

2015-16年入冬以來第一波寒流即將在1月23日來襲,早在一週之前,許多人就開始流傳手機app上接近0度誇張的低溫預報。更有甚者,日本氣象協會在18日預測台北市在25日有下雪機會,引起軒然大波;網路上甚至一度傳出號稱台北101下雪的影片,後經網友指出應為下雨影片放慢所造成的錯覺。
其實中央氣象局在17日的預報並沒有反映出寒流(定義台北市預測氣溫低於10度方為寒流),直到18日才將預測氣溫逐步下修。19日,日本氣象協會預測台北24日低溫為1度,而中央氣象局早上初步預測低溫8度,後改為6度。
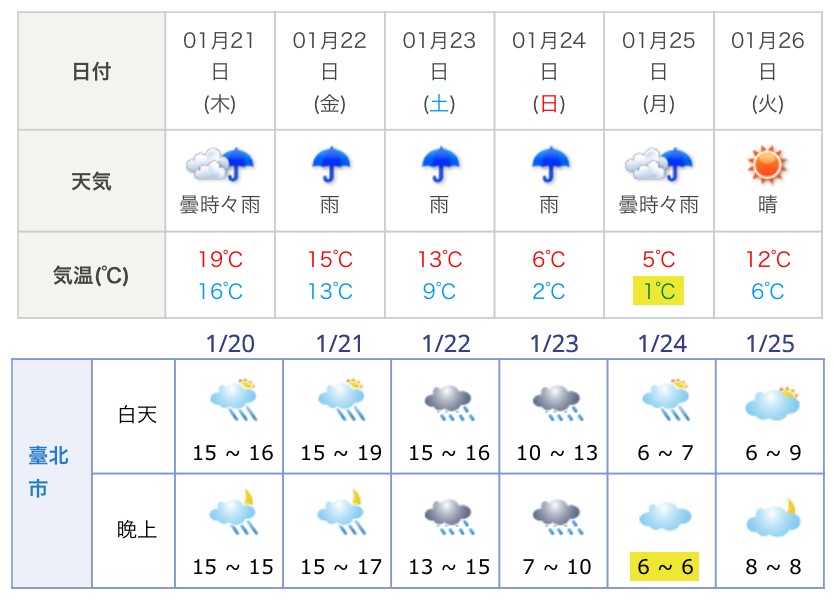
是什麼原因造成不同氣象預報來源的預報差異?我們又應該相信誰呢?尤其寒流又是台灣四大氣象災害之一(另三大為颱風、梅雨與乾旱),往往造成生命財產損失,預報不一致讓大家何去何從?
PanSci泛科學2012年《祛除氣象預報的迷思》一文中已探討過,大氣現象瞬息萬變,並非現代科技可以全盤掌握。儘管中央氣象局2012年向日本添購超級電腦,可望將預報精確度提高百倍,但超級電腦並非萬能。因此在了解、分析與討論氣象預報前,必須了解「預報必定存在誤差」的事實。

