


「自動音樂採譜研究」的重要性
相傳莫札特十四歲時聽到複雜的教堂樂曲,便能默記全曲並寫成樂譜。在這個充滿神秘色彩的故事中,除了隱含人們對音樂「天份」這道門檻的敬畏以外,自動採譜也成為 AI 人工智慧研究者所挑戰的重要夢想。
中研院資訊科學研究所的蘇黎,專攻音樂資訊檢索(Music Information Retrieval,MIR) ,以「多重音高偵測技術」為基礎,發展出自動採譜的人工智慧,以更輕鬆簡單的方式來協助我們學音樂、理解音樂和製作音樂。

目前市場上已經有許多人工智慧在音樂上的應用,例如人們用 Soundhound 音樂識別軟體來搜尋當下聽到的歌,或試聽線上串流平台推薦的歌曲,或透過軟體快速找到自己想要聽的歌。這方面的發展已接近成熟,但主要都是針對「聆聽」的行為。
若想透過人工智慧進一步了解音樂的深層意涵,例如作曲家的創作思維,演奏家的詮釋技法,乃至於樂評家的觀點,那麼,一個擁有像莫札特般卓越音樂聽力,可以協助自動採譜,並將聽見的音樂變成容易親近演奏的完整樂譜的人工智慧,會是關鍵性的一步。
人類如何認識音樂?音高 94 關鍵!
試著哼唱莫札特的〈小星星〉,想起小學教室裡的風琴伴奏,而那架風琴的 Do 還老是走音。在這樣簡單的歌曲裡頭,事實上已經包含了許多複雜的資訊,如速度、節奏、音高、和弦、器樂及人聲的音色等多樣要素,別忘了還有走音的 Do 這個偏差因子。
因此,人工智慧對大編制樂曲如交響樂的自動採譜,必須面對大量且交疊的資訊,難度仍然很高。所以要把聽到的樂曲轉成可以看到的譜,還是要找出其中特徵最穩定,也能決定旋律的關鍵—「音高」。
「音高」為樂曲所有要素中最基本的特徵,樂譜上的資訊,大多與音高有關。
說起音樂訊號的本質,蘇黎認為音高是音樂訊號中的最基本的資訊之一,而音高偵測正是音樂訊號處理的基本技術。
舉個大家都有的生活經驗:當朋友打電話來,有時我們會覺得對方的聲音好像不太一樣。這是因為線路與裝置在訊號傳輸過程中改變了朋友說話的音色,讓我們的聽覺受到混淆。但對方聲音在電話裡的語調,也就是音高,不論是上揚還是下降,並不容易受影響。
因此,我們即使因為雜訊而不認得對方的聲音,但往往還能聽懂對方講話的內容。也因為音高擁有這樣的基本特性,所以如何辨識音高可以說是分析聲音資訊的一項基本技術。

