




「應該是這樣吧」。
許多時候我們遇到不懂的事情,常習慣就這麼歪頭兩秒鐘,然後,彷彿答案卡在腦袋裡面一樣,搖一搖,答案噗通一聲就掉出來了。
有人稱這是直覺。
然而,很遺憾地,大多數人的直覺都不是很準,不然就不會那麼多人在樂透選號時面帶微笑,還善良地想著要捐出一半頭彩。
要是理性點,應該會很憂心忡忡地想著:
50元花下去,中三碼的機率僅有1.78%,好低。
六碼全中的頭彩機率更是低到億分之7.15,比每天車禍致死的機率億分之5.25高一點點而已,唉。
就算不講容易讓人不理性的樂透,直覺在許多時候也經不起數學的檢驗。更正確一點的說法是,直覺本來就不大準,只是這世界並沒有太多事情能搞清楚對錯,所以不容易察覺到直覺到底有多不準。好比你覺得隔壁同學暗戀你,因為她下課常問你要不要一起去合作社,但事實上她只是單純想找人陪,可是在告白之前,你無法確認這件事情的真相。
更可悲的是,就算告白成功了,你還是無法確認她是否真的愛你。
聽不懂嗎?沒關係,再長大一點就懂了。
今天,我們藉由簡單的數學統計,讓大家實際看看,直覺跟事實間的差距,恐怕比藍綠兩黨之間的差距還大。後者至少還有「無能」、「貪汙」、「讓老百姓氣到高血壓」等等諸多族繁不及備載的共同點……。嗯,他們其實蠻像的,我似乎舉錯例子了。
※直覺 vs. 數學
翻開存摺,看看最左邊的數字,將這個數字稱為「首數」,一百多萬的首數是1,六千多元的首數是6,八十幾塊的首數即是8。現在,請用直覺判斷,全台灣兩千三百萬人的存款金額首數,1~9各個數字出現的機率各自是多少呢?
均勻分布,每個數字出現的機率皆是1/9。
許多人的直覺應該此刻在腦海裡吶喊著這個答案,還帶點不屑。
要是順從直覺,按照這個邏輯繼續推理下去,使用歐元的人的存款金額首數,日本人的日幣存款金額首數,每個數字出現的機率應該也都是1/9的均勻分布。沒理由這項統計數字在台灣是均勻分布,到歐洲或日本就會改變,大家理當都該一樣。
現在,當我們假設有9個人,戶頭裡各自有100、200…900元新台幣,符合均勻分布。要是銀行忽然將他們的存款改以日幣或歐元計算,會得到下表。
| 台幣 | 100 | 200 | 300 | 400 | 500 | 600 | 700 | 800 | 900 |
| 日幣 | 357 | 714 | 1071 | 1429 | 1786 | 2143 | 2500 | 2857 | 3214 |
| 歐元 | 2.5 | 5 | 7.5 | 10 | 12.5 | 15 | 17.5 | 20 | 22.5 |
可以看見,首數1從出現一次,大幅增加到三與四次,首數9則消失在表格中。
考慮更一般的狀況,可以得到下面的統計分析圖。當台幣換算成歐元或日幣時,首數數字小的出現機率都比較高。

至此,可以宣告直覺失敗,輸給了所謂的「班佛定律」:以自然形式出的數字,首數是1的機率約30%,2的機率是17.6%,依序遞減,首數是8與9的機率各自僅有5.1%與4.6%。
※班佛定律是哪招
要解釋這種不直覺的遞減現象,我們得先提一個生活中的例子。
想像一條長條狀的蛋糕,蛋糕上不同區域,有不同的裝飾:有些地方是草莓、有些地方是櫻桃、還有些地方是肉桂跟大蒜。
要是有四人想分這條蛋糕,而且每種裝飾都想吃到,最常見的作法,就是先將蛋糕由上往下,切成許多片,每一片的大小符合每個人能拿到的比例,切完後依序1、2、3、4、1、2、3、4…等分。每個人再根據自己的編號,週期性地挑出屬於自己的蛋糕。如同下圖,

