這些太空垃圾會不會阻礙我們太空旅行?太空垃圾怎麼清?
人類上太空的夢想會被我們親自摧毀嗎?
隨著火箭成本降低,人人都能把衛星丟上太空,現在,當你晚上抬頭看天空,你看到的星星可能不是星星,而是人造衛星。你看到一閃而過的的流星,可能只是墜入大氣的太空垃圾。
這些多到不行的太空垃圾已經成為隱憂,更可怕的是,這些以超音速飛行的太空垃圾可能摧毀其他衛星,在衛星軌道上製造更多不可預期的致命飛彈。有人擔心,人類終有一天會無法穿過這片垃圾雲,天空永遠被自己封閉。 終於,有人提出清理太空垃圾的方法了,但這些方法真的可行嗎?
現在的太空垃圾有多少?
最大的太空垃圾可能是整節火箭!
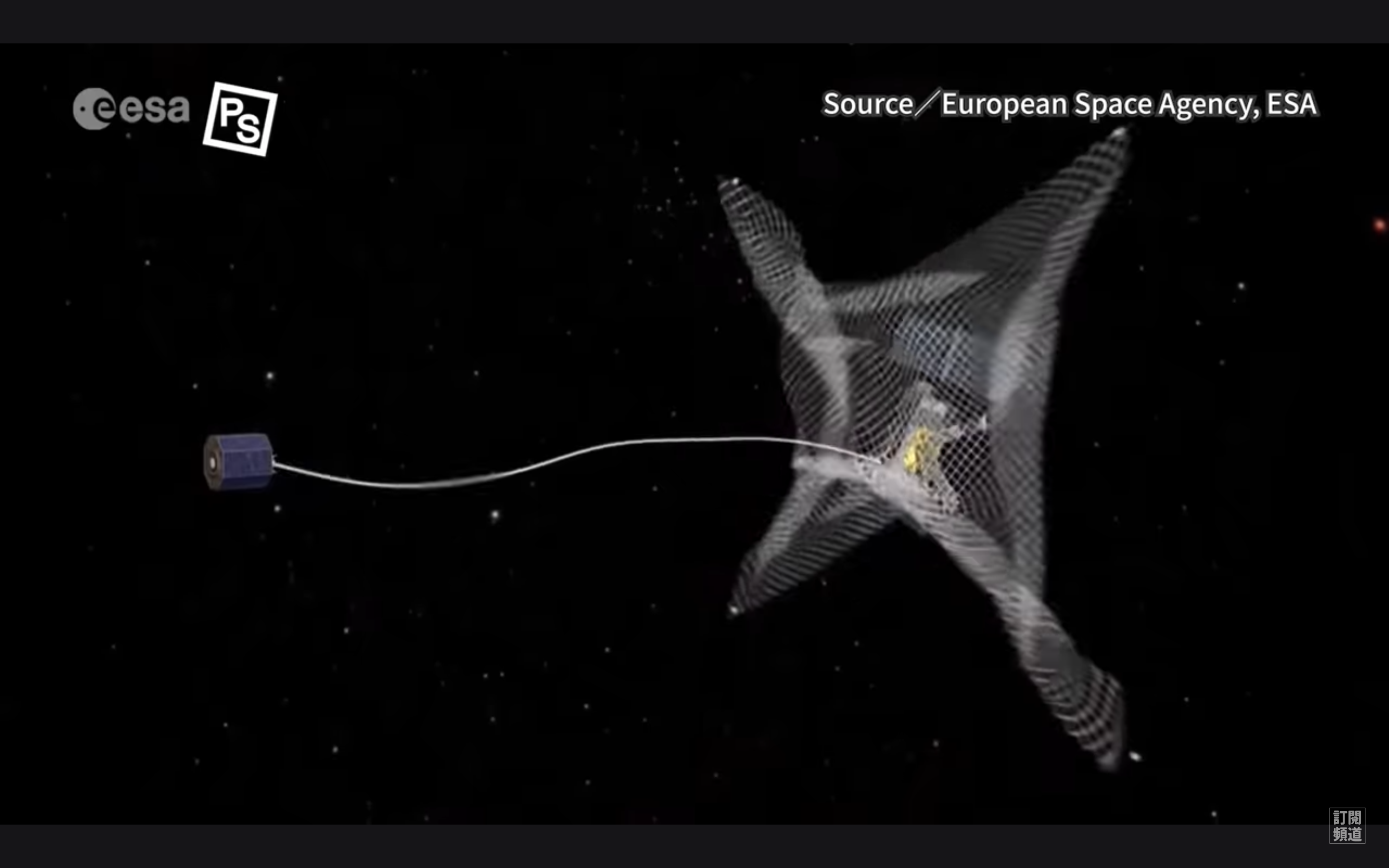
所有在繞行地球的軌道上失去功能的東西,都會成為太空垃圾,最大的包含壞掉的衛星、和大量運送衛星上太空的第二節推進火箭,例如 1960 年代太空競賽時大量發射的火箭,有許多至今還在宇宙遊蕩,每一個都像公車一樣大。而小東西,則包含太空人在太空漫步時遺忘的東西,或是太空垃圾互相碰撞後產生的碎片,最小可能只有數毫米,小的像隻蚊子。但不論太空垃圾來自哪裡,只要缺乏妥善的管理和追蹤,就可能成為其他運作中設施和儀器的致命血滴子。
