《比宇宙更遠的地方》及其背後的科學——你不可不知的科幻動畫(一)
我們距離宇宙有多遠?如果你開車往正上方的天空行駛,以高速公路的行車速度,一個小時就能抵達外太空。
大氣層與外太空的分界線,目前並沒有全球統一的認定標準。國際航空聯盟(Fédération Aéronautique Internationale, FAI)將其定為海平面上方 100 公里處;美國空軍、以及美國國家航空暨太空總署(NASA)則以海拔 80 公里為交界——這麼近的距離,根本簡簡單單開車就到了呀!(不要瞎掰好嗎)
相較於宇宙的近,南極雖然在地球上,但是對絕大多數人來說,距離卻相當遙遠。2007 年,日本前太空人毛利衛被招待至南極的昭和基地後,講了句感想:「只要數分鐘就能抵達宇宙,到昭和基地卻要花數天;簡直比宇宙還要遠呢。」《比宇宙更遠的地方》(宇宙よりも遠い場所)這部動畫作品,描述的就是一群高中女學生努力突破現實困難,來到比宇宙更遠的地方——南極的故事。
《比宇宙更遠的地方》宣傳照。 (以下微科學劇情雷)
日本的南極觀測任務 《比宇宙更遠的地方》並不是刻板印象中的科幻片,劇情中沒有機器人、沒有太空船,也沒有外星人或宇宙基地;但它確實是有著紮實科學背景設定的幻想故事。主角們搭乘的破冰船企鵝饅頭號,設定上為退役的日本碎冰艦第二代「白瀨」(しらせ)改造而成;實際上,這艘日文名字發音跟主角之一相同的船,現今仍在服役,支援著日本的南極觀測任務。
至於動畫中,位於南極的昭和基地,也是完全參考自現實世界的昭和基地;其於 1957 年開設,目前仍為日本在南極的主要觀測基地。與劇情類似,南極地域觀測隊會不時跟日本當地,如博物館和各級學校等單位,進行衛星連線科普活動 。以年為單位,每個梯次的觀測隊員約在百名以下,包括公家機關成員,以及民間專業人員;其中又區分成在南極待上一整年、每年二月交接的越冬隊,和只駐紮夏天期間的夏隊,以及少數的同行者(如記者、外國科學家、大學生等)。
可惜的是,到目前為止,南極地域觀測隊從來沒有女高中生參與;最年輕的成員為大學生。過去,女性觀測隊員鳳毛麟角,近年才有逐漸增加的趨勢,最多可達十幾人;而且,一直要到 2018 年,才首度有女性擔任隊長職務 。在《比宇宙更遠的地方》裡,重要幹部/角色幾乎都是女性,一方面或許是為了跟主角們的性別身份呼應;另一方面,可能也是一種期許吧?
南極的天文台 在動畫劇情中,觀測隊的重要目標,乃在南極內陸建立天文台;而現實世界裡,日本目前並沒有這樣的計畫,但確實有透過國際合作架設天文台的未來展望。
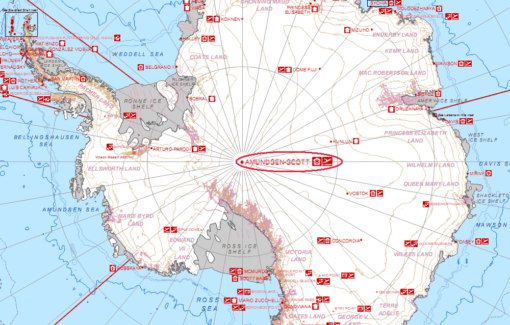
現在於南極洲運作的天文望遠鏡,最有名的當屬美國阿蒙森–斯科特南極站(Amundsen-Scott South Pole Station)的南極望遠鏡(South Pole Telescope, SPT);它位於地理南極、海拔 2800 公尺的高原上,口徑 10 公尺,可觀測的電磁波段包括了微波、毫米/次毫米波,也是事件視界望遠鏡的參與機構之一。事件視界望遠鏡是全球性的大型望遠鏡陣列計畫,協調世界各地電波望遠鏡獨立觀測特定目標,再將數據整合,形成口徑等同地球一樣大的虛擬望遠鏡。2019 年事件視界望遠鏡所發布,轟動全球的超大質量黑洞 M87 觀測照片,即有來自南極望遠鏡的貢獻。
為什麼選擇在南極內陸進行天文觀測? 為什麼在南極建立天文台這麼重要呢?要做,在自己國家做不就好了嗎?《比宇宙更遠的地方》又為何要設定成,去南極內陸建天文台,而非建在靠海的昭和基地?事實上,位處南極洲中央的南極高原,擁有其他地方無可比擬的天文觀測優勢 。
因為空氣中的水分子會吸收電磁波(程度依波段而異),所以觀測某些特定電磁波段的望遠鏡,必須建在特別乾燥的地方,避免觀測結果受到水氣影響。南極氣候嚴寒,空氣中的水份極少;加上內陸高原平均海拔 3000 公尺,空氣稀薄又乾淨――這些因素都讓南極內陸的天文觀測,可以最大程度地避免地球大氣層的干擾。
不僅如此,在地理南極附近,每年有六個月的永夜,星星亦不會東升西落――意味著,天文台可以不間斷地連續進行觀測、獲取數據,不會受到打擾。