上圖就是其中一人的切法。在每隔一段距離,切下等寬的一部份。可以確保每個人拿到他該拿到的比例,且各種裝飾都能拿到。我們稱這種為「理想蛋糕分法」。
回到首數的問題。
要是統計全台灣的人銀行存款,可以畫出存款的統計分布圖,我們用下面這張示意圖表示。
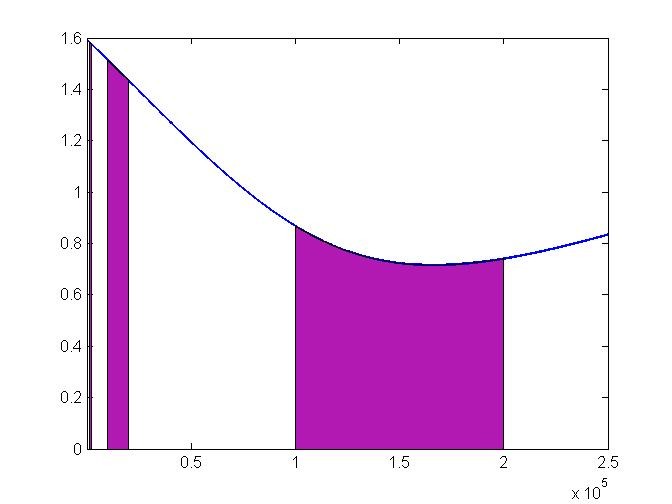
存款首數為1的區域我們用紫色表示。要是將整個曲線想成一條蛋糕,切下的紫色區域起先是一條細細的「1」,過了2~9後,再來一塊粗一點的「10~19」,這次得隔久一點,過了0~99,才會再出現更粗的「100~199」。然後,得一直等到「1000~1999」。
切下的區域分別是1、10、100、1000…切的間隔是8、80、800…。
換句話說,依據不同首數的蛋糕切法,在不同間隔間,切下大小不同的面積,不是剛才說的「理想蛋糕分法」。可能,落在300~500的櫻桃就這麼沒了。
不過,要是將x軸的金額取對數(log),就會得到下面這張圖。
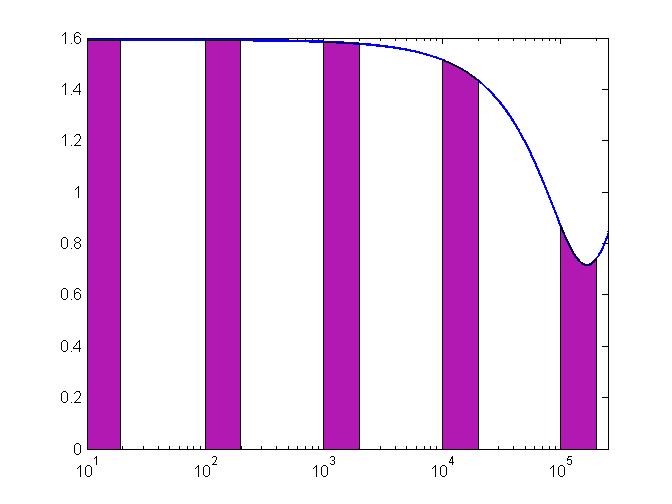
方才所說的「理想蛋糕分法」——等間隔切下同樣大小的區域,在此重現了。
因為是等間隔,不同區域的裝飾都能拿到,以取樣的角度來,就是取下來的部分能夠充分反映原來曲線的特性。
有趣的是,在對數轉換後,首數為1切下來的面積所佔比例是log102- log101=log2~30%,首數是2的比例則是log103- log102=log10(3/2)~17.6%,歸納出首數為x時,所佔比例為log10(1+1/x),。
這才是真正的首數分布。
回到剛剛不同幣值的問題,如果假設新台幣的存款首數分布是依據班佛定律時,換算成歐元跟日幣後,可以得到下圖
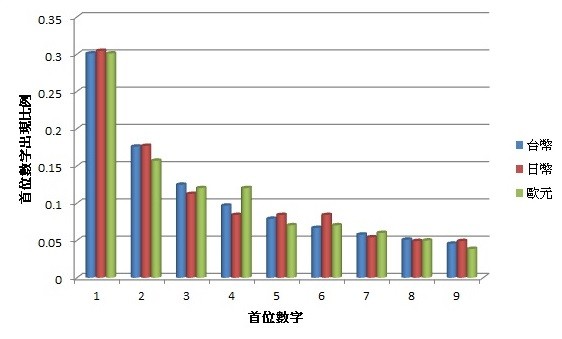
可以看見,換算到不同貨幣後,趨勢依然相似,大致依然符合班佛定律。終於,我們看到log離家出走,離開了數學課本。
※數學界的抓猴達人,班佛定律
只要是自然產生的數據,且數據涵蓋範圍很大,首數分布即會符合班佛定律。
因此,班佛定律相當具有實際用途。好比,統計公司一年的各種報帳款項,便會看見班佛定律的存在。政府或會計師即可反過來利用班佛定律,審核公司報帳是否誠實,如果不符合班佛定律,可能就有問題了。
奈何我無法拿中華民國各級政府,或首長特別費的資料實際測試一下班佛定律的威力(也怕測出來發現不符合,大家反而會說「這不是理所當然嗎」),只好拿2012總統大選全國各鄉鎮的投票結果來看:
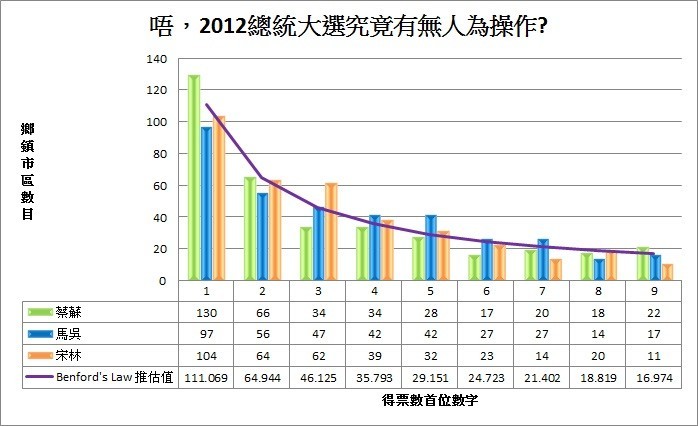
結果相當符合班佛定律,這告訴我們,要嘛總統大選沒作票,或者作票的人精通班佛定律,再不然就是,作票的人歪打正著還是讓結果符合班佛定律了。
從一開始就說,別相信直覺了嘛。
參考資料:
- R. M. Fewster, “A simple explanation of Benford’s law,” the American Statistician, vol. 63, no. 1, pp. 26-32, Nov. 2009.
註:更多賴以威的數學故事,請參考《超展開數學教室》。




























