- 【科科愛看書】無論何時,只要想到數學就一個頭兩個大?那你肯定還沒看過《數學大觀念:從數字到微積分,全面理解數學的 12 大觀念》!此書從簡單加減到高深微積分,用嶄新的視角連結密碼般的數字和真實人生,循序漸進去探索數學的規律和其中令人讚嘆的美好。讓我們一起將數學砍掉重練,邁向數學偉大的航道吧!
想算連續相乘?先來個驚嘆號!
請問:從 1 加到 100 等於多少?
經過計算,我們得出總和為 5050,並找到一個能算出首 n 個數字之和的公式。
現在換個角度,假設我們想要找出從 1 乘到 100 的乘積,會得到什麼答案呢?這可是一個很大的數目!如果你感到好奇,我可以告訴你答案是下面這個有 158 位數的數目:
933262154439441526816992388562667004907159682643816214685929638952175999932299156
08941463976156518286253697920827223758251185210916864000000000000000000000000
在本文中,我們會了解為什麼像這樣的數字會是排列組合問題的基礎。這些數字可以讓我們得到一些答案,比如說書架上的一打書籍有多少排列方式(幾乎有五億種),或是在發撲克牌的時候至少會出現一對的機率(不低),還有贏得樂透彩的機率(不高)。

當我們從 1 一直乘到 n,會產生出的乘積是 n!,稱作「n 階乘」。換言之:
n! = n × (n − 1) × (n − 2)×· · ·×3 × 2 × 1
舉例來說,5! = 5 × 4 × 3 × 2 × 1 = 120
我認為驚嘆號是個很合適的符號,因為 n! 會成長得非常快,而且接下來我們也會看到它有些令人驚喜的應用。為了方便起見,數學家定義 0!=1,而 n! 在 n 是負數的時候則無定義。
掌握驚嘆號,你就掌握了各種可能
從定義來看,許多人會預期 0! 等於 0,但讓我來試著說服你為什麼 0!=1 這樣是合理的。請注意,當 n≥ 2,n!=n×(n− 1)!,因此 (n-1)!=n!/n;如果我們希望這個論述在 n=1的時候依然成立,則需要 0!=1!/1=1
如下所示,階乘的數目以驚人的速度成長:
0! = 1
1! = 1
2! = 2
3! = 6
4! = 24
5! = 120
6! = 720
7! = 5040
8! = 40,320
9! = 362,880
10! = 3,628,800
11! = 39,916,800
12! = 479,001,600
13! = 6,227,020,800
20! = 2.43 × 1018
52! = 8.07 × 1067
100! = 9.33 × 10157
這些數目有多大?據估計,世界上大約有 1022 顆沙粒,宇宙中大約有 1080 個原子,而你能看到階乘的數目可大的多了。如果你徹底洗亂一副 52 張的牌,可行的方法共有 52! 種。就算在接下來的一百萬年中,每一分鐘裡的每一個人都創造出一個新的組合,你還是非常有可能會得到某種從未見過而且也無緣再見的牌組!
在本文的開頭,你大概注意到了 100! 的後面是大量的零,這些零是從哪裡來的呢?當我們從 1 乘到 100 時,五的倍數和二的倍數每相乘一次就會得到一個零。在 1 到 100 之間共有 20 個五的倍數和 50 個偶數,這表示最後應該會得到 20 個零,但因為 25、50、75 和 100 分別多貢獻 x 一個五的倍數,所以 100! 最後會有 24 個零。
有許多美麗的數字規律運用了階乘,以下是我最喜歡的一個:
1 · 1! = 1 = 2! − 1
1 · 1! + 2 · 2! = 5 = 3! − 1
1 · 1! + 2 · 2! + 3 · 3! = 23 = 4! − 1
1 · 1! + 2 · 2! + 3 · 3! + 4 · 4! = 119 = 5! − 1
1 · 1! + 2 · 2! + 3 · 3! + 4 · 4! + 5 · 5! = 719 = 6! – 1
……
▲ 用上階乘的數字規律。
出門可以穿什麼?讓驚嘆號告訴你