所有在繞行地球的軌道上失去功能的東西,都會成為太空垃圾,最大的包含壞掉的衛星、和大量運送衛星上太空的第二節推進火箭。PanSci YouTube
為什麼說太空垃圾真的很危險?
為了不被地心引力拉入大氣,墜向地球,在軌道上繞行地球的物體大多都以非常快的速度在移動,包括現在還在運作的衛星與各種設施。舉例來說國際太空站位於距離地球表面四百公里高的近地軌道(Low Earth Orbit),以大約每秒 7 ~ 8 公里的速度高速移動,是地表音速的 20 倍。也就是說,太空上的車禍可嚴重多了,來自不同方向或不同傾角的物體,可能會以超過每秒 10 公里的相對速度發生碰撞。別說公車大小的太空垃圾了,只要直徑超過 1 公分的碎片就足以對太陽能板或玻璃造成損害。更麻煩的是,大小在 10 公分以下的物體,大多還因為尺寸過小難以追蹤。
那麼,我們的頭上有多少太空垃圾呢?
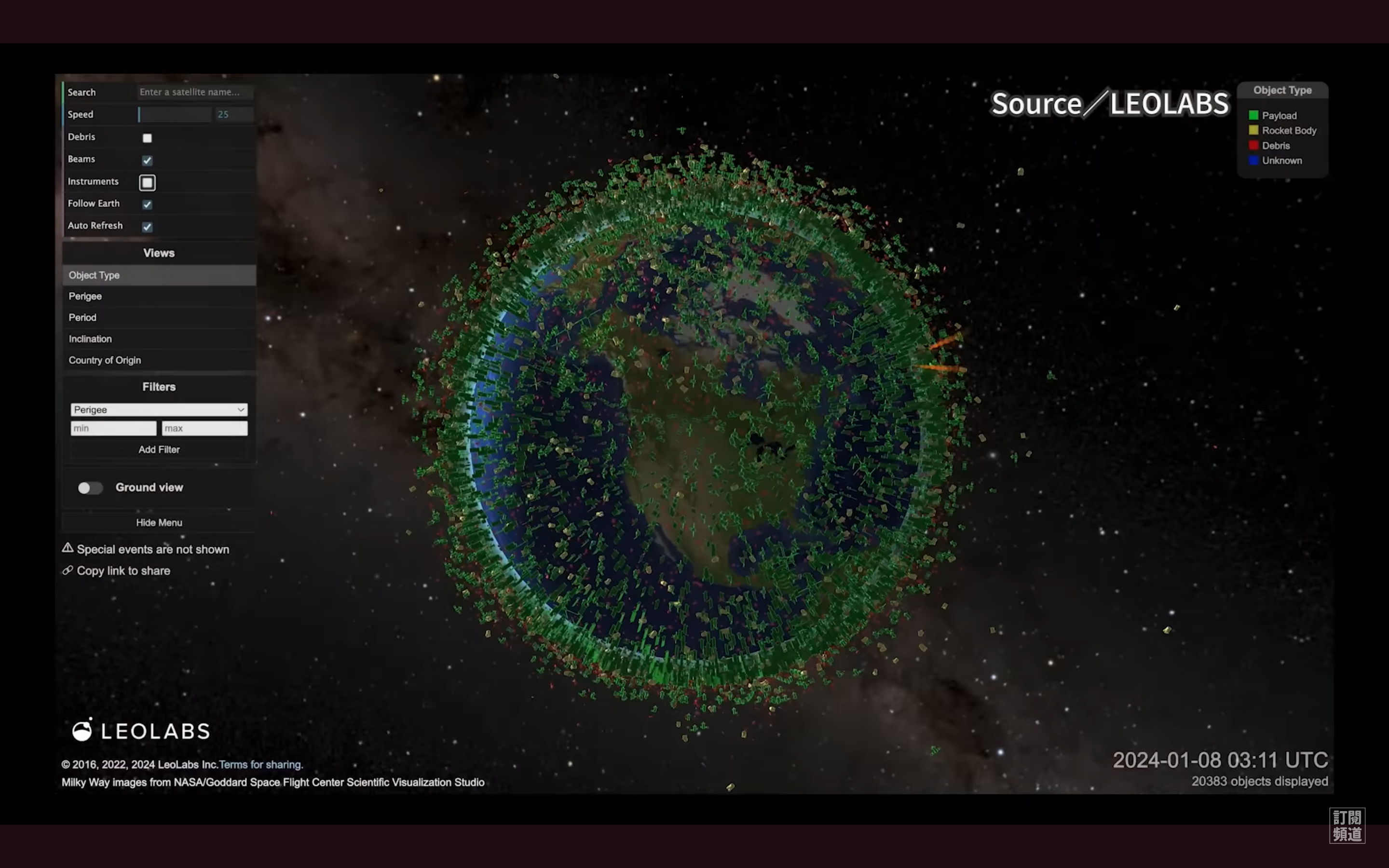
根據歐洲太空總署 ESA 的資料,目前軌道上有 6800 個運作中的衛星,相對的有超過 3 萬 2千個可追蹤的太空垃圾。但如果估計所有無法追蹤的物體,大於 10 公分的物體可能有超過 3 萬 6 千個,介於 1 公分到 10 公分的則高達一百萬個。
