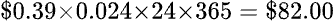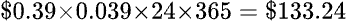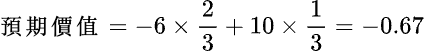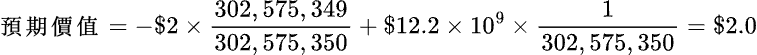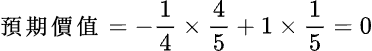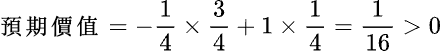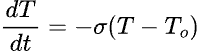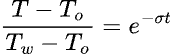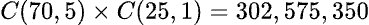第三個例子或許有從電視上看過,或者親自被問過,這個問題是這樣的:隨機在 1~50 想一個數字,然後「魔術師」可以猜中你心裡所想的數字。你可能會認為你所想的那一個數字是隨機而來的 By Chance,但其實不然。在幼齡時期腦中的認知中沒有數字的概念時,我們根本無法得出那一個數字;因此這一個看似隨機而來的數字,其實是經由腦中不斷的演算各種環境數值後,求得的最大可能性,這些環境數值大多是在沒有意識到的情況下被記錄下來,但由於環境的參數太多太亂,所以這些資訊很難被演算變成結果,但卻會變成演算的一部分,而這樣的過程視為 By Design。
好,如果上面三個都能理解了,現在我們換成大樂透來看,假設開球的設備就像撞球的球檯,他是一個有限的空間和範圍,讓 49 顆號碼球互相碰撞後,最後取出的 7 個號碼 (含特別號),中頭獎的機率為 1/10,068,347,520,看起來機率非常的小,但實際機率卻不然,我們可以把每次的碰撞視為 By Design 而不是 By Chance,哪顆球與哪顆球會碰撞到,完全可以從演算法中計算出來,當然開獎的結果也可以由演算法得出。
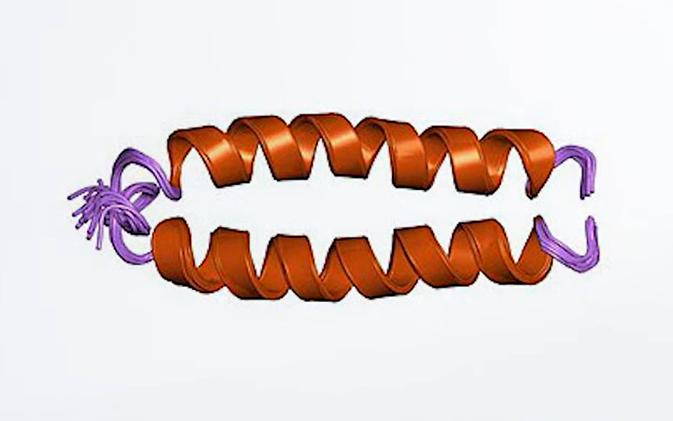
1990 年,融合蛋白 CD4 免疫黏附素(CD4 immunoadhesin)誕生。這項設計,是為了對付令人類聞風喪膽的 HIV 病毒。
