

本文轉載自機器之心〈人們都在說人工智慧,其實現在我們真正做的是智能增強〉
- 智能增強技術有助於提高人類的潛能——通過提高工人生產力、減輕一般任務的工作量以及為我們的生活提供更多方便。本文的作者是 Anupam Rastogi,他是 NGP 的成長期技術投資者,專注於企業中的物聯網、數據與機器學習的交叉領域。本文來自 CB Insights。

自 20 世紀 50 年代以來,人工智慧(The Artificial Intelligence/AI)與智能增強(Intelligence Augmentation/IA)之間的爭論已經持續了半個多世紀。一般來說,智能增強指的是利用訊息技術來增強人類能力。這個想法自 1950 年被首次提出後,現在已經變得無處不在。如今人工智慧越來越多地被用於廣泛描述那些能夠模仿人類功能(比如學習和解決問題)的機器,但它最初所建立的前提條件是:人類智能可以被精確描述,且能夠用所製作的機器進行模擬。人工通用智能(Artificial General Intelligence/AGI)這個術語通常僅僅表示後者,該定義較前者更嚴格。當下存在許多人工智慧方面前所未有的炒作——其近來令人難以置信的增長曲線、無數的潛在應用、及其潛在的社會威脅。
更廣泛的人工智慧定義給一些人造成了困惑,特別是那些或許不太緊跟技術潮流的人。機器學習應用近期所帶來的一些十分顯著的進步有時會被錯誤理解和推斷,使我們以為人類即將取得 AGI 方面的進展、正在逼近為了社會秩序所需要的一切。
智能增強與人工通用智能技術之間可能會有一段持續進步的過程。我在本文中談到,我們所目睹的人工智慧領域的快速進展是來自於機器學習對其產生的強大驅動力。然而,滿足人工智慧——以及人工通用智能——的原始前提條件是大量的、額外的、在近期進展之上的技術突破。智能增強技術有助於提高人類的潛能——通過提高工人生產力、減輕一般任務的工作量以及為我們的生活提供更多方便。我們目前所看到的是機器在任務執行方面的能力提升,在這方面它們幾十年前就勝過人類了。而未來十年中,我們會看到機器學習技術進一步滲透眾多行業和生活領域,推動這種能力進一步地快速提高。
舊聞新炒
如今所使用的許多人工智慧和機器學習演算法是幾十年前發明的。國防機構使用高級機器人、自動駕駛車輛和無人機的時間已將近半個世紀。第一個虛擬現實原型開發於 20 世紀 60 年代。然而截至 2016 年底,沒有一份主流出版物不對人工智慧即將產生的社會影響發表高論。根據 CB Insights 的數據,對利用人工智慧的創業公司的投資資金將於 2016 年達到 42 億美元,僅僅四年就翻了 8 倍以上。
發生了哪些變化?
影響因素有很多,但也有這樣一個共識:最近的許多事態發展,比如近期 Google 翻譯的巨大進展、Google DeepMind 在圍棋游戲中的勝利、亞馬遜 Alexa 的自然會話介面以及特斯拉的自動駕駛功能,都由機器學習的進步所推動,更確切地說是深度學習神經網路——它是人工智慧的一個分支。深度學習理論已經存在了幾十年,但是它開始看到了新一輪的焦點,以及自 2010 年左右開始顯著加快的進展速度。我們當下所看到的現象是一個雪球效應——深度學習在案例與行業中的影響——的開端。