根據歐洲太空總署 ESA 的資料,目前軌道上有 6800 個運作中的衛星,相對的有超過 3 萬 2 千個可追蹤的太空垃圾。但如果估計所有無法追蹤的物體,大於 10 公分的物體可能有超過 3 萬 6 千個,介於 1公分到 10 公分的則高達一百萬個。PanSci YouTube
在這些太空垃圾中,大多數大型太空垃圾就是來自發射衛星後,一起留在太空的第二節推進火箭,小型太空垃圾則來自火箭爆炸或各種大大小小碰撞所產生的碎片。
太空上曾發生過嚴重的太空垃圾碰撞事件?
歷史上比較嚴重的一次撞擊事件發生在 2009 年,銥衛星公司運作中的通訊衛星,重量 700 公斤的 iridium 33,和失效、重 900 公斤的蘇聯軍用衛星 kosmos 2251,在 789 公里的高空,兩台衛星以每秒 11.7 公里的相對速度直接撞上,化成了兩團在軌道上繞行的碎片團。
NASA 估計,這單一次的碰撞產生了超過 2000 片可追蹤的碎片,雖然許多碎片受地球引力慢慢墜入大氣燒毀,但直到到 2023 年 2 月的統計,大約還有一半,也就是 1000 片碎片留在軌道上。過往也曾經觀察到碎片從距離國際太空站僅 100 多公尺的位置驚險掠過。
如何解決太空垃圾的問題?
