


本文轉載自中央研究院研之有物,泛科學為宣傳推廣執行單位。
- 採訪編輯|郭雅欣、黃曉君;美術編輯|林洵安
「只要讓我看一眼,我就知道這是什麼!(You Only Look Once,YOLO)」YOLO,是目前當紅的 AI 物件偵測演算法。中研院資訊科學研究所所長廖弘源及博士後研究員王建堯,與俄羅斯學者博科夫斯基(Alexey Bochkovskiy)共同研發最新的 YOLO 第四版(簡稱為 YOLO v4),一舉成為當前全世界最快、最高精準度的物件偵測系統,引爆全球 AI 技術社群,已然改寫物件偵測演算法的發展。究竟,他們在演算法裡動了哪些手腳?又是什麼樣的契機,開啟了這項研究?
產業出難題,學界來解題
故事,是從一項產學合作開始。前幾年,科技部提出了「產學共創」機制:產業出題、學界解題,中研院合作對象義隆電子,出了一個考題給資訊所:如何增進十字路口的交通分析?也就是即時偵測車流量、車速等等。當時義隆電子已經在十字路口架設了監視器,包括全景攝影機及單一方向的槍型攝影機,接下來最需要的,就是辨識車輛的物件偵測技術。
「但我們需要的不只是辨識車輛而已。」王建堯說。在馬路上運行中的車速度很快,物件辨識必須非常即時,在短時間內就能辨識出車輛,並能持續追蹤,計算車速。換句話說,這個技術對物件的偵測必須「快、狠、準」。此外,因為影像資料不斷產生,如果把資料都上傳雲端運算,不但比較耗時,也會給雲端電腦帶來太大的負擔,因此這個偵測技術還得做到一件事──計算量必須夠小,小到可裝在十字路口監視器上的小型計算器, 即可完成物件偵測的任務。
要做到交通路況的即時分析,必須有一種速度快、仍能精準辨識,但又可應用在生活中小型計算器的物件偵測技術。
YOLOv4 演算法達到這個不可能的任務!它是目前世界最快、最精準的物件偵測演算法,卻又能小到放在十字路口的監視器內,已實際應用於如「智慧城市交通車流解決方案計畫」,即時偵測車輛、停等車列、車速等等 。
物件辨識的阿基里斯腱:梯度消失問題
怎麼辦到的?首先,王建堯著手研究著名物件偵測系統 YOLOv3 ,「我們想找出在建立一個物件偵測系統時,哪一個步驟是最關鍵的?如果改善了,效率和精確度會提升最多?」廖弘源強調:「雖然是工程問題,但我們要把科學思考帶進來。」
先來認識物件偵測技術!它是個卷積神經網路(Convolutional Neural Network,簡稱 CNN),具有許多網路層,每一層負責抽取某些圖像特徵。一個輸入的影像通過層層層層層層……分析,最後找出最可能的答案。理論上,層數越多、判斷結果應該越精確。
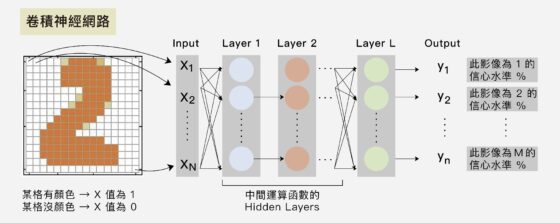
訓練這個卷積神經網路的方法是:先倒入大量已標記正確答案的學習材料(如標記好各種車輛的圖片),讓機器學習如何判斷。每次機器判斷結果與正確答案不符,就將這個資訊反饋到前面的網路層,調整每一層的參數,以期下次達到更準確的判斷。
那麼,哪一步改善後可以大幅提升表現呢?王建堯找到的關鍵是:學習的反饋過程。當卷積神經網路的網路層數愈多,在訓練階段,因為反饋計算方式,每回傳一層就會損失一些資訊,越前面的網路層學習到的東西越少,稱為「梯度消失問題」(vanishing gradient problem)。
為了解決梯度消失問題,前人曾經提出 ResNet、DenseNet 等等卷積神經網路,簡單來說,即是將後面資料備份後往前「跳級」傳遞!以 ResNet 為例,我們可以想像成「含水傳話」,從最後一個人往前傳,愈前面的人資訊愈缺失。但如果最後一層開始,每一層都備份錄音,再把錄音跳過一層直接往前傳,那麼前面的所有層都可接收到資訊,前面網路層就不會學不到東西。
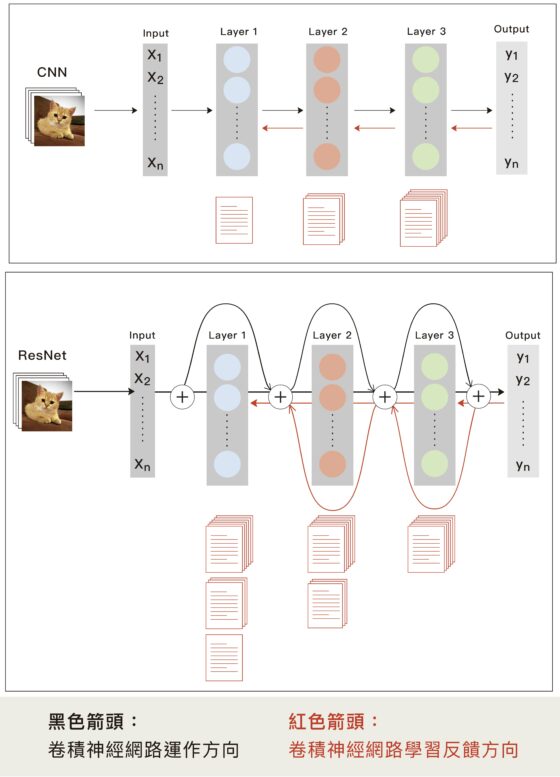
然而,ResNet 具有太多重複的拷貝,不但浪費計算量,而且不同層的參數用來學習重複、但多餘的資訊,換句話說,每一層能學到的東西都差不多。「是否有一種更好的方式,在不改參數量,讓機器運算變快,省下來的資源(參數)還能讓機器多學一點,提高精確度?」廖弘源說。
不只最快,還要最精準!
