

如何在癌症發生初期掌握病情、及早介入治療,一直是醫界和科學界努力的目標,只是在各種癌症發生原因還不完全明朗的情況下,想達到這個目標簡直難上加難!
中研院物理研究所研究員周家復帶領研究團隊,在 2013 年研發「奈米分子壩」技術,能利用簡單的晶片快篩,有效快速縮短癌症篩檢的時間、提高篩檢精準度。三年後,這個技術研發更成熟了,周家復說,「我們已經能將技術實際應用在攝護腺癌標誌分子、神經胜肽分子、皮質醇的檢測,如果通過臨床標本試驗,預計最快五到十年可以開始廣泛應用」。
絕緣體外加電場 分離正負電荷分子
奈米分子壩其實是一個相當複雜的技術,要解釋得先從晶片本身的材料「絕緣體」說起。由於絕緣體若外加電場,本身電子因為被原子核束縛得很緊,沒辦法大幅移動,只能在原子附近小幅位移,最後原子本身的正負電荷分離、形成電偶極矩,這個現象被稱為「介電質的極化」,這些電偶極矩也會產生電場,在外加電場越大的情況下,正負電荷分離會越明顯。

分子濃度不高 也能快速聚集!
中研院研究團隊利用絕緣體的這個特性,將矽晶或石英玻璃當作材料,製作奈米流通道,其中關鍵的隘口設計只有數十奈米大小。
這有什麼優點?絕緣體有了外加電場、會產生正負電荷分離的特性,讓研究員可以透過外加電場、分離帶有正負電荷的分子;此外,調配液體濃度或種類,也能藉此操控游動其中的帶電微粒,讓不同帶電粒子依照某些特性在游動過程中分離開來。
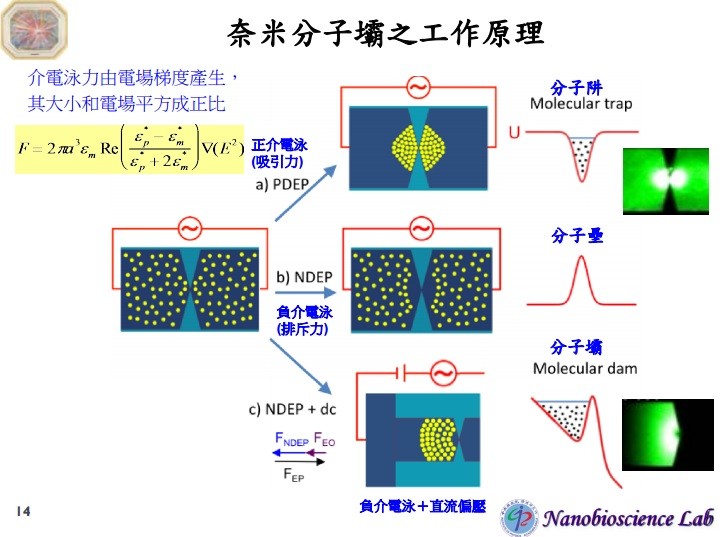
周家復設計的這個快篩晶片系統,主要透過高度聚焦電場,讓奈米流道在交直流電場下、利用分子介電反應產生的負介電泳排斥力,形成分子壩效應,這個效應會讓要檢測的蛋白質分子,快速大量聚集在隘口處。由於過去分子診斷在濃度低的檢測液體中,較難找到目標偵測物、需要耗費的時間也很長,分子壩技術的突破在於,能有效提高偵測物分子的區域濃度,相較傳統方式半小時才能蒐集足夠濃度的偵測物,晶片快篩系統靈敏許多,以攝護腺癌標誌分子 PSA 為例,晶片系統三十秒就能測出 1 pg/mL(每毫升一皮克),濃度是現在的千分之一。區域濃度提高的結果,能讓原先分子診斷技術中,難以偵測的生物標誌物(通常是生物分子,如 DNA 、蛋白質等)檢測成為可能。
醫生制定濃度標準 準確掌握罹癌時機
高濃度聚集要偵測的分子還不夠,接下來必須有生物辨識分子來分辨這些待測物、加上傳導器傳遞偵測完成的結果,整個流程才算成功。依據美國聯邦食品藥物管理局核定的臨床應用癌症標誌分子來看,只要有生物標誌物的癌症,都可以用這個技術檢測,只不過周家復強調,並非偵測到這些分子就表示罹患癌症,檢測到的物質達到什麼程度才算患病,需要由醫師進一步制定,「我們主要希望做出靈敏的快篩技術,讓第一線醫護人員能即時掌握病情、介入治療」。

生物標誌物主要透過找出某些病症與生物標記變化的相關性,藉此協助醫生診斷疾病、進行個體治療。雖然這是個具有相當研究歷史的領域,但在臨床上的應用其實還有許多努力空間。事實上,周家復研發的這項技術,不只能針對癌症偵測生物標記分子,也可以偵測神經胜肽分子,由於神經胜肽分子 NPY、OXA,有潛力作為飛行員身心狀態的檢測指標,未來這個晶片快篩技術,若能發展相關標準搭配檢測,在臨床應用上勢必能成為一大利器。





