太空垃圾又多又危險,真的有辦法清除嗎?
2023 年三月,NASA 發表一篇研究,整理了關於各種清理太空垃圾的方法與成本,包含從地面或太空發射雷射推動垃圾改變軌道,或是直接物理性撞擊改變軌道,還有透過捕捉垃圾,直接在太空將垃圾循環利用,作為燃料或其他用途的再利用等方法。
清理不同大小的物體,要用的方法跟產生的效益也不同,因此他們評估了針對兩種策略。第一種策略將會優先處理目前最大、最具威脅性的 50 個太空垃圾,例如完整的第二節火箭或是失去功能的完整衛星。第二種策略則是優先移除 1 到 10 公分的十萬個小型垃圾。NASA 分別評估處理這兩種目標帶來的效益,恩,所謂的效益,就是預估能減少多少因為太空垃圾碰撞而產生的損失。
要如何移除太空垃圾呢?
移除大型垃圾主要的方法主要是再入大氣層(re-entry),簡單來說就是讓垃圾落入大氣層燒毀。這個方法預計讓運送任務完成的火箭載具,透過剩餘的推進燃料,順手將其他大型垃圾帶下來。移除這 50 個大型垃圾預計總共會花費 10 億美金,但在移除 30 年後所帶來的效益,將會超過花費的成本,非常划算。
至於小型太空垃圾,主要使用的方法將會是成本較低的雷射。藉由雷射產生的微弱動能來改變垃圾的軌道,將它們送入大氣層或推離常用的軌道。發射雷射的裝置可以設置在地面或是太空中,單純以使用效率來說,設置在太空所需要的能量較低,但是設置在地面維護和管理比較方便。然而這也衍伸了許多爭議,主要圍繞在這個清除垃圾的雷射也可以作為武器使用,例如在戰爭爆發時用雷射攻擊敵國的衛星。不過如果順利設置的話,清除十萬個小型垃圾後大約只要十年就可以達到等同於成本的效益,比移除大型垃圾能更快回收成本。
至於小型太空垃圾,主要使用的方法將會是成本較低的雷射。藉由雷射產生的微弱動能來改變垃圾的軌道,將它們送入大氣層或推離常用的軌道。PanSci YouTube
方法有了,但我們真的能讓太空再次乾淨嗎?
太空垃圾問題有解嗎?
現在的太空有多擁擠?
如果把歷史發射資料整理出來,會發現近五年人類的衛星發射數量幾乎是直線攀升,2012 年一整年全世界也只發射了 200 多顆衛星,到了 2022 年已經成長到一年 2000 多顆衛星。而且絕大部分都是來自於美國的衛星,想當然很大一部份都來自於 SpaceX 的星鏈計畫。而受益於獵鷹九號的高成功率和可回收造就的低廉成本,也能夠發射更多的中小型衛星,像是我們臺灣也發射了不少自主研發的立方衛星上太空,例如 2021 的「飛鼠」和「玉山」以及最近才剛發射的珍珠號立方衛星。
如果所有的衛星與火箭都會變成太空垃圾,我們清理垃圾的速度又不夠快,還有可能發生凱斯勒現象(Kessler syndrome),也就是碰撞產生的碎片引發連鎖反應,造成更多撞擊和更多碎片,讓不可控的太空垃圾快速增加,直到新的火箭與衛星都難以穿越,我們將無法前往太空,被自己的創造出的人造物封鎖在地球。
如果所有的衛星與火箭都會變成太空垃圾,我們清理垃圾的速度又不夠快,還有可能發生凱斯勒現象(Kessler syndrome),也就是碰撞產生的碎片引發連鎖反應,造成更多撞擊和更多碎片,讓不可控的太空垃圾快速增加,直到新的火箭與衛星都難以穿越,我們將無法前往太空,被自己的創造出的人造物封鎖在地球。PanSci YouTube
治標也要治本,我們對於即將發射進太空的人造物能有套管理辦法嗎?