指數般增加的數據可用性、雲經濟規模、硬體能力的持續提升(包括運行機器學習負載的 GPU 性能)、無處不在的連接、低功耗設備的性能以及演算法學習技術的迭代提升,這些都促成了深度學習在許多日常的情況中的可行性與有用性。深度學習以及統計分析、預測分析和自然語言處理方面的相關技術,已經開始被無縫嵌入到我們的日常生活與企業活動之中。
機器和人類
在某些類型的任務上,機器的表現長期以來一直優於人類,尤其是那些與計算速度和規模相關的任務。三位學院派經濟學家(Ajay A. et al)在最近的一篇論文和《哈佛商業評論》上一篇文章假定最近機器學習的進展可以歸為機器「預測」中的進展一類。
「機器的工作原理是機器使用了之前的蘋果圖像中的訊息,來預測當前的圖像中是否有蘋果。為什麼會用『預測』這個詞?預測使用的訊息是你沒有的但必須要生成的訊息。機器學習使用的數據是從傳感器、圖像、視頻、輸入的註釋、或者其他任何能被用比特/二進制(bit)表示的東西。這就是你擁有的訊息,機器用這樣的訊息去填補它缺失的訊息來識別物體,並預測下面會發生什麼。這是你沒有的訊息。換句話說,機器學習是一種預測技術。」
完成任何的主要任務都涉及這幾個要素:數據收集、預測、判斷和行動。人類仍然在基於判斷的任務(廣義)上遠超機器,而且 Ajay 等人假設這些任務的價值會隨著機器學習帶來的預測成本下降而增加。
過去幾年中,在深度學習的驅動下,雖然已經有了能夠展示類似人類軟技能的機器,機器在這些領域的能力幾乎無法達到「預測」中的水平。下面是一些人類擅長的領域,讓機器來模擬這些技能可能需要的新技術突破。
.學會學習:最近機器學習使用中一些驚人的成果包括,觀察人類在多種實例任務中的行為(這種在手問題輸入和輸出的大數據集),同時「學習」使用深度神經網路方法。
.常識:人類擅長運用「常識」,即用一種不加開放思考或無需大數據集的通用方法來做出判斷。在這個領域,除了在使用深度學習處理自然語言任務上有大進展外,機器相對來說還處在初步階段。研究常識推理的科學家估計機器想要運用常識就需要其他新的技術進展。我們(或者我們的孩子)在和 Alexa 或 Siri 時都要面對這個問題。
.直覺和歸零:人類大腦擅長直覺和歸零,例如從一個非常大的復雜又模糊的選擇集合中發現某個事實、想法或者行動過程。學界一直有人在嘗試做將直覺帶給機器的研究,但是在這個維度上的機器智能還普遍處於初級階段。
.創造力:雖然有很多機器已經能生成一些和人類藝術大師的作品難以區分的作品,但它們在很大程度上還是基於學習這些大師已經創造出的模式。真正的創造力需要為問題生成之前從未見過的全新解決方案或真正創新的藝術成果。
.共情:理解情緒、價值系統、設置願景、領導力和其他仍然還是人類專屬的軟能力。
.多功能:同樣一個人可以合理地執行許多人物,比如拿起盒子、駕駛汽車去工作、帶小孩和發表演講。目前的機器和機器人都還是為特定的任務而打造的。
IA and AI
根據以上的總結,我們可以得知:機器已經在學習(或者被稱為「預測」)的技能方面取得了長足的進展,它們進入了模仿「人類」真正的技能的早期階段。我們建議的分類方式是:將預測、第一階段的機器學習以及需要人類參與的自動化功能(human-in-the-loop automation capabilities)歸為「IA」技術。這些技術通常是使用機器獨有的能力(處理巨大數據集的能力)來有效地增強人類能力,系統最終的輸出通常還是由設計和訓練它們的人來決定,因為系統設計者會提供一些與機器互補的技能。
