
- 文 / 李翊瑞|雅文基金會聽語科學研究中心研究助理
在一場雞尾酒會上,有著豐盛的佳餚,以及來自四面八方的賓客。你與三五好友們正享受著派對的氣氛,開心地閒聊彼此的生活。儘管環境中充滿各式各樣的聲音—空調運行的風聲、會場的背景音樂、以及隔壁桌的談笑聲,似乎一點也不打斷你們之間交談的樂趣。然而,當你正專注地和眼前的朋友聊天,並聊得渾然忘我時,另一位好友在遠方呼喚你的名字,你卻能馬上回過頭去尋找聲音的來源,究竟是怎麼辦到的呢?

左耳進,左耳出?雞尾酒會效應的發現
前面所提到的現象稱為雞尾酒會效應(cocktail-party effect),指的是在環境中其他對話或噪音干擾的情況下,選擇性聆聽特定聲音的能力[1]。雞尾酒會效應最早是由英國認知科學家 Colin Cherry 於 1953 年提出[2],有趣的是,Cherry 在進行研究時,並沒有舉辦或者參加了很多場雞尾酒會,而是設計了一項名為跟讀(shadowing)的實驗。
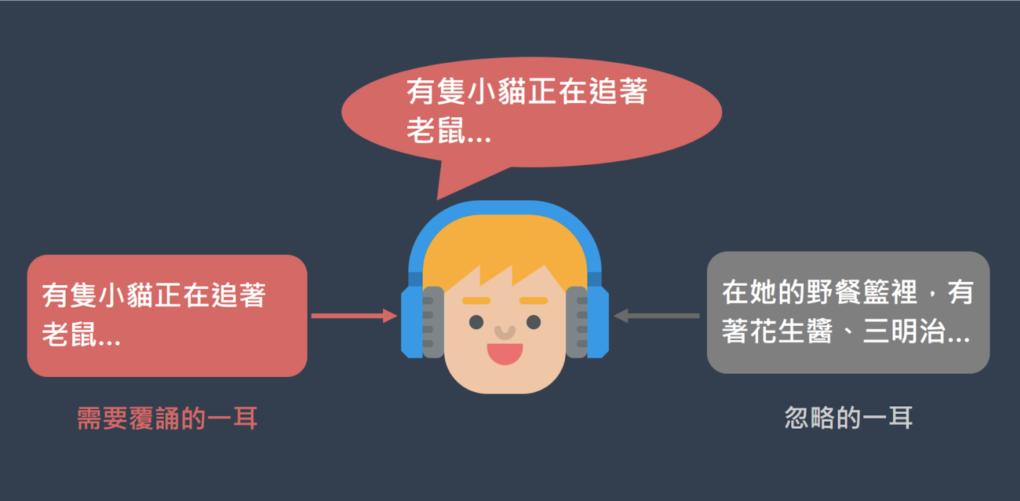
在跟讀實驗中,受試者會載上耳機,左耳及右耳會聽到完全不同的句子,且聽到的當下必須馬上複誦其中一耳所聽到的內容。例如當被要求複誦「右耳」所聽到的內容,而左耳聽到「在她的野餐籃裡,有著花生醬、三明治……」,右耳聽到「有隻小貓正在追著老鼠…」時,受試者就必須即時回答「有隻小貓正在追著老鼠……」。實驗結果發現[2],多數的受試者都能正確跟讀某一耳所聽到的語句,並忽略另一耳的訊息,顯示注意力(attention)似乎能選擇性地投入某個事物上。
是誰在呼喚我?刻在心底的名字
然而,當受試者正聚精會神地聆聽與複誦右耳的句子時,未受注意的左耳所聽到的內容,真的就如同耳邊風一樣,完全沒有進入大腦的處理歷程嗎?其實,有部分的訊息依然可以被我們的大腦所處理。
在剛剛所提到的實驗中,Cherry 指出受試者雖然很難回答出未受注意一耳的語句內容,卻能察覺到訊息在語音性質上的變化—像是從句子變成單音,或是從男性的聲音變成女性的聲音[2]。更特別的是,後續研究發現當未受注意的一耳出現自己的名字時,受試者也能即時察覺,並將注意力轉移到原本未受注意的一耳[3]。而這種聽到自己名字的現象不僅出現在成人,甚至在五個多月大的嬰兒身上就能觀察到[4]。
聽覺注意力的調節水閥,訊息被減弱但不消失
即使我們特別去注意某些訊息,並忽略環境中的其他刺激,仍然有部分訊息會被大腦所處理。不論是前面所提到的語音性質變化、或是自己的名字,雞尾酒會效應顯示了訊息的處理似乎不是依循全有或全無的原則(all-or-none law):接收應注意的訊息,並過濾或排除掉所有不需注意的訊息。