1967 年在聯合國通過並簽署的《關於各國探索和利用包括月球和其他天體的外太空活動所應遵守原則的條約》,簡稱為《外太空條約》。這個條約制定了各國在外太空活動所應該遵守的原則,其中和人造衛星有關的原則主要有三個:
國家責任原則:各國應對其航太活動承擔國際責任,不管這種活動是由政府部門還是由非政府部門進行的
對空間物體的管轄權和控制權原則:射入外空的空間物體登記國對其在外空的物體仍保持管轄權和控制權
外空物體登記原則:凡進行航太活動的國家同意在最大可能和實際可行的範圍內將活動的狀況、地點及結果通知聯合國秘書長
也就是說,雖然各國需要將太空活動回報給聯合國統計,但實際上在制定規範和進行管制的還是各國本身。以美國來說,分別需要和 FAA 聯邦航空總署申報火箭發射和再入大氣層的計畫,以及向 FCC 聯邦通訊委員會申報衛星的通訊規格,至於要如何避免在太空發生碰撞,是發射單位要自己負起責任,公部門只提供有追蹤的物體軌道資料。
不過對於衛星任務結束後的處置,FCC 倒是有相關的規定和罰鍰。因為如果衛星有動力系統,可以在任務結束時就控制墜入大氣層或飛離常用軌道,進到所謂的死亡軌道(Graveyard Orbit),而通常在申請發射衛星時,也需一併提供任務結束後的處置方式。
去年,衛星電視業者 Dish Network 沒有按照它在 2012 年所制定的衛星處置計畫,將衛星從離地 36000 公里的地球同步軌道再往外推 300 公里。這顆衛星在移動的半途中就燃料耗盡失去了動力,只離開原本的軌道 120 公里,FCC 因此對衛星電視業者開罰了 15 萬美元。這起首次針對太空垃圾的開罰,對於太空垃圾的管制具有重大的意義,代表著對太空垃圾危害性的重視,也代表著清理太空垃圾的商機正在逐漸成長。
清除太空垃圾能有商業價值?
隨著商業化的太空活動逐漸熱絡,如何讓清理太空垃圾不只是空談也成了一個重要的問題。如果軌道上的垃圾減少,受益的會是所有使用軌道的衛星。就與現存的回收與垃圾處理方式一樣,我們可以規定所有衛星的生產者都必須繳交「太空垃圾處理費」,如果在發射的過程中產生額外的太空垃圾,則必須提高費率。相對的,如果一家公司提供清理太空垃圾的服務,則可以獲得這些「太空垃圾權」並換成對應的金額。
我們可以規定所有衛星的生產者都必須繳交「太空垃圾處理費」,如果在發射的過程中產生額外的太空垃圾,則必須提高費率。相對的,如果一家公司提供清理太空垃圾的服務,則可以獲得這些「太空垃圾權」並換成對應的金額。PanSci YouTube
另外,雖然目前對於在軌道上進行捕捉再回收的直接經濟效益並不突出,但如果未來在太空可以建立起專門的處理設施,或許可以作為一個長期的太空垃圾處理機制,沒想到吧,人類要成為跨行星文明的第一步,竟然是得先成立太空垃圾清潔隊。
不過話說回來,要讓各國政府願意砸大錢在太空垃圾回收產業可能還需要一點時間。畢竟相較於直接影響到生活的全球暖化,太空垃圾的危害並不那麼可怕,大型垃圾的撞擊也可以預測並提前避開,因此短時間內也還不會有明顯的感受,但如果你是需要觀測的天文學家,可能就覺得垃圾好礙眼了。
最後想問問大家,你覺得處理太空垃圾最好的辦法會是什麼呢?
向所有太空公司徵收處理費,培育回收業者,資本的事情資本解決。
從技術研發著手,火箭能回收,想必衛星回收技術很快也能做出來。
都別處理了,就等人類把自己鎖死在地球,宇宙垃圾就不會再增加了!
歡迎訂閱 Pansci Youtube 頻道 獲取更多深入淺出的科學知識!
參考資料