-----廣告,請繼續往下閱讀-----
我們知道 T 細胞是人體中一種非常重要的白血球。在這些 T 細胞中,大約有六到七成表面帶有一個叫做「CD4」的輔助受體。CD4 會和另一個受體 TCR 一起合作,幫助 T 細胞辨識其他細胞表面的抗原片段,等於是 T 細胞用來辨認壞人的「探測器」。表面擁有 CD4 受體的淋巴球,就稱為 CD4 淋巴球。
麻煩的來了。 HIV 病毒反將一軍,竟然把 T 細胞的 CD4 探測器,當成了自己辨識獵物的「標記」。沒錯,對 HIV 病毒來說,免疫細胞就是它的獵物。HIV 的表面有一種叫做 gp120 的蛋白,會主動去抓住 T 細胞上的 CD4 受體。
而另一端的 Fc 區域則有兩個重要作用:一是延長融合蛋白在體內的存活時間;二是理論上能掛上「這裡有敵人!」的標籤,這種機制稱為抗體依賴性細胞毒殺(ADCC)或免疫吞噬作用(ADCP)。當免疫細胞的 Fc 受體與 Fc 區域結合,就能促使免疫細胞清除被黏住的病毒顆粒。
不過,這裡有個關鍵細節。
在實際設計中,CD4免疫黏附素的 Fc 片段通常會關閉「吸引免疫細胞」的這個技能。原因是:HIV 專門攻擊的就是免疫細胞本身,許多病毒甚至已經藏在 CD4 細胞裡。若 Fc 區域過於活躍,反而可能引發強烈的發炎反應,甚至讓免疫系統錯把帶有病毒碎片的健康細胞也一併攻擊,這樣副作用太大。因此,CD4 免疫黏附素的 Fc 區域會加入特定突變,讓它只保留延長藥物壽命的功能,而不會與淋巴球的 Fc 受體結合,以避免誘發免疫反應。
從 DNA 藍圖到生物積木:融合蛋白的設計巧思
融合蛋白雖然潛力強大,但要製造出來可一點都不簡單。它並不是用膠水把兩段蛋白質黏在一起就好。「融合」這件事,得從最根本的設計圖,也就是 DNA 序列就開始規劃。
我們體內的大部分蛋白質,都是細胞照著 DNA 上的指令一步步合成的。所以,如果科學家想把蛋白 A 和蛋白 B 接在一起,就得先把這兩段基因找出來,然後再「拼」成一段新的 DNA。
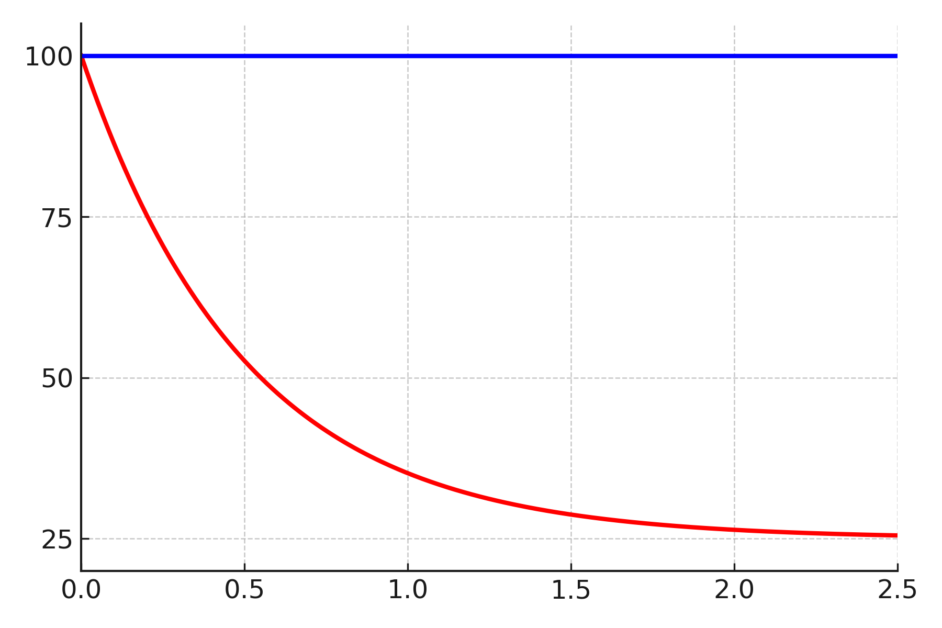
