


文/于天立|台灣大學電機系教授
相信 2016 年 3 月 12 日是個日後常常會被提起的日子。因為在這一天,電腦圍棋第一次在分先的情況下戰勝了人類一線職業棋手李世乭。
圍棋被認為是人類發明的棋類中最複雜的,在 IBM 開發的「深藍」超級電腦,於 1997 年擊敗西洋棋世界棋王後,圍棋被許多人認為是人類對抗人工智慧的最後一道防線。
圍棋有多困難呢?
有不少人估計過圍棋所有可能的盤面狀況,我個人認為約 10170 是很合理的估計(西洋棋約為 1047)。而這個數字有多大呢?姑且假設電腦一秒鐘可以探索 1020 種不同的盤面狀況(目前根本做不到),要暴力搜尋完所有可能也需要超過 10140 年,而我們目前所估計這個宇宙的年紀僅僅約 1010 年而已。
西洋棋單一個盤面能下的合法步數平均約為 40 左右,而圍棋一開始就有 361 個合法下法。當然你可以說因為有對稱性等等,其實沒那麼多。沒錯,不過這對稱性大概在第 4 手、第 5 手就消失殆盡,就算我們扣掉一開局不太可能在邊線落子,我們說圍棋平均合法下法在 100~200 以上並不為過。這使得深藍所使用的搜尋、剪枝技術在圍棋上派不上用場。

身為圍棋及人工智慧的愛好者,我個人也非常關注這次的賽事。更正確的來說,自從 Google 在 Nature 期刊發表了AlphaGo 5:0戰勝歐洲圍棋冠軍,職業圍棋二段樊麾(第一次電腦圍棋在分先的情況下戰勝人類職業棋手), AlphaGo 就成了許多人工智慧研究者關注的焦點。AlphaGo 戰勝李世乭後(目前是 3:1),這成為了我和一些親朋好友之間的話題。說實話,我個人賽前也看好李世乭。我們知道這一天遲早會到來,我個人以為總還要三、五年的時間,但真的沒想到這一天來的這麼快。
AlphaGo的勝利優勢
關於圍棋,比我專業的人太多,這邊我只簡單從演算法的角度講幾句。AlphaGo 中所使用的蒙地卡羅法,所搜尋的是最大勝率的一步,而並非最好的一步。也就是說,當 AlphaGo 佔優勢時,它應該會試著以最穩定的方式贏棋,這可能是為何在第1、2局中我們看到 AlphaGo 似乎有避劫的意圖。因為不需要打劫就能贏棋,不需要無謂地增加不確定性。而同樣的在第4盤後期,我們看到 AlphaGo 無所不用其極地做些試驗(例如無謂的一線立下,招致損目),因為局勢不利,而那些是少數有可能贏棋的下法,即使人類看來似乎很幼稚,但對演算法而言是合理的下法。話又說回來了,真的覺得 AlphaGo 下的可笑的話,不如去向 AlphaGo 討教幾盤。綜合目前4盤來看,我們不能以人類的方式去理解 AlphaGo。
AlphaGo 的實力已獲得証明,它並不如賽前大家想像中的弱,但也並非完美無瑕。
對於電腦圍棋,我發現不少人有一些錯誤的認知,像是:(1)電腦能背那麼多棋譜、(2)現在電腦速度那麼快,所以當然會贏。下面我想就這兩點說明一下。
棋譜背的多就會贏?
在這次的五局賽的第一局,也許是出於試探,李世乭選用了職業賽中未曾見過的開局,而 AlphaGo 正確應對,早早在序盤便取得優勢。第二局中,李世乭小心的選用了常見的開局,AlphaGo 卻在第 13 手下出了職業棋譜中從未出現的一手,這手新著使得李世乭離開座位去抽根煙苦思對策。這些都說明了AlphaGo是從眾多的棋譜中學習,而絕非死背。
電腦速度快就會贏?
摩爾定律常見(但不精確)的一種解讀是每 18~24 個月,電腦效能就增進一倍。這個「定律」在大約 1965 年被提出來後,雖然常常被大家以為已經到了極限,但事實上至今仍然成立。不過我們首先要對「效能增進一倍」是什麼意思說清楚一點。現今的 CPU 時脈可達 3.5 GHz,已進入了 wifi 傳輸頻帶(2.4 GHz及 5 GHz),而power density(每單位面積的能量)約相當於1/10核能發電機的 power density。
換言之,目前單顆核心的運算效能幾乎已經達到了物理極限。那摩爾定律又是如何被維持的呢?是的,就是多核心技術。CPU如此,GPU更是多核心技術發揮的地方。打敗李世乭的分散式 AlphaGo 使用了 1920 顆 CPU 及 280 顆GPU。Google 並未說明所使用的 CPU/GPU 規格如何,但我們姑且以 TESLA S1070 為例,它就含有 960 核心。
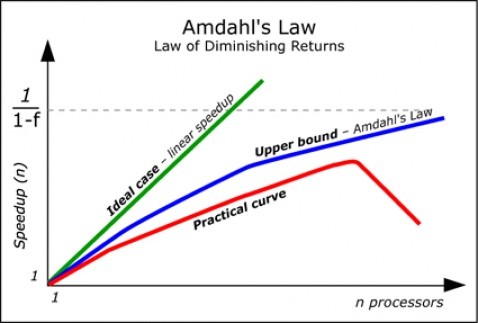
然而,越多核心就會越快?這可不一定。阿姆達爾定律(Amdahl’s Law)說明了這個現象,而其大致可用如下的式子表示:

其中(不可平行化比例 + 可平行化比例)= 1,而不可平行的部份原因多半是資料相依性。也就是可能某一運算需要使用到上一個運算的結果,如此一來此兩運算就無法在同一時間分別用兩個核心完成。舉例來說,若一演算法約有一半的部份可被平行化,則無論我們給它多少的運算資源,至多也只能加速兩倍。如果我們考慮產生及結束執行緒(thread)所需的額外花費,有時產生過多的執行緒反而會使程式變慢。至於有效利用平行/分散式運算資源,Google 有著多年的經驗,這也是 AlphaGo 成功的一重要因素。
Google使用了新的演算法嗎?
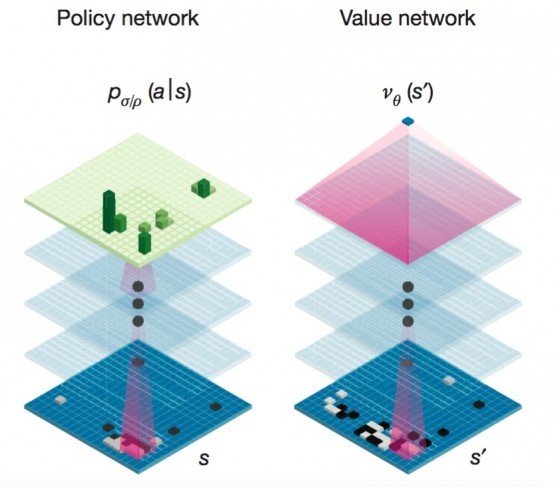
根據 Google 在 Nature 期刊發表的論文,其主要的核心技術在:(1)深度神經網路、(2)加強式學習、(3)蒙地卡羅樹狀搜尋。AlphaGo 使用了兩個深度神經網路,一用來評估盤面狀況,一用來預測下一落子,這兩者可大幅縮減搜尋複雜度。而深度神經網路的特點在於可自動產生特徵,然後利用這些特徵來做分類。AlphaGo 很重要的特點在於可以自我訓練。這是藉由加強式學習將深層搜尋的結果回饋給神經網路做修正。這個特點使的 AlphaGo 能下出自我的風格,而非一味背誦模仿。
嚴格說起來,以上三項技術都不是 Google 發明的。然而如此組合出 AlphaGo 當然得歸功於 Google。(把加強式學習組合到深度神經網路的方式是由DeepMind公司所發展,於2014被Google收購)。至於有些人認為僅僅是組合已有的演算法並沒有什麼實質貢獻,我覺得這是沒有真正了解系統的概念。這就好比說廚師所用的食材都不是自己種/養殖的,所以煮出一道出色的菜餚並沒什麼了不起一樣的可笑。要知道機器學習的演算法有千千萬萬種,找出其中正確的組合何其困難。更不用說就算知道要用哪些演算法,組合的方式也無法計數,有時為了有效的組合運用及配合平行運算,還需要修改原來的演算法。這些方方面面,沒有一件是簡單的事,但Google做到了,實在值得我們喝采。
人工智慧贏了人類之後,要走向哪裡?

和深藍不同的是,深藍所使用的技術僅能適用於兩人回合制棋類,且盤面可能性不能太多。而 AlphaGo 所使用的技術,就我個人看來,應該適用於一般連續性決策問題。因為 AlphaGo 是在眾多可行的決策中,適當分配運算資源來探索此一決策所帶來的好處及壞處,並且可從探索中回饋修正錯誤。這樣的學習模型無疑地用途是比深藍更加廣泛的。
下一步呢?如上所述,即使 AlphaGo 所使用的學習模型比較具有一般性,但離真正完全通用的學習模型仍有一段距離。其實 IBM 發展的 Watson 也是嘗試著整合許多演算法,從而提供一通用學習模型,可見得這會是未來人工智慧的趨勢。
最後,我們更希望可以從學習模型中萃取出人類能理解且有用的知識。再以 AlphaGo 為例,就算 AlphaGo 真能完勝人類棋手,就我的理解,它目前還無法直接教人類如何下圍棋。是的,你當然可以拿著棋譜,看看 AlphaGo 會下在哪裡。但是如果你問 AlphaGo 為何要下這裡時,它可能會說因為這裡算出 87% 的勝率,而我們人類需要的可能像是:「如果這邊打入活一塊的話,相對地可以威脅上邊的……」而這類型的自動知識獲取,將會是人工智慧未來得面對的更重大的挑戰。









































#/media/File:Go_board.jpg){kind=link}
{kind=link}