

在近期所舉辦一系列的「全國能源會議」中,筆者注意到了一段堪稱歷來類似會議中最詭異的紛爭對話XD,有與會者針對核災發生的機率,提出了「百萬爐年才會發生一次」,以及「台灣的核災機率高達24%」的極端相悖論點。筆者認為,若能釐清這些數值的計算方式或來源,探討其機率計算的意義與應用,將有助在這相當容易擦槍走火的核能議題中,有更精確與紮實的討論。
他們說… 核災的機率是…..
- 「台灣核電廠發生爐心熔毀核災機率高達24%」 – 台大資訊系高成炎教授(註1)
- 「根據國外統計,核災發生機率是500分之一,比中一張統一發票200元獎金的千分之一機率還高出1倍」 – 台灣環境保護聯盟會長、交大土木系劉俊秀教授(註2)
- 「100座核能電廠發生事故造成死亡的機率和慧星撞擊地表造成傷亡的機率一樣低。」 – 中華民國核能學會(註3)
- 「Core damage frequencies of 5*10-5/a are a common result, a figure often adopted in further risk studies.」 – 歐盟環境總署(註4)
- 第一系列第二代沸水反應爐BWR/4(註:核一廠所使用),爐心損壞機率為10-4~10-7 – 美國能源部(註5)
筆者試圖搜尋了一下關於核電廠發生災害的機率,得到了從24% ~ 10-7這整整跨越6個級距的龐大差異。但若細究每一項機率的成因,卻可以發現這幾個數字的含意卻不盡相同,值得進一步探討與釐清。
若回顧一下目前對於核電廠的安全評估、「核電事故比飛機失事還低」這樣的敘述,以及能源會議上會議主席劉俊秀教授所提到的一份「1975年MIT教授的過時研究」。筆者發現這些敘述可指向至一份美國核能管制委員會(Nuclear Regulatory Commission, USNRC)在1975年所發布一份代號為WASH-1400之『反應器安全研究報告(Reactor Safety Study)(註6)』,這份報告點出了核電廠可能會因部分安全系統或零組件的同時失效,導致嚴重的安全系統失能而造成比設計基準更嚴重的爐心熔毀。同時也估計了一座反應爐運轉一年會發生爐心熔毀的機率是兩萬分之一。從風險來看,造成人命損失的機率則是五十億分之一(2*10-10),遠低於飛機失事與被雷打到的機率。有趣的是,當時核工業界認為此報告對於安全系統失能的預測過於悲觀誇大,而反核界則認為微乎其微的機率計算結果根本是粉飾太平。
災難的定義,機率的意義
要計算核電廠意外機率其實有很多種方式,例如「全日本在311福島核災之前有54座核電機組。三座熔爐,一座燃料池輻射外洩,故其機率各為 3/54 及 1/54(註7)」或是「爐心融毀事故平均發生機率約為5,000爐年(所有事故)至8,000爐年(排除車諾比事故)(註8)」。在探討這兩則例子之前,我們需要先了解與核電廠有關的事件可以大至如車諾比般爐心熔毀放射性物質大量外洩,也可以小至員工感冒摔車打掃不乾淨這種枝微季節的小事… 而根據「國際核和放射事件分級表(註9)」,一個簡單區別「事故(accident)」與「事件(incident)」的方法是看反應爐的爐心是否有損壞熔毀。歐盟環境總署(Directorate-General for Environment, DG-ENV)在針對核電事故的安全評估中,亦採用爐心熔毀頻率(core damage frequency, CDF)做為評估指標(註10)。這也是我們看到在上述幾則例子與研究回顧中,人們對於機率的討論多聚焦於爐心熔毀事故的原因。
另一則我們需要了解的是以「爐年」作為分母的計算方式。這並不難理解,因為每一反應爐的運轉時間不一,每一座發電廠所擁有的反應爐數量也不一定相同。因此以每一座反應爐的運轉年數作為分母,會比起「出事的反應爐÷所有反應爐」更為精確。
爐心熔毀頻率(CDF)是什麼?
