

- 在人工智慧崛起的現在,你希望看見甚麼樣的未來?當人工智慧超越人類時,人類該何去何從?人工智慧對犯罪、戰爭、司法、工作、社會將造成甚麼影響?又會帶給生而為人的我們甚麼感受?《LIFE 3.0》將毫不隱諱呈現這個最具爭議性話題的全方位觀點,舉凡超人工智慧所代表的意義,意識究竟是怎麼一回事,甚至是宇宙生命發展最終的物理法則定律極限,包羅萬象的豐富內容,盡皆收錄在《LIFE 3.0》中。
- 迎接人工智慧時代,你我都該上的 30堂必修課

人工智慧將在就業市場造成什麼樣的改變,進而影響身為勞動階級的我們?如果我們能找出透過自動化創造富裕,同時又不會讓人失去收入和使命的辦法,就有機會創造輕鬆寫意的美好未來,帶給每個人夢想中前所未有的富裕。對於這樣的願景,沒有多少人比我在麻省理工學院的同事、經濟學家布林優夫森(Erik Brynjolfsson)想得更透澈。雖然他總是衣著得體,但是內心深處依舊保有冰島人獨特的靈魂,前不久他為了更加融入商學院才略加修剪儀容,而我卻始終忘不了他一臉維京人式紅色虯髯大鬍的模樣。
所幸他腦海中狂野的想法並沒有跟著鬍子一起剔除,他還把自己對就業市場樂觀的期望稱做「數位雅典城」(Digital Athens)。古代的雅典公民之所以能享有民主、藝術和遊樂的安逸生活,主要因素不外乎是有一群奴隸代為從事勞動工作,所以我們為什麼不用具備人工智慧的機器人取代古代的奴隸,建立人人都能樂在其中的數位烏托邦?布林優夫森認為,以人工智慧推動經濟發展,不但能夠一方面消除工作的壓力和苦差事,另一方面如我們現在所願生產出各式各樣豐富的產品,更可以超乎現在消費者的想像,提供各種奇妙的新產品與新服務。
科技發展與分配不均──最富有1%與後頭90%的人命運大不同
只要從現在起,我們每個人的薪資待遇都能逐年成長,將來就能走進布林優夫森描述的數位雅典城,讓每個人的工作量愈來愈少,生活水準愈來愈高,過著充裕休閒的生活。
美國自二次世界大戰後一直到1970年代,就是循這樣的模式發展:
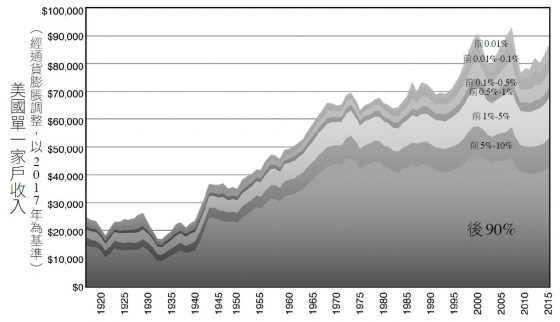
雖然收入分配有所不均,但是經濟大餅維持一路成長,幾乎雨露均霑的讓所有人都得到更多好處。不過布林優夫森等人開始注意到,自1970年代以後,事情發展有些不一樣了:圖中的經濟規模雖然還是維持成長的趨勢,平均收入也跟著水漲船高,但是過去四十多年來成長的果實卻都流入最富有的一群人手中,甚至幾乎只進入最富有1%的人的口袋裡,而後頭90%的人卻發現自己的收入止步不前。

如果我們把觀察指標從收入換成財富,分配不均惡化的情況會益發明顯:美國90%家庭在2012年的淨資產是八萬五千美元(跟二十五年前一模一樣),而最富有1%家庭的淨資產即便經過通貨膨脹,在這段期間的成長仍舊超過了一倍,達到一千四百萬美元。以全球的角度來看,分配不均的差距更是極端。2013年全球排名後半段所有人(總共超過三十六億人)的整體財富,剛好跟全球前八名首富的財富旗鼓相當。這個統計數字完全應驗了「朱門酒肉臭,路有凍死骨」這句話。
2015年在波多黎各的那場研討會上,布林優夫森語重心長的向各路人工智慧專家表示,他同意人工智慧和自動化技術的進步會讓經濟大餅愈做愈大,但是並沒有任何一條經濟定律能保證所有人都能獲利,就連是否能讓大多數人得利都得打上問號。
分配不均問題出在哪?──傳統工作被取代、資本優勢更明顯、超級巨星理論
大多數經濟學家都同意,分配不均的現象愈來愈明顯,不過對於成因及未來發展趨勢的看法卻大相徑庭。政治立場傾向左派的人認為,全球化再加上對富人有利的減稅政策,是造成分配惡化的主因,而布林優夫森和他在麻省理工學院的同僚麥克費(AndrewMcAfee)則認為真正的成因是另外一回事:科技發展。針對數位科技對分配不均的影響。他們提出三種不同的分析角度。
首先,科技發展使傳統工作由需要更高度技能的工作取代,因而凸顯教育的重要性:自1970年代中葉開始,順利畢業取得文憑的勞工薪資待遇提升了25%,而中學輟學的勞工平均而言則少了30%的薪資待遇。