從根源上講,很容易把它與 AGI 弄混淆,所以我們使用了術語 AI 來描述我們在前面提到的機器擁有的那些屬於人類的判斷、學習和具備常識的能力以及具有先天創造力和同情心的特徵。對於強大的 AGI 而言,這也許只是它的一部分,但是要實現復雜的工作流程的全自動化就需要具有大多數這些技能的機器。
明確了這些概念以後,我們就可以知道如何對當前或者即將出現的那些可能會影響我們日常生活和工作的技術進行分類了:
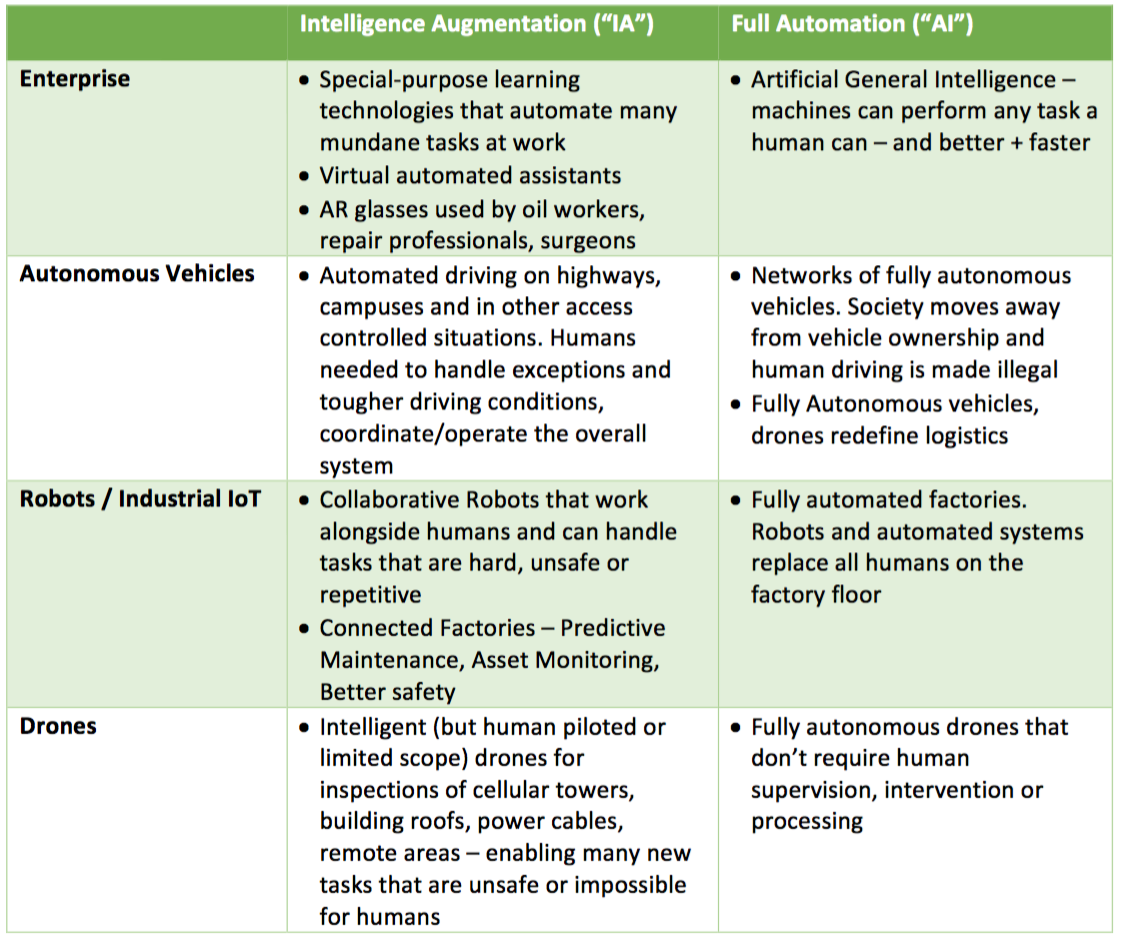
IA 和 AI 帶來的影響
有一個眾所周知的諺語:「我們總是更傾向於在短期內高估技術產生的影響,而在長遠上低估它」。這也被稱為「阿馬拉定律(Amara’s Law)」,人們經常用下圖來表示它。
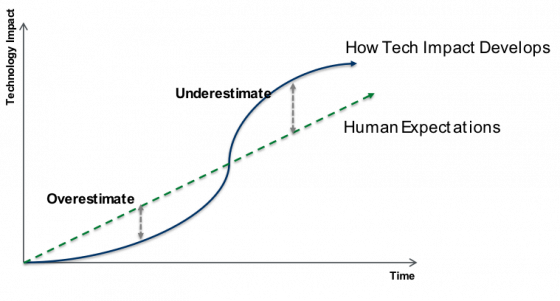
我們可以在這個圖上看到,這條曲線在任何一個軸上都沒有刻度。對於曲線開始處的任何一點,我們不能準確地知道它距離拐點有多遠。但是這條曲線確實說明瞭一個很重要的趨勢——一項新技術的影響在其初始階段十分緩慢,然後隨著技術的發展和市場的大規模採用,該技術的影響顯著變大,最終趨於飽和。人們對於市場預期通常都會忽視這個趨勢。然後,當進入了所謂的著名的「市場炒作周期」,人們對於技術初期影響的預期遠遠超過了技術的真實影響力,因此,人們就會陷入一種失望的境地。隨著技術的影響繼續擴大並且達到一種較大的規模之後,該技術會達到生產率的巔峰。
我相信我們今天所看到的有關於術語「AI」的那些重大的發展和認知其實是「IA」曲線的上升階段,其中使用人工神經網路的深度學習(以及前面提到的一些驅動力如硬體、數據 、雲經濟學、連接性和其他演算法上的進步)正在推動我們走向該曲線上拐點。在許多情況下,相對於回歸(regression)和其他統計工具以及基於規則的系統和人工編碼實現的邏輯等現有「預測」方法而言,深度學習進行了進一步的提升。機器學習通過提高模型精度,增加處理數據能力以及提高對輸入的適應性而推動了發展的速度。
由於機器智能仍然存在上述限制,所以我認為全自動化技術的發展應該是一條全新的曲線。並且我相信我們還處於這條曲線的早期階段。
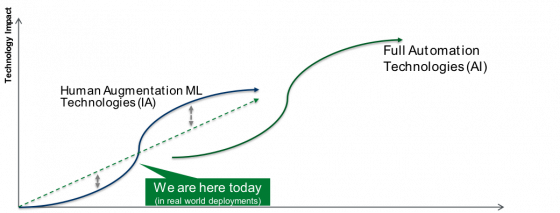
之前已經有多個和 AI 以及奇點(singularity)相關的並且預測不準確的炒作周期了。許多 AI 先驅在 20 世紀 50 年代的早期認為,具備人類所有能力的機器將在十年或二十年之內就出現。這個目標沒有實現的原因不是因為沒有足夠強大的計算能力,而是在多個新的維度上的科學還沒有突破。然而這種根本性突破的時間很難預測以及調整。根據斯史蒂芬.霍金所言,截至到 2015 年,「人工智慧研究員還不能明確什麼時候可以建造出擁有或超過人類的 AI 機器。」
我們可能正處於對於「AI」進行炒作的巔峰階段。然而,IA(如同上邊定義的那樣)提供了一個 5 至 10 年的巨大的投資機會。人類和機器正處於一個互補的階段,他們都有一些不同於對方的卓越的才能。這表明人類能夠專注於他們獨有的技能同時還可以享受鍛煉的樂趣,而機器專注於處理大多數那些不需要人類的判斷力,創造力和同情心等能力就能完成的常規任務。目前有很多文章已經寫了關於 IA 技術將會引起工作和勞動的性質的變化,並且這些變化並不容易。這篇文章就很好地進行了總結:「你使用機器的能力將決定你未來的薪資。」
即時創新和投資機會在何處?
