
(編註:)延續前篇關於「健康資料加值應用」與協作中心的介紹說明,本篇將再度回到健康與醫療資料議題的基礎上,從「電子病歷」與「智慧醫療」兩個面向的發展,了解當前政府預計推動的電子化醫療政策為何。
電子病歷
由於國內醫院病歷電子化的發展已經相當普及,在落實「全人健康照護」政策目標下,我國政府於 2008 年推動電子病歷實施計畫 。主要是針對協助各醫療院所推動電子病歷,使得醫療院所醫療作業資訊化及病歷電子化,降低管理成本,達到無紙化。
雖然醫療法第 69 條並無規範醫療院所一定要製作電子病歷,但是從下表中,我們可以看出臺灣目前病歷電子化的情況已經達到 8 成,病歷電子化已經是臺灣未來的趨勢。

不過對衛生署而言,最重要的目標是促進院際電子病歷互通。因此在 2010 年推動加速醫療院所實施電子病歷系統計畫,內容包括鼓勵及輔導醫療院所發展醫療作業資訊化、病歷電子化,更進一步推動院際電子病歷互通,減少病患重複檢驗檢查及用藥,並提升醫療資源運用效能。簡而言之,電子病歷的推行主要是下列三大階段:

院際電子病歷互通指的是在病患同意下,可以將其在 A 醫院的醫療影像及報告、血液檢驗、門診用藥紀錄或出院病歷摘要開放給 B 醫院使用,不僅節省民眾在申請醫療影像複製上的時間和金錢(一般情況下,要支付給醫院基本費/管理保存費與複製成本)、避免重複性檢查與用藥,且可以加速醫師診療決策時間,能夠盡早做出治療處置。而醫師只有在病患同意下才能調閱資料。
傳統病歷申請過程,民眾必須持身分證、第二證件(健保卡、駕照等),如果是申請病歷紀錄,則必須先看過門診醫師,意思就是必須要經過掛號、候診的時間,於門診時和醫師討論要申請的種類和件數、填寫病歷複本申請單,為申請種類不一,像是中文出院病歷摘多要 650 元,除了要支付當次門診掛號費(依醫療院所規模不一,150-200 元),另外還需要郵寄費。如果只是檢驗報告,可以直接到醫院服務台填寫病歷複本申請單,一份大約是 10 元。那如果是要申請 X 光片,按區域醫院的作法是,先到服務台填寫申請單,於預約時間到放射科申請,一片光碟通常是收 200 元,等候時間 30 分鐘到一小時不等。
電子病歷優於傳統病歷申請的地方則在於節省時間和一部份的金錢,並愛護地球(無紙化)。現行電子病歷主要分成兩種,一種是可攜式電子病歷,另一種是跨院電子病歷交換。可攜式電子病歷與傳統病歷申請類似,只是改成單一窗口,民眾不需要在門診、服務台、放射科或其他專科跑來跑去,只需要出示雙證件向服務台申請,醫院將電子病歷列印出來給民眾。然而還是需要複製病歷的費用,但是就不需要另外支付掛號費,並節省申請時間。
跨院電子病歷交換,現行政策主要指的是醫療影像和報告的交換、血液檢驗及用藥紀錄,民眾只要填寫書面同意單(七天內有效),表示同意乙醫院調閱自己的資料,在民眾健保卡和醫事人員卡雙卡同時插入後,乙醫院的醫師便可以從衛生署影像交換中心下載民眾在甲醫院的醫療報告與影像。或是從衛生署的電子病歷交換中心下載用藥紀錄和出院病歷摘要。
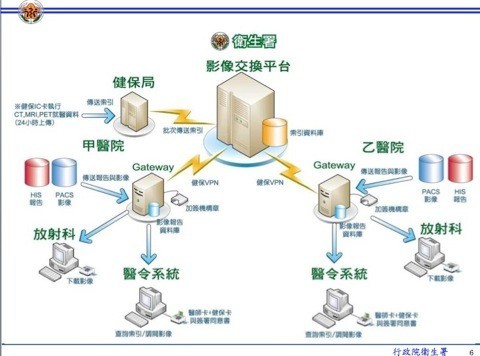