其次,他們認為自從2000年開始,企業營利以前所未見的比率流向企業主,而不是往勞動階級移動—只要自動化的趨勢維持不變,不難想見擁有機器設備的人一定會分到比較多的經濟成果。在進入數位經濟的年代後,資本相對於勞力的優勢只會更為明顯,一如科技趨勢專家尼葛洛龐帝(Nicholas Negroponte)提出的觀點:
這是由原子世界蛻變至位元世界的過程。現在不論是書本、電影還是稅務試算表都已經數位化,往世界各地多賣幾份商品所增加的成本趨近於零,而且還不用額外增聘員工。這個趨勢自然會讓投資人而不是員工取得大多數的收益,也能解釋為什麼底特律三大公司(通用汽車、福特汽車和克萊斯勒),2014年的合併營收幾乎和矽谷三大公司(Google、蘋果和臉書)不相上下,但是後者的員工人數不但只有前者的九分之一,在股市中的價值更是前者的三十倍以上。
第三,布林優夫森等人認為,超級巨星會比一般民眾更容易享有數位經濟的好處。哈利波特的作者J.K.羅琳(J.K. Rowling)成為有史以來第一位晉升為億萬富翁的作家,她比莎士比亞更有錢的祕訣在於,她的故事內容可以用極低的成本轉換成文字、電影和遊戲等各種不同形式供世人傳頌。

相同的道理,庫克(Scott Cook)藉由自己開發的稅務軟體TurboTax致富,這套軟體當然也異於一般人類的稅務會計,是可以從網路上購買的。至於排名第十的稅務軟體,大多數人不管再便宜也沒多大意願使用,因此這個市場裡能容下的自然只剩下少數幾位超級巨星了。
給孩子的職涯建議:朝目前機器還不擅長的領域發展
在這種情況下,我們到底能給孩子什麼樣的職涯建議?我會鼓勵我的孩子朝目前機器還不擅長的領域發展,以免在不久的將來淪為自動化作業的犧牲品。如果要預測各種工作大概多久以後會由機器取代,不妨先參考以下幾個有用的問題,再決定將來要就讀哪些科系,進入什麼領域就業:
- 這個領域需要運用社交手腕和他人互動嗎?
- 這個領域需要運用創意提出巧妙的解決方案嗎?
- 這個領域需要在無法預測的環境下工作嗎?
當你愈能用肯定的方式回答,你選到好工作的機率就愈大。換句話說,幾個相對安全的職業項目分別是:教師、護理師、醫師、牙醫、科學家、創業者、程式設計師、工程師、律師、社工人員、神職人員、藝術工作者、美髮師或是推拿師傅。

相較之下,在可預期的環境下重複執行高度結構化的動作,這種工作型態在自動化的影響下可就岌岌可危了。電腦和工業機器人早就已經接手簡單到不行的工作,隨著科技持續演化,受取代的工作只會愈來愈多,諸如電話行銷、倉儲管理、櫃台職員、列車司機、麵包師傅和廚房助手都算在內。接下來,開卡車、巴士、計程車的司機,甚至就連Uber和Lyft的駕駛都可能是下一波被取代的對象。另外還有很多職業項目(比方說律師助理、徵信業者、放款業務、記帳人員和稅務會計等)雖然不至於列入全面取代的危險名單,但是大多數工作內容還是能被納入自動化的作業流程中,使得人力需求大幅減少。
單是設法和自動化作業保持距離,還不足以完全克服將來職場上的挑戰,當全世界都進入數位化的年代,想要成為專業的作家、製片、演員、運動員或時尚設計師,還要面臨另一項風險:雖然這些職業短時間之內不會立即面臨機器帶來的激烈競爭,但是回顧先前提到的超級巨星理論,這些領域一樣要面對來自全世界的專業人士帶來的愈來愈嚴酷競爭壓力,真正能成為贏家的人可以說是少之又少。
職涯建議:不可預期的環境、非重複執行、非高度結構化的工作
通常來講,如果要對所有領域、所有層級的工作做出職涯建議,未免流於太過草率:很多工作並不會完全消失,但也會有很大一部分被自動化取代。如果你打算行醫,千萬別擔任分析醫療影像的放射科醫師,因為IBM的華生電腦會做得比你更好,不妨考慮擔任有資格要求做出放射影像分析,可以拿著檢驗報告跟病患商討要如何進行後續診療的醫師。

如果你想往金融界發展,千萬別擔任只會拿數字套用演算法的「寬客」(quant),這種工作可以輕易被軟體取代,倒是可以考慮擔任利用量化分析做出投資策略的基金經理人。如果你擅長的領域是法律,那就別以埋首文件找資料的律師助理自滿,這種工作靠自動化作業就可以了,你應該要以能提供客戶諮詢服務,能站上法庭進行官司訴訟的律師為目標。
以上,我們說明了在人工智慧年代下,個人如何在就業市場盡可能擴大自己成功的機會。政府部門能夠做些什麼,好幫助國內的勞動力邁向成功?像是什麼樣的教育體系最能夠幫助民眾做好準備進入職場謀生,不用擔心人工智慧持續快速的改善?現行先經過十幾、二十年的求學階段,隨後將四十年的歲月都投入專業領域的模式仍舊適用嗎?或者改成先工作幾年,用一年的時間回到學校加強技能,之後再重回工作崗位,依此不斷重複循環的體系比較好?還是說,我們應該讓推廣教育(或許是以線上授課的方式進行)成為所有工作的標準配套措施?
另外,什麼又是最有助於創造優質新工作的經濟政策?麥克費認為,很多政策都值得考慮,像是在研發、教育和基礎建設等方面進行大規模投資,吸引外國人才融入本國社會,還有提供誘因鼓勵創業等政策皆屬之。他認為「經濟學原理在教科書上都寫得一清二楚,問題是沒有人有辦法照著做」,起碼美國就沒有做到這一點。

本文摘自《LIFE 3.0:人工智慧時代,人類的蛻變與重生》,天下文化出版。
延伸閱讀:






