大部分的計數問題本質上可以歸結為兩個規則:加法規則和乘法規則。當你有不同的選項時,加法規則可以讓你知道自己總共有多少種選擇。
舉例來說,如果你有 3 件短袖襯衫和 5 件長袖襯衫,那麼對於要穿哪件襯衫,你就有 8 個不同的選項。一般說來,如果你有兩種物品,第一種有 a 個選項而第二種有 b 個選項,那就是總共有 a+b 個不同的選項(假設 b 選項中沒有任何一個與 a 選項重複)。
如上所述,加法規則是假定兩種各有數個的物品中沒有任何重複。但如果有 c 個物品同時屬於這兩種,這些物品就會被重複計算,因此總數會是 a+b−c 個。
舉例來說,如果班上的學生中有 12 個人養狗、19 個人養貓,而同時養狗和貓的有 7 個人,那麼有養狗或養貓的學生總數會是 12+19− 7=24 個人。再舉一個偏數學的例子,在一到一百之間有 50 個二的倍數、33 個三的倍數,還有 16 個數同時是二和三的倍數(也就是六的倍數)。因此在一到一百之間,總共有 50+33− 16=67 個二或三的倍數。
乘法規則說明如果一個動作包含了兩部分,且執行第一部分有 a 種方式,執行第二部分有 b 種方式,那麼這個動作總共有 a×b 種完成的方式。比方說,如果有 5 件不同的長褲和 8 件不同的襯衫,而且假設我不在乎配色的問題(只怕大部分的數學家可能都符合這一點),那麼總共會有 5×8=40 種不同的搭配。如果我有 10 條領帶,而一組套裝包含襯衫、長褲,和領帶,那麼總共會有 40×10=400 種搭配。
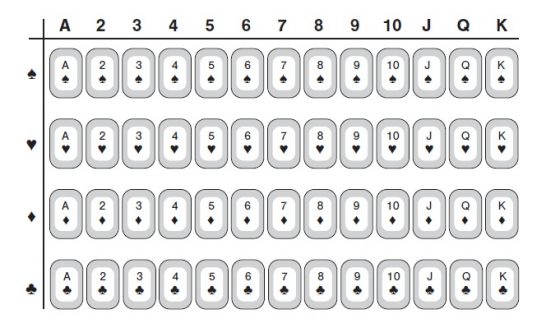
在一副普通的撲克牌中,每一張都是四種花色的其中一種(黑桃、紅心、方塊或梅花)和十三個數值之一(A、2、3、4、5、6、7、8、9、10、J、Q 或 K),所以一副牌裡有 4×13=52 張牌。我們也可以將 52 張牌排成一個 4×13 的長方形,這是另外一種能看出總數是 52 張牌的方式。
用階乘看世界,處處都充滿驚奇
現在讓我們運用乘法規則來計算郵遞區號,理論上可行的五位數郵遞區號有多少個呢?郵遞區號中的每一位數都可以是 0 到 9 之間的任何一個,所以最小的郵遞區號是 00000 而最大的是 99999,也就是總共有 100,000 種可能。但你也可以藉由乘法規則來看出這個答案:你對第一位數有 10 個選擇(從 0 到 9),第二位數有 10 個選擇,第三、四、五位數也都各有 10 個選擇,因此總共有 105=100,000 種可能的郵遞區號。
計算郵遞區號的總量時,數字是可以重複的。現在我們來看看不能重複的情況,比如說要將所有物品排成一排的時候。兩種物品有 2 種排列方式,這點很容易就能看出來,例如字母 A 和 B 的排列方式只會是 AB 或 BA 其中之一;而三種物品則有 6 種排列方式:ABC、ACB、BAC、BCA、CAB 和 CBA。至於四種物品,如果不逐一列出,你能夠直接看出來排列方式總共有 24 種嗎?第一個字母的選擇有四種(A、B、C 或 D),挑好了之後,第二個字母的選擇就剩下三種,然後第三個字母的選擇只剩下兩種,而最後一個字母就只有一種可能了。也就是說總共有 4×3×2×1=4!=24 種可能。一般來說,n 種不同的物品總共有 n! 種排列方式。
在下一個例子中,我們將結合乘法和加法規則。假設某一州設計兩種不同的車牌,第壹種車牌是 3 個字母接著 3 個數字,第貳種車牌是 2 個字母接著 4 個數字,那麼可能的車牌總共會有幾種呢?(26 個字母和 10 個數字統統都可以使用,並忽略相似字型造成的混淆,比如說字母 O 和數字 0。)從乘法規則看來,第壹種車牌的數量有:26×26×26×10×10×10=17,576,000;第貳種車牌的數量有:26×26×10×10×10×10=6,760,000。
既然車牌只可能是壹或貳其中一種(不會都是),那麼加法規則就能表示出車牌的可能總數就是兩數之和:24,336,000。

計數問題(數學家稱為數學組合學的分支)的樂趣之一就是通常一個問題可以用好幾種方式來解決。(我們可以看出再心算的算術問題上也是如此。)上述問題其實可以只用一步就解決,也就是車牌的數量總共有:26×26×36×10×10×10=24,336,000,因為車牌的前兩個字各有 26 種選擇,後三個字也各有 10 種選擇,而第三個字可以是字母或是數字,所以共有 26+10=36 種選擇。

本文摘自《數學大觀念:從數字到微積分,全面理解數學的 12 大觀念》,貓頭鷹出版。