


前不久,在人工智慧領域發生了兩件大事,一個就是是偉大的人工智慧先驅馬文 ·明斯基教授逝世,一個是 Google AlphaGo 擊敗歐洲圍棋冠軍,職業圍棋二段樊麾。(2016/3 編按:2016年3月,在一場五番棋比賽中,AlphaGo於前三局以及最後一局均擊敗頂尖職業棋士李世乭,成為第一個不藉助讓子而擊敗圍棋職業九段棋士的電腦圍棋程式。)

馬文·明斯基教授是幾乎見證了從人工智慧作為一門學科的興起直至今日成就的所有大風大浪的人,或者可以說教授本人就是這些大風浪的前鋒,他對人工智慧發展的影響意義十分深遠。而 Google AlphaGo 此次取得的成就,也可以算是人工智慧領域一次里程碑式的創舉,它的成功標誌著人工智慧領域又進入了一個新高度。
這篇文章,我們將從馬文·明斯基還是哈佛大學本科生的時候講起,一直到今日 AlphaGo 的勝利,梳理一下人工智慧是怎樣從初見萌芽一步一步走到今日的輝煌成就的。

要是從宏觀的角度來講,人工智慧的歷史按照所使用的方法,可以分為兩個階段,分水嶺大概在 1986 年神經網絡的回歸——
在前半段歷史中,我們主要使用的方法和思路是基於規則的方法,也就是我們試圖找到人類認知事物的方法,模仿人類智慧和思維方法,找到一套方法,模擬出人類思維的過程,解決人工智慧的問題。
後半段的歷史,也就是我們現在所處的這個時期,我們主要採取的方法是基於統計的方法,也就是我們現在發現,有的時候我們不需要把人類的思維過程模擬出一套規則來教給計算機,我們可以在一個大的數量集裡面來訓練計算機,讓它自己找到規律從而完成人工智慧遇到的問題。
這個轉化也可以用一個形象的例子來描述,就像我們想造出飛機,就觀察鳥是怎麼樣飛的,然後模仿鳥的動作就行,不需要什麼空氣動力學什麼的,這種思想在人類歷史上也被稱為“鳥飛派”。但是我們都知道,懷特兄弟造出飛機靠的是空氣動力學,而不是仿生學。
不過我們不能就因為這一點就笑話人工智慧前半段各位研究人員和前輩的努力和心血,因為這是人類認知事物的普遍規律,其實現在也有不少人會認為,電腦可以讀懂文字、看懂圖片靠的是依靠和我們人類一樣的認知過程。

在研究基於規則的探索中,人工智慧經歷了三個主要階段——興起、繁盛和蕭條。會有這樣的過程,一個重要原因是基於規則方法的局限性。好了,那我們就先扒一扒這段歷史。
一、萌芽階段
人工智慧的萌芽時期大概出現在 20 世紀中葉,第一位需要介紹的人物便是馬文·明斯基(Marvin Lee Minsky)。明斯基於1946年進入哈佛大學主修物理專業,但他選修的課程相當廣泛,從電氣工程、數學,到遺傳學、心理學等涉及多個學科專業,後來他放棄物理改修數學。
1950年,也就是明斯基本科的最後一年,他和他的同學Dean Edmonds建造了世界上第一台神經元網路模擬器,並命名其為SNARC(Stochastic Neural Analog Reinforcement Calculator)。這台計算機是由3000個真空管和B-24轟炸機上一個多餘的自動指示裝置來模擬40個神經元組成的網絡的。後來,明斯基又到普林斯頓大學攻讀數學博士學位,並以「神經網絡和腦模型問題」為題完成博士論文,但是當時的評審委員會並不認為這可以看做是數學。