以下這張圖是闡述病患的醫療影像資料是如何流傳的。各醫院將影像資料放到一個 Gateway,而這個 Gateway 會儲存這些影像資料,如果民眾要申請可攜式電子病歷,醫院服務處的人員就會連線到 Gateway 下載。這些 Gateway 的索引檔(即民眾的醫療影像和報告的索引檔)會上傳到衛生署的影像交換平台,在病患的同意下,乙可以至影像交換平台查詢該病患是否在一年內有做過這些檢查。並可直接透過影像交換平台,至甲醫院進行下載醫療影像報告。
智慧醫療
在邁入 21 世紀之後,電腦科技成為主流,現今電子病歷制度已經運用到部份的雲端科技,我們可以想見未來健康資料庫的應用可能也會雲端化,所有的資料庫資料都會存在所謂的「醫療雲」上。到時候民眾要看診,也不需要帶健保卡,當場做指紋、眼角膜判定便可看診,醫師也不需要向其他醫院調閱你之前在其他醫院的看診病歷,只需要透過網路連線,從網路上的虛擬空間讀取你從小到大的所有醫療診斷記錄、X 光照影、藥物過敏史等等,便可以了解你個人的身體狀況,最近的服藥記錄,或甚至是以後就透過 SKYPE 等電腦視訊系統看診,民眾也不需要大老遠跑回家。或者,以後的老人照護制度,老人家不需要進入老人安養中心以獲得醫療人員、護士的 24 小時的照護和監測(以避免有任何不測),老人家可以待在他最熟悉的家裡或住所,身上穿健康衣或是戴偵測手環,一旦呼吸停止、心跳暫停等危急狀況,該健康衣或手環便可以向附近衛生所或是醫院發出訊號尋求支援。
然而健康與醫療資料庫的加值與應用必然有其相對的風險存在,像是病歷資料可能會外洩、遭受駭客入侵等等,因此本公民論壇的目的便是在於,當了解到健康資料庫現行以及未來可能成果和其所可能帶來的風險,令民眾在衡量孰輕孰重後,能有一更清晰的圖像。【待續】
* 補充:什麼是「雲端運算」(Cloud Computing)?
「雲端運算」這個詞彙最近蔚為風潮,相關的討論層出不窮。依據美國國家標準與科技局(National Institute of Standard and Technology)的定義,雲端運算指的是一種使用者可以隨時隨地利用載具,透過網絡連線進用各種服務(如網路、伺服器、儲存空間、應用程式)的新運算模式。
資料來源:本文節錄自《健康與醫療資料的加值應用公民論壇議題手冊》
作者與編輯群:呂宗學、邱伊翎、黃柔翡、馮瑜茜、呂家華、李宜卿、孫語辰
審定:呂宗學、林子倫、邱伊翎、徐子涵、陳再晉、黃旭明、滕西華 ![]()
健康與醫療資料的加值應用公民論壇,希望促成社會公眾對「健康及醫療資料運用及加值」議題進行理性、知情的討論,形成公共意見以作為決策的參考。PanSci將在:
- 8/17 的 PM 7:00-8:00
- 8/17 的 PM 9:00-10:00
- 8/18 的 PM 7:00-8:00
- 8/18 的 PM 9:00-10:00
四個時段各舉辦一場線上論壇,歡迎報名參加!
論壇一:政府現有健康相關資料之加值,是否須先經個人同意或立法授權?
論壇二:健康資料庫加值應用之現況是否侵犯或有未能保護個人資訊自主及隱私之疑慮?
論壇三:健康資料庫加值應用衍生利益之歸屬:公有?共有?私有?
論壇四:總體討論(後續該怎麼監督)
>>前往健康與醫療資料的加值應用公民論壇的【網站】、【Facebook】、【線上報名表單】








