無論是歐盟環境總署或是美國能源部,對於核電廠的CDF評估都是10-4~10-7這樣相當微小的數值,而CDF這個用來評估核電廠安全的重要指標,正是起源於之前提到的那份1975年發表的WASH-1400報告。評估計算CDF的原則,是利用事件樹(event tree)的方式,分析爐心損毀的可能因素與牽扯組件,並定量出每一種因素、零組件失效的發生機率,將各種組合下的機率相乘,即可以得到爐心熔毀的機率。WASH-1400報告簡單地分類出,達到爐心熔毀的事件會有:A管路破裂、B外部電力喪失、C緊急爐心冷卻系統失效、D分裂產物無法移除、E圍阻體完整受損這五大類可能。然而,今日在實際計算的複雜程度,已遠超過WASH-1400的內容,例如我國各核電廠的CDF評估中,還會再區分廠內事件、地震颱風火災水災等不同情境而導致爐心熔毀的機率。
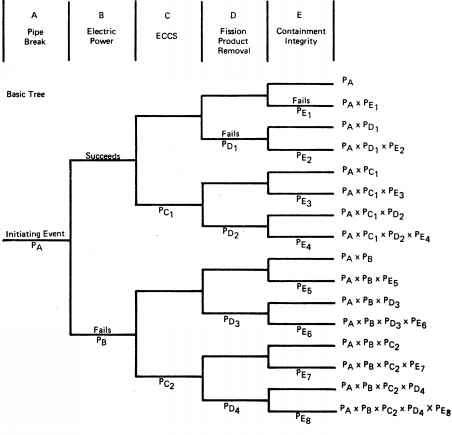
目前國際核管組織等,均以CDF作為核電廠「安全度評估(Probabilistic risk assessment, PRA)的重要管制指標。例如USNRC規定,所有核電廠不分機型,CDF都必須低於10-4次/爐年,若高於此數值則必須停機(註11、12)。而除了不同事故場景的估算,CDF也針對電廠運轉員遇到事件時的動作與判斷,來做人為疏失的機率估算。(註13、14、15)
註:除了CDF,USNRC亦同時採用「早期輻射大量外釋頻率(large early release frequency, LERF)」作為核電廠風險評估的監管指標。(註16)
然而,這樣的超低機率似乎和印象中幾次核電廠事故有點出入。也常常聽到有人會說人類核電發展不到百年就有了三次核災,哪來的百萬爐年才一次的可能。但是,我們若整理一下這三次核災的緣由:1979年美國三哩島核洩漏事件時,核工界尚未建立多重系統失效的觀念,CDF與PRA的評估也尚未制度化。而1986前蘇聯車諾比核事故則是因為車諾比核電廠的設計與西方民用核電廠差異過大,缺乏相當大程度的安全防範措施,也根本沒有採用近代建立的的核電廠安全評估方式。而2011年福島第一核電廠事故,理想中近代核安制度應該要能足夠發揮功效,然而事後調查報告指出,除了設計上未針對海嘯加以防範,又因體制與工安文化的不佳而造成人為疏失外(註17),福島第一核電廠根本沒有做PRA,也自然沒有CDF數值可做比較……也因此,似乎可以很護航地說,這三次核災都不在CDF管制的守備範圍內,所以若試圖用這三次重大核電事故來反省這個超低機率與CDF管制標準是否合理的話,這樣的反省/反擊效果恐怕也不夠直接有力。
那,台灣有在做CDF嗎?
CDF如此被國外核工界、管制法規所重視,那在台灣呢?事實上,台灣各電廠也有評估CDF,核一到核四分別為1.9*10-5、2.6*10-5、1.8*10-5次/爐年(註18),而核四的CDF是7.93*10-6次/爐年(註19)。這些數值目前是由台電公司委託反應爐原廠(西屋、奇異)計算提供,並同時請清大核工所李敏教授與他的「安全度評估工作室」負責計算比對,在政府的監督管制部分,行政院原子能委員會轄下的核能研究所也同時有計算評估的驗證機制。而除了CDF,國內電廠的PRA也有利用其他模型來評估事故機率,例如利用THERP(technique for human error rate prediction)及 HCR(human cognitive reliability)這兩種模型來量化人為失誤。(註20)
筆者也試圖整理一些過去坊間沒有太多著墨的法規與管制:CDF是核電廠「安全度評估(PRA)」的一部分,而PRA根據「核子反應器設施運轉執照申請審核辦法(註21)」,被列為「終期安全分析報告(Final Safety Analysis Report, FSAR)」的應載明事項之一。如果核電廠在興建中或運轉中有任何更動導致風險提高時,則依「核子反應器設施管制法(註22)」及其施行細則(註23),需由原能會審核同意才能繼續運轉。也因此,如果這個管制法規有被妥善遵守運行,我們似乎可以期望我國的電廠不會重演歷史上的核電廠事故。
然而,除了官方(政府與台電)公布的數值外,CDF的詳細計算方式以及更全面的PRA、FSAR報告等,似乎在網路上是無法自由下載的。筆者詢問了官方相關人士得知,這些計算方法和資料與核電廠設計圖有關,各零組件與系統的失效機率目前也是跟美國電力研究院(Electric Power Research Institute,EPRI)購買,有商業機密與版權等問題,即使是相關科系學生的論文研究也無法開放引用。對於一個有心監督官方的認真民眾來說,既要克服資料解讀的學術門檻,又受限於資料蒐集時商業機密的限制,該如何判斷或監督法規是否有妥善運行,就實在是個大哉問了……
(謎之音:雖然這樣問很失禮,但目前「XXXXXX監督委員會」大部分的成員真的有能力判讀這些資料嗎?)