阿蒙森–斯科特南極站座落在地理南極(紅線圈起來處);右上方黑框處可見昭和基地(Syowa)。圖/Wikipedia 南極的科學研究 不只黑洞觀測,南極的許多科學研究計畫都得到豐碩成果。1982 年,日本在昭和基地的越冬隊發現,南極上空的臭氧隨時間快速減少,甚至一度懷疑儀器出了問題。兩年後,觀測隊成員在研討會中發表調查結果,成為史上第一份南極臭氧層破洞的報告;《蒙特婁議定書》也才因此誕生,要求禁用氟氯碳化物等破壞臭氧層的化學物質。
除了大氣層臭氧濃度的變化之外,南極也對我們理解遙遠過去的地球氣候貢獻卓著。眾所周知,南極大陸地表覆蓋著深厚的冰層,最厚處甚至超過 4 公里;它們是在漫長的歲月之中,逐漸堆積形成。換言之,在冰層的越深處,年代越久遠。藉由挖掘深層的冰柱樣本(稱為冰核,Ice Core),科學家就能分析出隱藏在冰裡的昔日氣候資訊,如當時氣溫和大氣的二氧化碳濃度等。目前人類挖出的冰核,最深超過三公里,可回溯至接近八十萬年前。
作為人類最後才踏足的大陸,南極帶給我們許多科研調查上的驚喜。至 2016 年為止,美國在南極找到約 22000 顆隕石,日本也回收超過 17000 塊隕石,對地質學研究貢獻甚鉅。在生命科學,如生態系觀察、環境污染調查、南極湖底苔蘚植被的發現等等,皆不容小覷。在物理學,目前有微中子(質量極小又難以和其他物質作用的次原子粒子)的大型觀測計畫正在進行。除了上述議題之外,還有其他諸多研究領域或主題,也在南極展開。
至於台灣,雖然本身並沒有南極的研究站,但科研人員可藉由跨國合作前往南極進行研究;如中央大學太空科學與工程學系的林映岑老師,就曾前往南極長駐一年 ,是目前國內唯一擁有南極研究經驗的女性科學家。此外,台灣也有為南極的部分研究設施貢獻過心力,像是事件視界望遠鏡的調校 、台大物理系暨天文物理所的陳丕燊老師推動的微中子天文台「天壇陣列 」(Askaryan Radio Array, ARA)等。
一起去南極吧! 植基於現實中的南極科學考察活動,《比宇宙更遠的地方》以四位女高中生為主角,展開她們青春的一頁。主角們在破冰船上、在南極的生活種種,都顯示出動畫製作公司花了相當大的心力,做足功課,才能有如此忠實的呈現。
動畫中,科學性的設定不單是用來搭配全劇的布景,甚至也可以說是讓故事更顯真實的重要點綴:包括研究計畫可能面臨的人力、物力短缺,和計畫執行前的準備和訓練等,劇情中都有一定篇幅的交代。雖然就自己身為科學研究人員的角度來說,會覺得科學內容的說明太少,不夠過癮,但這畢竟是給大眾看的動畫――就科學調查活動的呈現、角色的塑造、以及劇情的娛樂性等不同面向,個人認為比例拿捏得很不錯。
以南極為目標的主角們,透過一次次的努力,克服困難,想方設法來到南極,還要面對許許多多人際關係的衝突與學習;隨著旅程的開始和結束,她們得到的不只是一段獨特的旅行經驗,也是每個人的成長,和彼此之間的友誼。《比宇宙更遠的地方》曾榮獲紐約時報「2018 年最優秀電視節目獎」;它沒有深奧難懂的設定、沒有燒腦的情節;以溫馨勵志的內容溫暖人心之餘,其細緻的南極生活刻畫,也讓人心神嚮往,恨不得親自去一趟南極了呢!
動畫中的破冰船,第二代白瀨。圖/IMDb 參考文獻



 法國-義大利協同研究基地(French-Italian Concordia research base)的隊員,於5月初時,在南極基地向今年的最後一道陽光道別。從5月到9月的未來4個多月中,南極基地都將處於永夜的狀態下,雖然研究仍持續不墜,但無法補給,各基地都必須自己自足。
法國-義大利協同研究基地(French-Italian Concordia research base)的隊員,於5月初時,在南極基地向今年的最後一道陽光道別。從5月到9月的未來4個多月中,南極基地都將處於永夜的狀態下,雖然研究仍持續不墜,但無法補給,各基地都必須自己自足。 科學家Oliver Angerer解釋:「在這種環境中,所有參與者都需挑戰持續累積的壓力。我們觀察成員們在這種惡劣環境中會如何表現,特別是睡眠方面。協同研究基地的高海拔環境已經會影響睡眠品質了,若再加上少了陽光照射,讓身體要維持正常作息更為困難。」
科學家Oliver Angerer解釋:「在這種環境中,所有參與者都需挑戰持續累積的壓力。我們觀察成員們在這種惡劣環境中會如何表現,特別是睡眠方面。協同研究基地的高海拔環境已經會影響睡眠品質了,若再加上少了陽光照射,讓身體要維持正常作息更為困難。」 資料來源:Farewell to the Sun[2012.05.11]
資料來源:Farewell to the Sun[2012.05.11]