明斯基的這些成果雖然可以被稱作人工智慧的早期工作,但是鑑於當時的明斯基還是一個青澀的毛頭小子,所做的博士論文都不能得到相應的認可,所以影響力有限。
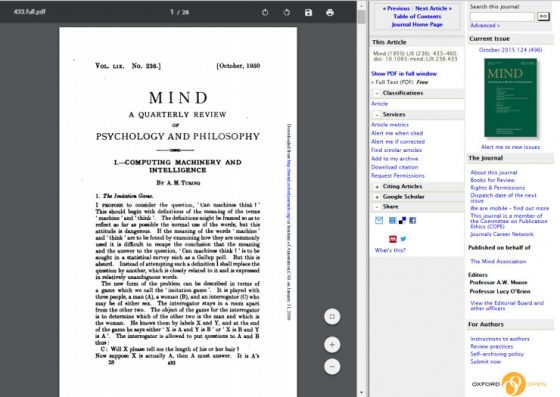
接著上場的第二位人物影響力就大很多,那就是電腦科學之父艾倫·圖靈(Alan Mathison Turing),他是被認為最早提出機器智慧設想的人。圖靈在1950年的時候(也就是明斯基還在讀本科的時候)在雜誌《思想》(Mind)發表了一篇名為「計算機器與智能」的文章,在文章中,圖靈並沒有提出什麼具體的研究方法,但是文章中提到的好多概念,諸如圖靈測試、機器學習、遺傳算法和強化學習等,至今都是人工智慧領域十分重要的分支。
介紹完以上兩大人物,接下來標誌著人工智慧作為一個獨立領域而誕生的盛會——達特茅斯研討會就要粉墨登場了。
不過在介紹達特茅斯研討會之前,我們不得不介紹這第三位重量級的人物,那就是約翰·麥卡錫,因為他正是這次研討會的發起人。約翰·麥卡錫於1948年獲得加州理工學院數學學士學位,1951年獲得普林斯頓大學數學博士學位。然後又在那裡作為老師工作了兩年,接著短暫地為斯坦福大學供職後到了達特茅斯大學,正是這個時期,它組織了達特茅斯研討會。
在這次大會上,麥卡錫的術語人工智慧第一次被正式使用,所以麥卡錫也被稱作人工智慧之父。其實麥卡錫在達特茅斯會議前後,他的主要研究方向正是電腦下棋。

下棋程序的關鍵之一是如何減少計算機需要考慮的棋步。麥卡錫經過艱苦探索,終於發明了著名的α-β搜索法,使搜索能有效進行。α-β搜索法說核心就是,算法在採取最佳招數的情況下允許忽略一些未來不會發生的事情。說的有點抽象,我們來舉個十分簡單的例子。
假如你面前有兩個口袋和一個你的敵人,每個口袋放著面值不等的錢幣,你來選擇口袋,你的敵人決定給你這個口袋裡哪張面值的錢。假設你一次只能找一隻口袋,在找口袋時一次只能從裡面摸出一次。當然你希望面值越大越好,你的敵人自然希望面值越小越好。假如你選擇了第一個口袋。現在我們從第一個口袋開始,看每一張面值,並對口袋作出評價。比方說口袋裡有一張5元的和一張10元的。如果你挑了這只口袋敵人自然會給你5元的,10元的就是無關緊要的了。
現在你開始翻第二個口袋,你每次看一張面值,都會跟你能得到的最好的那張面值(5元)去比較。所以此時你肯定就去找這個口袋裡面面值最小的,因為只要最少的要比5元好,那麼你就可以挑這個口袋。假如你在第二個口袋摸出一張1元的,那麼你就不用考慮這個口袋了,因為如果你挑了這個口袋,敵人肯定會給你1元面值的,那當然要選擇最小面值的5元的那個口袋啦。
雖然有點繞,不過我覺得你應該大概已經理解了這個思路。這就是α-β搜索法,因為這種算法在低於或者超過我們搜索中的α或者β值時就不再搜索,所以這種算法也稱為α-β剪枝算法。這種算法至今仍是解決人工智慧問題中一種常用的高效方法。
當年IBM的深藍國際象棋程序,因為打敗世界冠軍卡斯帕羅夫而聞名世界,它靠的正是在30個IBM RS/6000處理器的並行計算機上運行的α-β搜索法。
但是需要注意的是,前不久的Google AlphaGo,由於棋盤是19×19的,幾乎所有的交叉點都可以走子,初始的分支因子為361,這對於常規的α-β搜索來說太令人生畏了,所以別看名字裡面帶了一個α(Alpha,有可能這個名字是為了紀念麥卡錫的α-β搜索算法),AlphaGo採用的是卻是蒙特卡洛搜索樹(MCTS),它是一種隨機採樣的搜索樹算法,它解決了在有限時間內要遍歷十分寬的樹而犧牲深度的問題。