高達24%的爐心熔毀核災機率?
(建議此段落可以先讀過高成炎教授的原文)
在了解CDF的意義之後,我們再來驗證高成炎教授為什麼會算出差異如此之大又有點嚇人的24%爐心熔毀核災機率。
筆者將高成炎教授一文中的機率算法拆分為兩部分來討論。其一是文中所述學理依據公式:「累積出事率 = 1 – (1 – 年出事率) ^ 累積年數」;其二為公式中,「年出事率」的選用。
(1) 公式:累積出事率 = 1 – (1 – 年出事率)^累積年數
回顧一下高教授的原文:(節錄)
「若以180爐年計算,則台灣發生爐心熔毀的機率為 (1 – ( 1 – 25/10,000)^ 180) = 36.27 %… 若以核電廠運轉 40年(260爐年)來算,則分別為 47.83 % … 若從2013年算起,則尚有112爐年,為 24.44 %…」
「以福島核災的經驗來評估,台灣從今天算起發生爐心熔毀的機率是 24.4 %。」
首先我們先試圖理解此公式的意義,如果要利用此公式,這必須建立在一個重要的假設之上,也就是每年的「年出事率」相同,其意義為出事的機率為獨立事件,每一年出事與否並不會影響來年的出事率。
針對上述假設,我們剛好可以利用法規規定,CDF未達10-4次/爐年須停機的條件來滿足。這是利用每年爐心熔毀機率作為年出事率,且利用法規下限作為年出事率的最大值,而後續計算也刻意保守地以最大值為計算依據。
那麼,在這條公式中可以發現當「累積年數」越多,則「累積出事率」也越高,這似乎有點像是電廠越老舊,出事率越高的感覺。似乎符合直觀的認知。但是,如果從公式本身機率的意義來看,此處「累積出事率」的意義,應解讀為:累積年間,每一年出事機率的總和。然而高教授文中的用法,卻是把這個多年累積機率,當成「這段期間的任一時間點」會發生的機率,這樣會發生一些詭異的結果了……
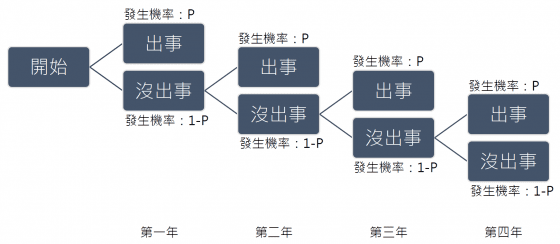
為了解釋這條公式的意義,我們先利用簡單的樹狀圖來幫助理解看看。若每年發生事故的機率是P,則沒出事的機率是(1-P)。這意思是四年都要沒出事的機率是(1-P)4,這四年會出事的機率就會是 1-(1-P)4,也就是高教授公式的意義。然而,把1-(1-P)4當作是這四年內任意時間點會發生的機率,就會有問題了。如果第一年沒出事的話,接下來要安全度過三年的機率,則增加為(1-P)3,(小提醒:因為機率P會小於1,所以(1-P)的次方數越多,反而總值會越小)。這會導致經過的時間越久,出事率反而越來越低。用高教授的算法來看,累積年數的意義是從現在起算至核電廠停役的爐年總和。而每經過一年,爐年總和就會越來越少,而「累積出事率」也會越來越低。如果把這結果一樣作為出事率的估計的話,這就會解讀成核電廠用越久,出事率反而越低。聽起來……不太合理吧。
再換一個方法來看,高教授所用的「累積年數」均是建立在各核電廠使用年限30年不延役的狀況下。以此推出未來還有112爐年的年數會累積。倘若國會突然修改法規,增加或減少了某座核電廠的使用年限。根據公式,「累積年數」的增減當然會改變而影響整段期間的累積出事率。但是,這會影響到當下的核電廠事故機率嗎?如果這樣會影響到當下的事故機率,這不就代表著核電廠的事故機率,居然會受到議員諸公們在國會殿堂演出的影響啊!!?