此外,音高資訊並不僅包含絕對音高,還包含音與音相對的關係,甚至是那轉音之時,各種詮釋的可能。
就如同有人唱著〈小星星〉的曲調,即使沒一個音在音準上,我們仍然聽得出這是〈小星星〉的曲調。這是因為我們認得旋律軌跡(melody contour)的樣態,也就是「曲調的起伏」。只要曲調起伏的趨勢與原曲相似,我們就能如 Soundhound 音樂識別軟體一樣聽得出來。
用「多重音高偵測」,記錄人耳辨識困難的合音
音高資訊除了表現於旋律以外,更是伴奏、和聲與對位結構中的基本資訊,也就是「和弦辨識(chord recognition)」與「多重音高偵測(multi-pitch estimation, MPE)」技術。
近年來多重音高偵測技術的發展重點,大多仍集中於西方古典音樂,因為此類音樂的資料庫相對完整,每種樂器的聲響型態較容易標準化,在分析樂曲時就相當便利。但因為西方古典音樂大多有完整樂譜,往往是最不需要這項技術輔助研究的。相反的,大量在缺乏譜例記載的傳唱民謠,需大量人力從事轉譜工作以方便判讀分析,多重音高偵測技術在此時便派上用場,並且能給予譜例之外更多的資訊。
以布農族的祈禱小米豐收歌 Pasibutbut ,也就是著名的「八部合音」(註一)為例。為什麼稱之八部,據說是因為「泛音唱法」(註二),即一個人可以同時唱出兩個音高的聲音,除了唱出基音以外,還增強某一個高階泛音的能量。
但現今所看到音樂學家所整理的譜例,大多仍是記為四部,這是因為演唱的編制確實只有四個聲部:最高音、次高音、中音和低音。至於泛音唱法之下多出的聲部,有些人聽得出來,有些人則感知不到;且不同的錄音版本差很大,很難明確指出是哪八個聲部,各自音高為何。
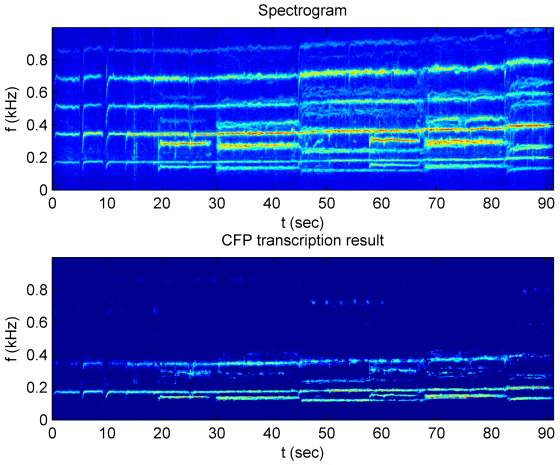
蘇黎透過訊號的時頻圖(spectrogram)資料佐證,可以清楚看見泛音唱法的特徵:每一個聲部都在偶數的倍頻上產生更多能量。經過多重音高偵測(即 CFP transcription result),去掉多倍頻的泛音,除了基音外,也很容易看見第一泛音(基音的二倍頻)的位置上有能量存在,顯示了新的音高成份,演算法呈現的結果證實了泛音唱法的存在。
藉由計算瞬時頻率的技術,也就是「多重音高偵測」,便能把每一個聲部的音高軌跡精準算出,將能協助民族音樂的採譜工作。
音樂視覺化!將視覺和聽覺同步表現
蘇黎團隊目前所研究的「多重音高偵測技術」,以適用於各種音樂訊號為目的,其能有效刻劃出每一種聲響結構,並且將聲響即時轉化成樂譜。
多重音高偵測技術不僅可以應用於民族音樂學等領域的採譜處理問題,它的即時處理以及視覺化能力,也能在教育、娛樂等應用領域中有龐大潛力,將複雜的演奏即時轉為視覺表現。
在聆聽音樂的同時建立視覺與聽覺的關聯,以增強對音樂元素如音高、和弦的認知,是豐盛音樂表演 (enriched music performance)所努力的方向。
為了推廣這個概念,蘇黎與沛思文教基金會將於 2017 年 11 月合作推出《日新‧樂譯》跨界科技音樂會(註三),將現場演奏即時轉譯成樂譜動畫,用科技的語言,述說音樂的故事,透過多媒體動畫影像,讓大家聽得到也看得到音樂的演出。
除了紀錄樂譜,還能做什麼應用呢?
「多重音高偵測技術」對於輔助學習的應用,也不僅限於音樂元素的偵測與視覺化。

精確的多重音高偵測技術為了滿足這個目標,往往需要更精確的頻率與能量偵測演算法,精確描述演奏者在演奏時的音量有多大、抖音怎麼使用、如何控制音長等等。
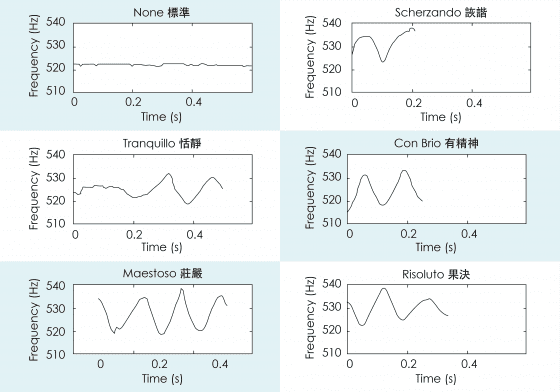
蘇黎與成大蘇文鈺老師、中研院楊奕軒老師合作的工作中,專注探討小提琴演奏者的詮釋,就像同樣的小星星會有很多不同的詮釋版本,可以彈得恬靜、彈得莊嚴、彈得詼諧、彈得有精神,種種不同的表情術語和詮釋方式,都可以從精確的音高偵測演算法中看出端倪。
更進一步地說,未來我們或許能建立一個檢定的標準:當彈奏者把自己的演奏記錄下來,並輸入音樂人工智慧時,就可以和標準演奏做出比對,看看自己演奏得好不好。或是藉由音樂人工智慧的示範演出,讓初學者可以不斷聆聽各種詮釋方式,再去揣摩自己喜歡的演奏表情。這一些都是未來可以從「多重音高偵測技術」中,延伸開發的音樂人工智慧。
如果可以辨識演奏的詮釋方式,則有機會透過音樂人工智慧,從仰慕的音樂高手的精湛演奏中,學習樂器的彈奏技巧。
精確的音高偵測技術不僅可以用來分析古典音樂中的表情術語,另一個有趣的應用是分析搖滾樂中,吉他 solo 複雜的演奏技巧。
帥氣熱血的吉他 solo 往往結合各式不同的演奏技巧,如推弦,滑音、悶音、捶勾弦等等,這是吉他新手在學習抓譜時最困擾的地方。「多重音高偵測技術」有助於辦識出吉他的演奏技巧,把這一些技巧轉變成可閱讀的技巧符號,並記載在樂譜上,讓我們可以更容易去理解彈奏方式,進而模仿演奏者的演奏變化,達成自己想要的音樂學習目標,也是種未來可能發展出的音樂學習系統。