後來麥卡錫有從達特茅斯搬到了MIT,在那裡他又做出了三項十分重要的貢獻。第一個是他定義了高級語言Lisp語言,從此Lisp語言長期以來壟斷著人工智慧領域的應用,而且人們也有了可以拿來用的得力工具了,但是稀少而且昂貴的計算資源仍是問題。於是麥卡錫和他的同事又發明了分時技術。然後,麥卡錫發表了題為「有常識的程序」的文章,文中他描述了一種系統,取名為意見接收者,任務是使用知識來搜索問題的解,這個假想也被看成是第一個完整的人工智慧係統。
同年,明斯基也搬到了MIT,他們共同創建了世界上第一座人工智慧實驗室——MIT AI Lab實驗室。儘管後來麥卡錫和明斯基在某些觀點上產生了分歧導致他們的合作並沒有繼續,但這是後話。

二、人工智慧的誕生
好了,前期的一些大人物介紹完了,讓我們一起回到1956年那個意義非凡的夏天。
那年,28歲的約翰·麥卡錫,同齡的馬文·明斯基,37歲的羅切斯特和40歲的夏農一共四個人,提議在麥卡錫工作的達特茅斯學院開一個頭腦風暴式的研討會,他們稱之為「達特茅斯夏季人工智慧研究會議」。參加會議的除了以上這四位,還有6位年輕的科學家,其中包括40歲的赫伯特·西蒙和28歲的艾倫·紐維爾。
在這次研討會上,大家討論了當時計算機科學領域尚未解決的問題,包括人工智慧、自然語言處理和神經網絡等。人工智慧這個提法便是這次會議上提出的,上文也有提到。在這個具有歷史意義的會議上,明斯基的SNARC,麥卡錫的α-β搜索法,以及西蒙和紐維爾的「邏輯理論家」是會議的三個亮點。前面已經對明斯基的SNARC,麥卡錫的α-β搜索法有所介紹,下面我們再來看一下西蒙和紐維爾的「邏輯理論家」又是什麼。
西蒙和紐維爾均是來自卡內基梅隆大學(當時還叫卡內基技術學院)的研究者,他們的研究成果在這次盛會上十分引人注意。「邏輯理論家」是西蒙和紐維爾研究出來的一個推理程序,他們聲稱這個程序可以進行非數值的思考。然後在這次研討會之後不久,他們的程序就能證明羅素和懷特海德的《數學原理》第二章的大部分定理。但是歷史往往對新鮮事物總是反應遲緩,他們將一篇與邏輯理論家合著的論文提交到《符號邏輯雜誌》的時候,編輯們拒絕了他們。

我們現在來看看這個研討會的成果,或者說叫意義。遺憾的是,由於歷史的局限,這個世界上最聰明的頭腦一個月的火花碰撞,並沒有產生任何新的突破,他們對自然語言處理的理解,合在一起甚至不如今天一位世界上一流大學的博士畢業生。但是這次研討會卻讓人工智慧領域主要的人物基本上全部登場。在隨後的20年,人工智慧領域就被這些人以及他們在MIT、CMU、斯坦福和IBM的學生和同事們支配了。
我們看看這10個人,除了夏農,當時其實大多數都沒什麼名氣,但是不久之後便一個個開始嶄露頭角,其中包括四位圖靈獎的獲得者(麥卡錫,明斯基,西蒙和紐維爾),這四位也是我上文主要介紹的四個人。當然,夏農也不用得圖靈獎,作為信息論的發明人,他在科學史上的地位也圖靈也差不多了。