總結起這條公式的意義與實際應用的結果,如果要利用此公式所計算出的累積出事率來當作今日核電廠事故機率的評估,這恐怕是對機率的應用不夠正確也難以有實際效用。
修改註記(2014/12/22 20:50):筆者在前文中,認為高教授原文將「累積出事率」當成「累積年間,任一時間點會出事的機率」,是因對該文標題「台灣核電廠發生爐心熔毀核災機率高達24%」以及文中「以福島核災的經驗來評估,台灣從今天算起發生爐心熔毀的機率是 24.4 %。」的解讀。經網友留言提醒,筆者認為這樣解讀可能不夠正確而曲解高教授原意,請讀者見諒。
(2) 出事率?爐心熔毀率?
另一個造成如此高估算值的重要因素是「年出事率」的選用,根據高成炎教授文中所述:「以福島核災的經驗來評估,台灣從今天算起發生爐心熔毀的機率是 24.4 %」,而這句話所說的福島核災經驗,是主張台灣因與日本地理環境相似,因此核災機率應該參考日本,也就是以日本福島核災的三座機組爐心熔毀,除以平均使用25年的54座機組,而得到約 25/10000的核災機率,遠高過前段所述CDF的比例。
而關於這樣的出事率使用是否合理,筆者認為高教授的計算方式尚有一些可被挑戰之處,姑且學朱家安整理供各位參考:
- 從營運品質觀點,可以主張台電的核電非計劃性能力損失因數(註24)、公司整體信用評等(註25、26)遠高過日本東電(註27),故引用日本數據不洽當。
- 從地球科學為出發點,可以主張台灣的地震與海嘯狀況較日本更為輕微(註28)。
- 從核電廠工程觀點,可以主張東日本大地震後,針對福島核災情境提出新因應措施(如:斷然處置、遇震急停、海嘯牆等等),能避免福島事故重演(註29),如同航太工程一般,事故發生後的新措施與技術,反而會降低未來事故發生機率。
- 從法規觀點,可以主張我國核電廠的CDF值須低於USNRC法規標準10-4次/爐年才能運轉,而負責營運福島一號核電廠的日本東電,並沒有遵守與評鑑這項指標。
- 如果是以台日地理環境相似為原則,那麼在福島核災之前,日本爐心熔毀機率為零。但如果我們過去用這個零機率來做風險評估的話,這恐怕會導致過度鬆懈的心態而忽略了許多安全措施……
- 詭辯:如果主張台灣跟日本很相似,所以我們可以用日本的統計結果。那台灣跟台灣更相似(廢話…),所以我們也能用過去台灣的統計結果。而台灣過去因為沒發生過爐心熔毀,所以核災發生機率是零,那麼就會永遠為零了…… =w=
- 關於科學的證據力:除了可以很專家迷思地認為高成炎教授的公式和出事率引用方式,並未被主流學界與國際組織所使用。但也需要考慮到許多偉大理論的出現也是顛覆了主流觀點。但由於高教授的計算方式並未經歷同儕審查,也未以學術文章形式發表,若採用牛津大學實證醫學中心的分類方式,僅能歸類為證據力最低的「專家意見」。(註30、31)
綜上所述,對於24%的機率計算結果,並無法做為對核電安全評估的判斷,對出事率的選擇也仍有過多爭議待決。
除了機率,你更應該要關注的是……風險
對於任何災害來說,機率可高可低,發生災害時的危害也是可大可小。因此評估或比較災害或是要做出較好的選擇時,更應該去計算與比較各個選項所造成的風險。而對於風險常見的理解方式,是將危害發生的機率,乘上危害的損失,則可得到風險的期望值。也因此,對於核災的評估,發電方式的選擇,甚至是食品衛生、醫藥安全等,以量化的風險期望值作為衡量是很相當常見且清晰明瞭的方式。以本文不斷提到的爐心熔毀來談風險的話,我們儘管可以計算出了爐心熔毀的可能,但並不代表爐心熔毀就會造成嚴重的後果。例如日本福島核災與美國三哩島核洩漏事件都發生了爐心熔毀,但兩次事故所造成的實際危害卻相差非常大,這也意味著除了透過工程技術降低事故機率外,也同時需要針對發生事故時的補救或防範設備做努力。(當然,你也可以支持非核家園,核災機率就歸零了,不過也同樣需要比較與接受其他替代能源所造成的風險。以及某網路上激進永[ㄩㄥˇ]和[ㄏㄜˊ]業者找上門來的壓力XDDDD)
更多與風險應用有關的文章,您可以參考以下連結:
- 張清浩, 核能發電已經拯救上百萬人的生命, Pansci, 2013
- 莊秉潔, 核能發電已經拯救上百萬人的生命?, 2013
- 世界衛生組織(WHO)針對日本福島核災所造成的健康風險評估報告:World Health Organization. Health risk assessment from the nuclear accident after the 2011 Great East Japan earthquake and tsunami, based on a preliminary dose estimation. World Health Organization, 2013.