圖一: x 軸為特徵時間(相對值),y 軸為溫度。紅線為熱水瓶依據牛頓冷卻定律所畫出的降溫曲線,藍線代表熱水瓶維持保溫狀態。
但在實應上,我們可以說到達 1.5 之 x 座標時已經是室溫。而 1.5 到底是多少小時,則因電熱水瓶的設計及室溫之不同而異。如果設定的節能定時 x ≤ 1.5,那麼熱水瓶所散的熱正好由重新啟動的加熱補上,所以根本沒有節能;如果設定的 x > 1.5,則因熱水瓶在 x ≥ 1.5 後就已經不再散熱了,而沒有關掉的熱水瓶仍必須繼續保溫(圖一藍線),所以關掉熱水瓶是值得的、有節能的效果。
聖荷西夏天很熱的時間不長,因此筆者一直想買容易移動的「便攜式空調」(portable air conditioner),以便炎暑一過就可以收起來。以「portable air conditioner」搜尋亞馬遜網路市場,發現有價格差異很大的兩種空調:一種大約在美金 100 元以下,另一種則大約在 200 元以上。
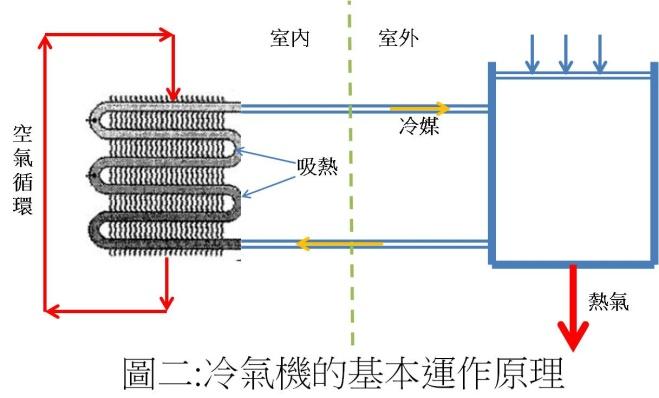
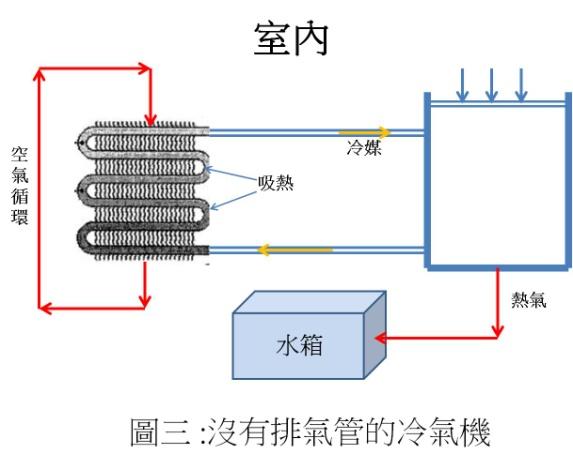
DIKE 多功能移動式瞬涼水冷氣 HLE700WT就是基於這種想法的一個產品。其廣告謂:創新「無排熱管」冰風機,採用水冷循環及高效壓縮機製冷,出風降溫至 14℃,搭配獨立除溼、送風三合一功能四季都適用!前面涼快,後面涼快,無須排熱風管免窗戶施工。…製冷前需先將水箱加水,維持水循環運作,水箱裝滿 4 公升時可持續製冷 8 到 12小 時,一整天都涼爽。因為水是熱交換媒,因此廣告特別強調「大容量水箱」,讓我們在這裡也利用能量不滅定律來看看是否可行。
廣告中沒有提到冷氣量,讓我們在這裡假設與前面那款冷氣機一樣(1400瓦特)吧,即每秒鐘可以從室內拿掉1400焦耳的能量,或每小時可以拿掉5040千焦耳的能量。前面提到水的比熱很高,將1公克的水提升溫度一度需4.2焦耳;因此4公升(4000克)的水從30°C提升到100°C 水滾前可以拿掉1176千焦耳(4.2 x 4000 x 70)的熱,也就是說僅能夠拿掉冷氣機0.23小時的壓縮熱能(1176/5040)!