氣象預報的基礎—數值天氣模式
前文以颱風的定量降雨預報切入,而定量降雨預測技術尚未成熟,大幅誤差在所難免;但最近的話題則是寒流的低溫預測,溫度是氣象觀測與預報最基本的項目之一,為何依然存在可觀的預測誤差呢?現代氣象預報的主要依據是電腦模擬的「數值天氣模式」。數值天氣模式將大氣分割成許多網格,好比電腦以點陣圖的方式把圖片化為一整個表格的數字,才能進行儲存與處理。氣象機構蒐集觀測資料(氣溫、濕度、氣壓、風速、風向等)之後,計算出每一個網格中的各種大氣數據,接著將這些數據輸入超級電腦,根據模式設定的複雜大氣方程式進行大量運算,取得未來可能的天氣情況。
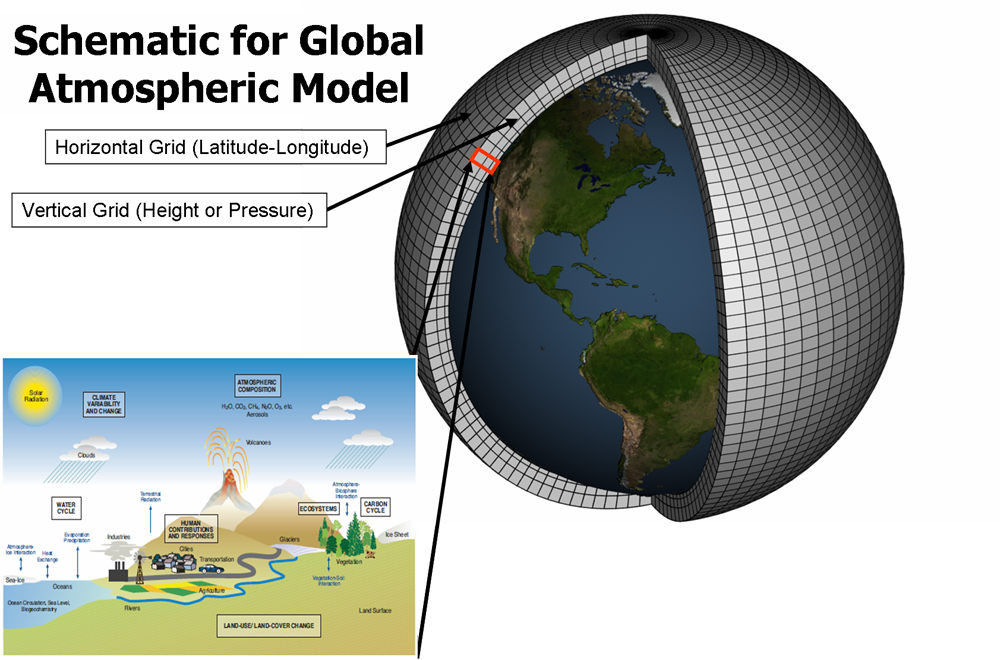
網格解析度
由於數值天氣計算極為複雜,實務上氣象機構會依照需求,對地球上的不同區域採用不同的分割解析度:數值天氣模式可粗略分為全球模式與區域模式,首先由「全球模式」模擬整個地球表面的大氣,再逐步使用網格解析度更高的「區域模式」,分析預測部分區域的天氣。
以中央氣象局為例,由於服務的主要對象是台灣地區,因此數值天氣模式在台灣與周邊區域的解析度較高(網格較細密),方便進行更精密的計算與預測。中央氣象局採用的全球模式網格大小為55公里見方,越靠近台灣網格尺寸越小,台澎金馬地區的區域模式網格最為細密,為5公里見方。如此逐步計算,確保在台灣地區取得最精確的計算結果。
此時氣象機構預測差異的一大來源已經顯而易見:不同地區的氣象機構,由於主要服務客群不同,也會在數值天氣模式中,對不同區域採用解析度較高的區域模式,以便達成節省運算量與精確預測本地天氣的平衡。因此歐美日等地氣象網站對台灣的天氣預測,在數值天氣模式多半直接採用低解析度的全球模式,未經區域模式的精密計算優化,因此預測的氣溫自然會與中央氣象局有所差異了。
觀測為預報之母
前面提到數值天氣模式需要觀測資料作為初始條件輸入電腦,才能進行運算以預測未來的氣候變化。觀測資料又分為實測資料與非實測資料,前者以地面測站以儀器(溫度計、風向風速計、雨量計等)直接測量到的數據為主(也包含進入颱風中實測的飛機與投落送),後者則是以氣象雷達和氣象衛星掃描大氣所得。氣象雷達與衛星取得的數據,多半為全球公開或多國合作分享,因此各國氣象機構在這方面取得的觀測資料是相當接近的。
然而,非實測資料存在諸多限制,一來雷達與衛星資料須經複雜的計算解讀後才可使用,使用的方程式多少都對大氣條件做了一定的簡化,因此難免與實際天氣有所出入。二來雷達掃描容易受到地形與人造障礙物阻礙。相比之下,實測資料就是不同氣象機構佔有本地優勢之處。全台目前包括人工氣象站、自動氣象站與自動雨量站在內,共有超過400個氣象測站,蒐集的觀測資料除了更能反映各地的天氣差異、充實數值天氣模式的數據之外,也有助於短期預報與預警(如豪雨特報、土石流警戒等)。除主要測站外,這些氣象測站的完整觀測資料,須向中央氣象局申請才可取得,外國氣象機構特地採用的意義也不大,連帶影響預報的精確度。
人工修正
俗話說盡信書不如無書,更有醫師進一步延伸說道:「盡信實驗數據不如無現代科學儀器」。因此電腦依照數值天氣模式計算出的數據,在發布於氣象機構網站、app與各種平台之前,多半經過預報員依個人專業經驗加以人工修正。中央氣象局對寒流或強烈冷氣團的初期預報多半較為保守、與數值模式有所出入,預報主任鄭明典也於18日指出,過去幾次電腦模式預測寒流,但經預報人員判斷,並沒有降低預測氣溫至寒流水準,事後證明預報員判斷正確。23日開始的這波寒流,客觀資料支持度較高,因此才決定調整預報來反映。鄭明典並在19日進一步表示:
預報員要為提供的資訊負責,所以有幾分把握說幾分話。
而許多手機app的天氣資料來源,不外乎幾家國外知名的氣象公司,例如The Weather Channel、Weather Underground、AccuWeather等等。這些app多半可查詢全球天氣,而這些氣象機構主要服務的客源多來自美國地區,對於全球的預報資料,不太可能全部經過預報員人工校正。因此偶有因數值天氣模式穩定性較差,而造成預報一直改來改去、波動很大,或者預報後期出現誇張數值的情形。
綜合以上幾點,預測台灣地區的天氣,建議大家仍以中央氣象局的預報為主,畢竟在數值天氣模式的網格解析度、地面測站觀測資料與人工修正三個方面,都比外國氣象機構 / 網站的預報更有優勢。
但其他來源的氣象預報也不是全無參考價值,只是在使用前必須了解其限制,以及針對主要服務範圍的優化。不要隨意盡信或拘泥於數字上的差異,面對媒體的誇大報導更須謹慎。尤其現在各大預報齊指寒流,呼籲大家盡早做好防寒準備;不論最後實際溫度如何,別忘了凡是預報必有誤差的基本觀念!
《台北會下雪嗎?》下集將討論台灣氣象史,平地真的下過雪嗎?敬請期待~
參考文獻:
- 李名揚 (2009) 氣象預報為什麼會不準? 科學人2009年第92期10月號
- 張麒偉 (2007) 氣象預報與防災應用。《科學發展》2007年2月,410期
- 于國平,盡信實驗數據不如無現代科學先進儀器。
- tytony,[討論] 關於國外氣象網站或手機APP的預報,批踢踢實業坊
- 鄭明典Facebook
- The Weather Channel
- Weather Underground
- AccuWeather
- 中央氣象局
- 日本氣象協會



































.jpg){kind=link}