用其他線索解碼情緒
在溝通的同時,我們會利用語言溝通與非語言溝通交錯進行傳遞[10],除了語言本身的意義外,也強調了言語調律的重要性,除此之外,我們也常會透過視覺的線索—臉部表情、眼神接觸、肢體動作進行情緒的理解和表達。要進行有效的溝通與情緒解碼,這些語言和語言外的要素都是缺一不可的[10],下次和別人聊天時,除了注意文字訊息外,也別忘了眼耳併用,不要放過其他線索,一次掌握對方的弦外之音,言外之意。
參考資料
- 鄭靜宜(2011)。語音聲學。台北:心理。
- Murray, I. R., & Arnott, J. L. (1993). Toward the simulation of emotion in synthetic speech: A review of the literature on human vocal emotion. Journal of the Acoustical Society of America, 93(2), 1097-1108.
- 謝國平(1998)。語言學概論。台北:三民。
- Schirmer, A., & Kotz, S. A. (2006). Beyond the right hemisphere: Brain mechanisms mediating vocal emotional processing. Trends in Cognitive Sciences, 10(1), 24-30.
- Rosen, S., & Howell, P. (1993). Signals and Systems for Speech and Hearing. Journal of the Acoustical Society of America, 94(6), 3530.
- Shannon, R. V., Zeng, F. G., & Wygonski, J. (1998). Speech recognition with altered spectral distribution of envelope cues. Journal of the Acoustical Society ofAmerica, 104(4), 2467-2476.
- Luo X., Kern A., & Pulling K. R. (2018). Vocal emotion recognition performance predicts the quality of life in adult cochlear implant users. The Journal of the Acoustical Society of America, 144, EL429–EL435.
- Chatterjee, M., Zion, D. J., Deroche, M. L., Burianek, B. A., Limb, C. J., Goren, A. P., Christensen, J. A. (2015). Voice emotion recognition by cochlear-implanted children and their normally-hearing peers. Hearing Research, 322, 151-162.
- Goldin A, Weinstein BE, & Shiman N. (2020). How do medical masks degrade speech perception? Hearing Review, 27(5):8-9.
- 胡愈寧、林美蓉、吳青蓉、張菁芬(1994)。溝通與表達。台北:華立。

































