

在國中的物理課程中,我們學到光是由光的三原色所組成,分別是紅色、綠色和藍色,這三種顏色的光組成了我們五彩繽紛的世界。但是在 1878 年,由 Ewald Hering 所提出的色彩拮抗論則是提出了四色論的論點,這個論點主張色彩的視覺系統主要是由紅、黃、藍、綠四個顏色所組成的。這個論點獲得了許多的支持,例如色彩命名實驗中,把各種在可見光譜上出現的顏色呈現給受測者,要求他們以自己認為最精準的詞彙說出顏色的名稱,果不期然,紅、黃、藍、綠四個顏色果然特別突出,最容易被受測者所判別。這是怎麼回事?光只有三原色,可是我們的眼睛卻以四個顏色為基礎?
我們在「低解析度的人類視網膜?」討論過視網膜上的細胞主要分成錐細胞和桿細胞兩種,而其中經過實驗的證實錐細胞的光譜吸收曲線,主要是在光譜上的 450 nm、540 nm 和 580 nm 三種波長,剛好對應到藍、綠、紅三種顏色的光線。我們可以簡單的想像我們的眼睛裡面主要有三種細胞,分別負責不同的波長的光線,然後排列組合後變成了我們看到的世界。但這依舊沒有辦法解釋黃色是怎麼被我們當成基本色的?
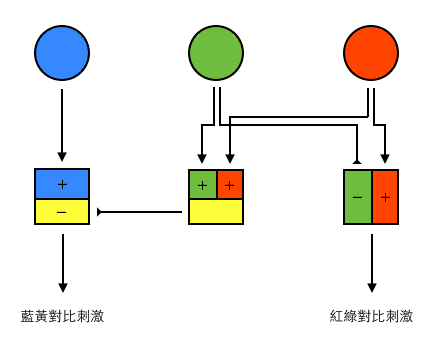
如果我們更深入的研究視網膜,會知道錐細胞和桿細胞接收到刺激以後,把這些刺激轉成訊號交給水平細胞和兩極細胞接手,奇蹟就在這裡發生了,訊號在這裡被重新排列組合,達成一種非常類似電子訊號常距離傳遞的方法,來幫助我們降低色彩訊號的干擾。如下圖所示,紅色和綠色分別被相加與相減,而被相加的紅綠訊號則形成了黃色訊號(就像我們用 RGB 色碼一樣,FF0000 紅色加上 00FF00 綠色則變成了 FFFF00 黃色),最後黃色訊號再與藍色訊號進行對比。這個神奇的轉換把視網膜上接收到的絕對訊號轉換成了相對訊號,就像電子訊號一樣,相對訊號被送到大腦即使衰減,也可以利用類似放大器的機制來還原感受。
這似乎解釋了我們對色彩後像(Color Afterimage)的成像原因,所謂的色彩後像,是指我們的盯著某個顏色 30 秒,然後將眼球的注意力移動到白色的區域上,原本在視網膜上面的成像會變成非常鮮明的對比色。例如下圖的紅色正方形,注視 30 秒後看旁邊的白牆,會出現非常清楚的綠色。而藍色的對比則是黃色,這些互補關係都是因為我們已經被刺激到的細胞疲勞,所以誤判顏色訊號所導致的。

我們對於光的感覺本來就具有色彩恆常性,不管我們在黃光還是白光底下,幾乎都可以正確的判斷出紅色、綠色與白色等顏色。一個紅色的蘋果被拿到其他顏色的光線底下,我們還是可以判斷出他是紅色的蘋果。對於光的強度也有類似的效應,我們在電影院裡面看到的海灘陽光,跟真正的海灘陽光的照度有絕對的差距,但我們依舊還是會覺得電影裡的陽光很刺眼。就像數位相機需的自動調整白平衡功能,我們的大腦似乎天生就具備了這種機制,幫助我們快速的調整並適應各種環境與光源。
參考文獻:
- 陳一平(2011)。視覺心理學。台灣:翔郁整合行銷。
- Ware, Colin (2008). “Visual Thinking: for Design”
(Image via Raksh1tha, CC License )
延伸閱讀:
Desiring Clicks 是一個專門介紹使用者介面、使用者經驗、視覺設計、資訊架構和網路行為的網誌。歡迎你一起參與介面設計,讓這個世界變得更美好。







