三、短暫的繁榮與困境
從這次會議之後,人工智慧迎來了它的一個春天,因為鑑於計算機一直被認為是只能進行數值計算的機器,所以,它稍微做一點看起來有智能的事情,人們都驚訝不已。
因為鑑於當時簡單的計算機與編程工具,研究者們主要著眼於一些比較特定的問題。例如 Herbert Gelernter 建造了一個幾何定理證明器,可以證明一些學生會感到棘手的幾何定理;阿瑟·薩繆爾編寫了西洋跳棋程序,水平能達到業餘高手;James Slagle 的SAINT程序能求解大學一年級的閉合式微積分問題;還有就是結合了多項技術的積木世界問題,它可以使用一隻每次能拿起一塊積木的機器手按照某種方式調整這些木塊。

雖然這些早期的人工智慧項目看起來擁有著巨大的熱情和期望,但是由於方法的局限性,人工智慧領域的研究者越來越意識到他們所遇到的瓶頸和困難,再加上沒有真正令人振奮人心的項目出來而導致資助的停止,人工智慧陷入了一個低潮。
產生這些現實困難的原因主要有三點。
第一點是大部分早期程序對要完成的任務的主題一無所知。
就拿機器翻譯來說,給程序一個句子,會用的方法只是進行句法分割然後對分割後的成分進行詞典翻譯,那這樣就很容易產生歧義。例如I went to the bank,bank既有銀行也有河岸的意思,如果只是單純的分割加單詞翻譯,這句話根本沒法解釋。
第二點是問題的難解性。
上面我已經提到,早期的人工智慧程序主要解決特定的問題,因為特定的問題對象少,複雜度低啊,但是一旦問題的維度上來了,程序立馬就捉襟見肘了。
第三點就是程序本身的結構就有問題。
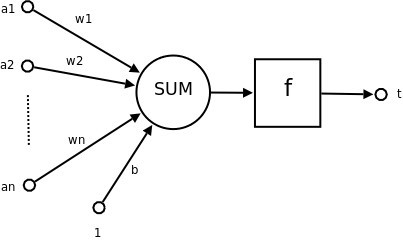
例如明斯基在1969年證明了兩輸入的感知機連何時輸入是相同的都判斷不了。
綜上,由於種種困難,再加上資助的減少,人工智慧步入了寒冬。這便是人工智慧歷史的上半段。
四、人工智慧的重生
上個世紀80年代中期,當初於1969年由Bryson和Ho建立的反傳學習算法被重新發明,然後統計學在人工智能領域的使用以及良好的效果也讓科學界為之一振。於是在新的結構和新的方法下,人工智慧又重獲新生。
首先興起的是語音識別領域,在這個方面的成就一個重要的原因是隱馬爾可夫模型的方法開始主導這個領域。隱馬爾可夫模型包含「隱含」和「馬爾可夫鏈」兩個概念,馬爾可夫鍊是具有這樣一種特性的鏈條,就是現在的狀態只和前一個狀態有關,而和再往前的狀態沒有關係。所以我們遇到這樣一個鏈條的時候,我們可以隨機選擇一個狀態作為初始狀態,然後按照上述規則隨機選擇後續狀態。
「隱含」的意思則是在這個馬爾可夫鏈上再加一個限制就是,任意時刻的狀態我們是不可知的,但是這個狀態會輸出一個結果,這個結果只和這個狀態相關,所以這個也稱為獨立輸出假設。
通過這麼一解釋我們就能看出,隱馬爾可夫模型是基於嚴格的數學理論基礎,這允許語音研究者以其他領域中發展數十年的數學成果為依據。其次這個模型的這種隨機性可以通過大量的真實語音進行訓練,這就保證了性能的強健性。