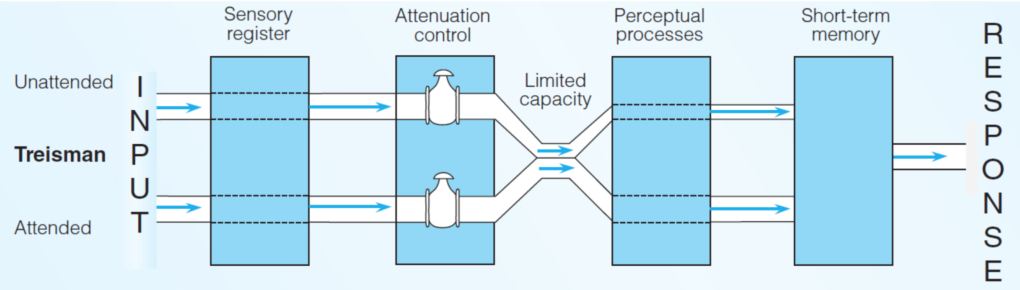
為了進一步解釋此現象,英國心理學家 Anne Treisman 提出了注意力的減弱模型(attenuation model)[5,6]—這個模型主張注意力系統分為四個階段:感官收錄(sensory register)、減弱控制(attenuation control)、知覺歷程(perceptual process)和短期記憶(short-term memory),其中最特別的就是「減弱控制」這個部分。
減弱控制就像是調節訊息的水閥,那些未受注意的訊息,由於和當下正在進行的任務無關(如跟讀作業),而轉為減弱的狀態存在於系統中。最後,被減弱的訊息會進入短期記憶,再依據各個訊息的閾值(threshold)高低而被受試者察覺。閾值可以想像成是個門檻,不同的訊息有不同的門檻,而門檻越低越容易被覺察。像是自己的名字由於閾值較低,因此我們很容易就能注意到;相反的,一些不常聽到的字詞,因為閾值較高而較難被察覺[6]。
用對方法,背景噪音不干擾
「對不起,你剛說什麼?」、「麻煩你說大聲一點」在日常生活中,是不是常常聽到這些話呢?當環境中充斥著各種噪音時,我們能不能主動採取一些策略,讓對方的聲音變得更清楚呢?假如你正打算參加一場派對、或是到一間人聲嘈雜的餐廳,以下三個方法將更有助於你把注意力焦點放在眼前的對話,而不被環境的噪音輕易打斷[1,7]:
- 留意目標聲音的特性
留意目標說話者一些明顯的聲音特性(像是阿霞有煙嗓,聲音低沉充滿磁性,講話慢慢的),能有效降低鄰近對話內容的干擾。
- 提升對話的音量
隨著對話音量的提升,環境中的其他聲音轉為背景音,使對話內容變得更為突出。
- 尋找聲音的來源處
不論是眼前的對話,或者是環境中的其他對話或雜音,若能清楚各個聲音的來源(如前後、左右或遠近位置),更有助於將注意力集中在目標來源上。就像坐在咖啡廳突然聽到情侶吵架聲,在定位他們的位置後,通常偷聽起來就會更輕鬆。
Google AI 新應用,讓機器模仿人類的雞尾酒會效應
在吵雜環境中,將注意力集中在特定的目標上,藉以分辨不同的聲音內容,是人類與生俱來的能力;然而,這件事情對於機器來說卻顯得格外的困難,原因在於當多人同時說話時,混雜的音訊會影響單一人聲的辨識效果。不過,隨著科技的進步,人工智慧技術(artificial intelligence,AI)的發展,現在機器也能辦到同樣的事情!