我相信智能增強技術(運用深度學習以及其他機器學習技術實現人工增強自動化)在中期階段的影響比多數人認為的要大,而全自動化的影響則遠遠超出近期相關報導中指出的範圍。
本文無意揣測人工通用智能(AGI)是否還遠在十年或百年之後,亦非討論其將成為對社會的威脅與否。我的立足點在於,你是否對正在進行的投資或者即將創立的公司亦或項目有著五至十年的大規模願景。由機器學習推進的智能增強或人類增強技術具有立竿見影且顯著的價值,況且,在這條商業和社會成功之路上鮮有阻力,可謂是一片坦途。
一如傳統的 B2B 模式,我們尋找的方案是止痛藥而不是維他命,不僅能夠做到解決明顯的現有痛點,展示其強勁的投資回報率,與現有的工作流程高度合拍,還能與企業中買方、用戶和協調人三者利益一致。在這個領域,我保證有人參與的智能技術(智能增強)將有助於提高整體生產力、優化投資成本、提供個性化解決方案、或者助力為客戶提供新的產品。
機器學習技術正被應用於各大垂直產業的許多方面。這是一個關乎整體投資立論的全景話題(至少是獨立於其中),但我們可以通過一個簡明的列表來窺見一斑,看業內如何通過機器學習這一優勢來增強人類自身的能力、提高生產力以及優化資源使用方式。
.企業——完成單調重復任務的機器人助手將更具功能性,並將在十年之內更加深入企業各個方面。使用增強技術實現的可穿戴式設備將有助於順利完成危險或者成本高昂的工作。
.生產製造——合作型的智能機器人可以安全地與人類共事,並且完成那些複雜高危或者重復性的勞動,從而提高生產效率。
.交通和運輸——各大科技公司和傳統製造商們正在就自動駕駛汽車開發進行一場公開而激烈的角逐。而一般駕駛情況下的減少駕駛員工作量的相關技術在短期內其收效是更可預見的。比如:高速公路,降低因人工駕駛車輛造成的誤操作率和交通意外,改善交通車流量及提高燃料使用效率。假以時日,完全自主的生態保障系統將改變都市生活結構,並隨之帶來更多衍生發展機會。
.醫療保健——機器學習技術基於更為廣泛的數據庫,從而有助於醫療人員提供高精度,實現個性化診療。
.農業——各類農用機器人、作物優化技術、自動灌溉技術以及蟲害預警系統將有助於大幅提高農業生產力。
由一個傑出學術團隊主持進行的百年人工智慧研究最近公佈了一份平衡報告,該報告對橫跨多領域的機器學習技術作了很好的總結和展望。CB Insights 則整理了廣泛應用於各行業創新初創公司的深度學習的各項技術。
到了術語更迭的時候了
由於人工智慧的範疇已經遠遠超出了其在科技工業的既有領域而滲入到各大傳統行業當中,它開始觸及許多並不深諳人工智慧科技相關術語的普羅大眾。
我們最好謹慎地使用「人工智慧」這個術語。為避免混淆,減小不利趨勢和監管的風險,以及更好地認知即將到來的術語更為豐富的時代,我們應該使用例如「智能增強」(IA)這類的術語來指代近期使用機器學習技術所取得的先進成果。我認為智能增強可以更好地闡釋人類與機器的共生關系,而現有技術的影響力正取決於這種關系。之所以這樣提,是因為我們不乏先例。隨著機器變得越發無所不能,從前被認為需要智能的情形就會從人工智慧的定義中清除。比如,光學字元識別(OCR)曾被認為是一種人工智慧科技,但它如今已相當普遍,並不在人工智慧考慮範圍之內了。
還是把人工智慧這個詞用做描述全自動技術吧,那些我們已經論證過的,那些讓我們糾於現狀卻不甚明朗的技術。而與此同時,我們更應該抓住因為智能增強的高歌猛進而帶來的機會。






