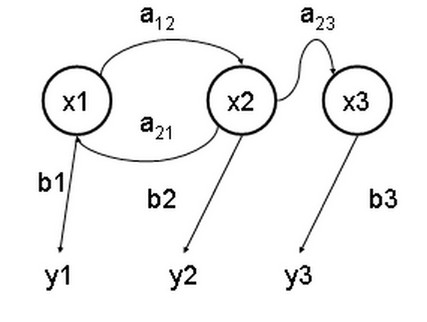
在馬爾可夫鏈的基礎上還誕生了一個以對不確定性知識進行有效表示和嚴格推理的形式化方法——貝葉斯網絡。貝葉斯網絡是一個加權的有向圖,是馬爾可夫鏈的拓展。馬爾可夫鏈保證了網絡中的每一個狀態只跟與其直接相連的狀態有關,而跟與它間接相連的狀態沒有關係,那麼這就是貝葉斯網絡。在這個網絡中,每個節點的概率,都可以用貝葉斯公式來計算,貝葉斯網絡因此得名。
貝葉斯網絡極大地克服了20世紀60年代和70年代概率推理系統的很多問題,它目前主導著不確定推理和專家系統中的人工智慧研究。而且這種方法允許根據經驗進行學習,並且結合了經典人工智慧和神經網絡最好的部分。所以極大的推動的人工智慧領域走向現在我們正處的這個巔峰時代。
除了 這種算法上的革新,還有兩個重要推動因素就是互聯網的興起以及極大數據集的可用性。就像我們用Siri的時候必須聯網一樣,人工智慧係統基於Web的應用變得越來越普遍;我之前在文章《2015年,機器人界發生了哪些神奇瘋狂的故事?(下)》中介紹的HitchBOT,它可以拍照、自動識別路人的語言,並將回答顯示在屏幕上,這個能力也是通過在網絡上搜索相應的答案而實現的。
由於我們現在採用的方法已經基本上變為是基於概率的方法,所以我們便需要有大量的數據集對我們的系統進行訓練,以完成監督學習。而現在的互聯網環境讓這種極大數據集的獲得變得越來越方便和容易。就如我們所熟知的ImageNet,ImageNet是一個帶有標記信息的圖片庫,裡面的圖片均已經由人對圖片內容進行了標記。它就好比是一個用於測試計算機視覺系統識別能力的「題庫」,包含超過百萬道「題目」。題目由圖像和對應的單詞(80%為名詞)組成,考察的方式是計算機視覺系統能否識別圖像中的物體並返回正確的單詞。ImageNet使用訓練題對計算機視覺系統進行「培訓」,然後用測試題測試其識別能力。

又如AlphaGo,在DeepMind的主頁裡,AlphaGo是這樣被介紹的:它是一種電腦玩圍棋的新方法,這種方法運用了基於深度神經網絡的蒙特卡洛搜索樹,而這個深度神經網絡一方面是通過運用人類專家級圍棋棋局進行監督學習來訓練,另一方面還通過程序通過電腦自己與自己博弈的增強學習來進行訓練,可見AlphaGo的成果也離不開通過學習人類專家級棋譜進行監督學習的這個大量數據集的使用。
今天這篇文章,我們從人工智慧的萌芽一直到今天AlphaGo打敗擊敗歐洲冠軍樊麾職業二段這個里程碑式的事件截止,介紹了人工智慧能走到今天這個成就的一路的艱難險阻與大風大浪。我相信,隨著計算機運算能力以及更加優化的算法,以及大數據集和數據挖掘等技術的幫助,人工智慧的路一定會繼續高歌猛進。







