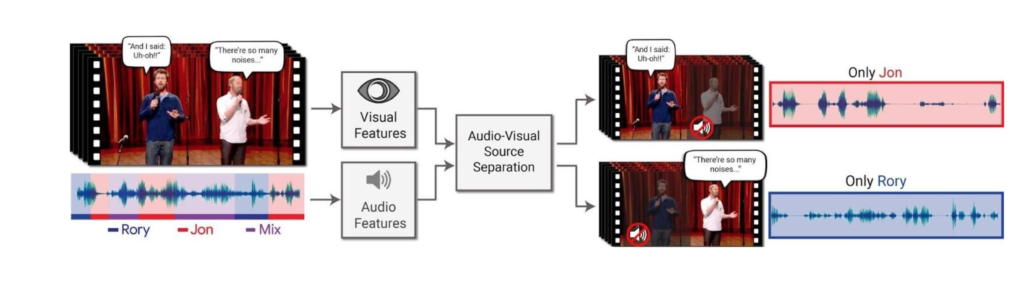
由 Google 研發團隊結合 AI 所打造的視聽語音分離模型 (audio-visual speech separation model)能夠有效地增強特定說話者的聲音,同時降低環境中其他人聲或雜音干擾[8]。這套系統獨特的地方,在於它能夠同時分析視覺特徵和語音訊息,判讀說話者的嘴型與聲音的變化,建立人與聲音之間的對應關係[9]。
這項技術的發展,未來也可望應用在許多領域上:像是在多人對話的影片中,提升自動化字幕生成的正確率。另一方面,也可以用來提升助聽輔具的表現,幫助聽損人士即使身處在吵雜環境中,依然能夠聽到清晰的人聲。
雞尾酒會效應揭開了注意力系統的奧妙,使我們能在吵雜環境中去關注重要的訊息。瞭解了越多相關的原理與應用後,不妨想想日常生活中還有哪些雞尾酒會效應吧!
參考資料
- Sternberg, R. J., Sternberg, K., & Mio, J. S. (2012). Cognitive Psychology. Wadsworth/Cengage Learning.
- Cherry, E. C. (1953). Some experiments on the recognition of speech, with one and with two ears. The Journal of the Acoustical Society of America, 25(5), 975–979.
- Moray, N. (1959). Attention in Dichotic Listening: Affective Cues and the Influence of Instructions. Quarterly Journal of Experimental Psychology, 11(1), 56–60.
- Newman R. S. (2005). The cocktail party effect in infants revisited: listening to one’s name in noise. Developmental Psychology, 41(2), 352–362.
- Treisman A. M. (1964). Monitoring and storage of irrelevant messages in selective attention. Journal of Verbal Learning and Verbal Behavior, 3(6), 449–459.
- Treisman A. M. (1969). Strategies and models of selective attention. Psychological Review, 76(3), 282–299.
- Brungart, D. S., & Simpson, B. D. (2007). Cocktail party listening in a dynamic multitalker environment. Perception and Psychophysics, 69(1), 79–91.
- Mosseri, I., & Lang, O. (2018, April 11). Looking to Listen: Audio-Visual Speech Separation. Google AI Blog.
- Ephrat, A., Mosseri, I., Lang, O., Dekel, T., Wilson, K., Hassidim, A., Freeman, W. T., & Rubinstein, M. (2018). Looking to listen at the cocktail party. ACM Transactions on Graphics, 37(4), 1–11.


