音樂人工智慧會取代音樂家嗎?
當 AlphaGo 問世改寫了圍棋的新面貌,一一擊敗了世界頂尖的圍棋好手,有人感到恐懼、有人感到興奮,無非都是因為人工智慧科技所帶來的改變,但換一個角度想,這不正是把漫畫「棋靈王」的故事搬到現實世界嗎?
當 AlphaGo 變成每個人的藤原佐為,我們就可以像進藤光一樣,即使沒有從小就接觸圍棋,也可以學習到好的圍棋思維。根據類似的道理,我們可以說, 音樂人工智慧科技的進步,其目的並不在於取代音樂家的工作。相反的,我們能看到在不久的將來,這些科技將會被用來增進人類學習音樂的效率,而擴大音樂的學習與消費市場。
正如工業革命讓古鋼琴現代化並大量製造,而孕育浪漫樂派蕭邦、舒曼等作曲家不朽的鋼琴獨奏作品;當代音樂人工智慧的成熟發展將開展另一場革命,不僅讓學習音樂變得更輕鬆有趣,也提供音樂家前所未有的音樂創作思維。
蘇黎不僅是個資訊科學家,也是一個音樂愛好者。深度研究「多重音高偵測技術」,逐步發展出可以正確轉譯樂譜的音樂人工智慧,一方面希望讓專業的音樂創作人擁有更好的創作環境,不用在記載與解析樂譜上耗費太多心力,創作者可以運用更充足的時間來創作嶄新的音樂風格。
另一方面則期望,讓每個想學習音樂的人,可以搭載猶如莫札特的音樂耳。每個人都好像擁有一個虛擬音樂老師,以更輕鬆、簡單的方式,認識音樂的組成結構,降低學習成本,加快學習音樂的速度。讓想學音樂的心,不會隨著年齡增長而有所阻礙,讓全年齡層的人們都有興趣把音樂成為生活的一部分。

延伸閱讀
- 蘇黎的個人網頁
- New Methodology of Building Polyphonic Datasets for AMT
- Ping-Keng Jao, Li Su, Yi-Hsuan Yang and Brendt Wohlberg, “Monaural Music Source Separation using Convolutional Sparse Coding,” IEEE/ACM Trans. Audio, Signal Language Proc. (TASLP), volume 24, number 11, pages 2158 – 2170, November 2016.
- Pei-Ching Li, Li Su, Yi-Hsuan Yang and Alvin W. Y. Su, “Analysis of expressive musical terms in violin using score-informed and expression-based audio features,” International Society for Music Information Retrieval Conference (ISMIR), October 2015.
- Yuan-Ping Chen, Li Su and Yi-Hsuan Yang, “Electric guitar playing technique detection in real-world recording based on F0 sequence pattern recognition,” International Society for Music Information Retrieval Conference (ISMIR), October 2015.
![]()
本著作由研之有物製作,以創用CC 姓名標示–非商業性–禁止改作 4.0 國際 授權條款釋出。
本文轉載自中央研究院研之有物,泛科學為宣傳推廣執行單位





