- 台大社科院風險社會與政策研究中心主任周桂田教授談自然科學在氣候變遷風險評估的限制與努力方向:氣候變遷下的災難須知(三):災難風險評估不能只靠科學, Pansci, 2013
參考文獻:
(註:本文有部分文獻引用自我國政府、商業公司與倡議團體或個人評論等非學術期刊資料,建議讀者們就其內容斟酌評估其證據力)
- 高成炎, 台灣核電廠發生爐心熔毀核災機率高達24%, 台灣環境保護聯盟. 2013
- 洪敏隆, 核輻大逃殺路跑活動 下月29日登場, 蘋果日報, 2014
- 核能電廠的風險與安全性, 中華民國核能學會
- Leurs, B. A., et al. Environmentally Harmful Support Measures in EU Members States. CE, Solutions for environment, economy and technology, 2003.
- Dingman, Susan, et al. Core damage frequency prespectives for BWR 3/4 and Westinghouse 4-loop plants based on IPE results. Sandia National Labs., Albuquerque, NM (United States). Funding organisation: USDOE, Washington, DC (United States), 1995.
- Norman C. Rasmussen, et al., “Reactor safety study. An assessment of accident risks in U. S. commercial nuclear power plants. Executive Summary.” WASH-1400 (NUREG-75/014). Rockville, MD, USA: Federal Government of the United States, U.S. Nuclear Regulatory Commission, 1975
- 高成炎, 台灣核電廠發生爐心熔毀核災機率高達24%, 台灣環境保護聯盟, 2013
- 陳立誠, 回應彭明輝:有核不可–8個核心問題,快速理解核四, 台灣能源, 2014
- IAEA, The International Nuclear and Radiological Event Scale, IAEA, 2008
- Leurs, B. A., et al. Environmentally Harmful Support Measures in EU Members States. CE, Solutions for environment, economy and technology, 2003.
- Regulatory Guide 1.174 – An Approach for Using Probabilistic Risk Assessment in Risk-Informed Decisions on Plant-Specific Changes to the Licensing Basis, USNRC, 2002
- Kadak, Andrew. 22.091 Nuclear Reactor Safety – 12.Safety Goals Risk Informed Decision Making, Spring 2008. (MIT OpenCourseWare: Massachusetts Institute of Technology)
- S.E. Cooper, et al., A Technique for Human Error Analysis (ATHEANA) (NUREG/CR-6350), USNRC, 1996
- David I. Gertman, et al., Review of Findings for Human Performance Contribution to Risk in Operating Events (NUREG/CR-6753, INEEL/EXT-01-01166), USNRC, 2002
- D.I. Gertman, et al., The SPAR-H Human Reliability Analysis Method (NUREG/CR-6883, INL/EXT-05-00509), USNRC, 2005
- PRATT, William T., et al. An approach for estimating the frequencies of various containment failure modes and bypass events. BROOKHAVEN NATIONAL LABORATORY (United States). Funding organisation: DOE/NRC (United States), 2004.
- 福島核電廠事故調查報告書 (翻譯)
- Q4-4:何謂核能電廠安全度評估?, 行政院原子能委員會
- 台灣電力公司, 因應日本福島電廠事故台電龍門核能發電廠壓力測試報告(Rev.1b), 行政院原子能委員會, 2013
- 李敏. “核電廠嚴重事故處理導則對核二廠二階層安全度評估結果的影響.”, 2005
- 核子反應器設施運轉執照申請審核辦法, 行政院原子能委員會
- 核子反應器設施管制法, 行政院原子能委員會
- 核子反應器設施管制法施行細則, 行政院原子能委員會
- Unit Capability Factor, IAEA
- 與國際主要電業之比較, 台灣電力公司
- Moody’s assigns A1 and Aaa.tw ratings to Taiwan Power, Moody’s Investors Service, 2007
- 唐子富, 從日本電力公司篡改數據事件 看核安文化, 原子能委員會, 2007
- 2-4、聽說核四接近斷層又靠近海邊,它經得起地震和海嘯嗎?, 經濟部
- 福島事件後台電因應作為, 台灣電力公司
- Oxford Centre for Evidence-Based Medicine 2011 Levels of Evidence, CEBM, 2011
- 林希陶, 科學證據也有分等級?, Pansci, 2014






































{kind=link}
{kind=link}
{kind=link}