2019 年年初,廖弘源與王建堯團隊首先研發出局部殘差網路 PRNet(partial residual networks, PRNet),將資訊「分流」,減少無謂的計算量,使運算速度增加兩倍。「一開始做出 PRNet,我還是覺得效果不夠好。雖然減少計算量,大幅加快了計算的速度,但是正確率和原本相比並沒有什麼提升。」廖弘源自信的說:「我覺得這樣沒什麼意思,因為我們的目標,是做出全世界最好的物件偵測技術!」
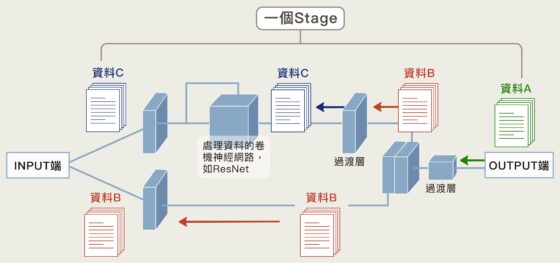
2019 年 11 月,他們在 PRNet 的基礎上,緊接著研發出跨階段局部網路 CSPNet(cross stage partial network, CSPNet),利用分割—分流—合併的路徑,成功達到了大幅減少計算量、卻能增加學習多元性的目標。
從 PRNet 與 CSPNet,我們一步步把物件偵測的計算量減低,但是學習卻能更多元,因此也得到更好的精確度。
「我們發表 CSPNet 之後,吸引 YOLO 技術的維護者博科夫斯基(Alexey Bochkovskiy)的注意。」廖弘源說。他們很快與博科夫斯基(Alexey Bochkovskiy)展開合作,將 CSPNet 用於開發新一代的 YOLO,並於今年 4 月發表了 YOLOv4,成為當前全世界最快、最準的物件偵測技術,引爆全球的 AI 社群。廖弘源笑說:「我們 4 月發表的論文,短短不到三個月,閱讀次數就超過了 1400 次,比我以往發表的任何論文都還多。」其中的關鍵技術正是 CSPNet。
此外,由於 YOLOv4 的技術是開放的,各式各樣的應用也如雨後春筍般快速出現。舉例來說,YOLOv4 可即時偵測人們的社交距離,或是快速判斷路上的行人有沒有戴口罩。
YOLOv4 甚至能辨識並捕捉滑雪運動中的人,廖弘源進一步解釋:「滑雪的人姿勢以及運動軌跡都不斷變換,甚至可能拋物線飛起,偵測難度相當高,但 YOLOv4 都能追蹤得非常精準。」
帶學生的第一要求:把科學帶進來!
中研院資訊所所長廖弘源長期研究多媒體視訊處理,從雞尾酒浮水印到人臉資料庫、數位化影片修補等,再到這次的 YOLOv4 物件偵測技術,研究成果卓越。而每一項成果的後面,都是廖弘源帶領資訊所前後屆學生一起努力的成果。
想在廖弘源的實驗室工作,可不是件輕鬆的事。他說:「做研究,不該只想著工程問題,應該本著科學家的精神,從中找出最具科學價值的關鍵下手。」許多學生一到廖弘源的實驗室,必須將過去狹隘、僵化的工程解題模式打掉重練,重新以科學看待問題。例如:本次 YOLOv4 的成功關鍵,即在於一開始問了個好問題,找到最值得改善的環節。
不論面對的是何種問題,我的第一個要求,就是把科學帶進來。
儘管治學甚嚴,個性海派的廖弘源和學生也有著亦師亦友的關係。他喜歡和學生一起找出好的研究議題後,一起埋首投入研究工作的熱血感,也喜歡在研究遭遇瓶頸時,與學生一起「大吃一頓解憂愁」。如今,他的學生遍布國際級知名公司與研究單位,持續發揮「廖式思考」的深刻影響力,開發更多如 YOLOv4 般頂尖的科研成果。
雖然團隊屢屢創造具商機的研究成果,但廖弘源對於獎項或是申請專利等,卻是看得很淡。「我的目的本來就不是賺錢,」廖弘源說:「我只希望我們對世界的好奇與探索,能真正轉化為對人類的貢獻。」

延伸閱讀
- 廖弘源的個人網頁
- 人工智慧再進化,開啟電腦新「視」界 !
- Enrich Variety of Layer-wise Learning Information by Gradient Combination
- CSPNet: A New Backbone that can Enhance Learning Capability of CNN. Chien-Yao Wang, Hong-Yuan Mark Liao, Yueh-Hua Wu, Ping-Yang Chen, Jun-Wei Hsieh,and I-Hau Yeh
- YOLOv4: Optimal Speed and Accuracy of Object Detection. Alexy Bochkovskiy, Chien-Yao Wang and Hong-Yuan Mark Liao
- 〈多媒體的繽紛世界〉,廖弘源撰。
- 〈我在中研院的第二個十年:多媒體研究與數位典藏〉演講
- 〈虛實世界的串聯者與守護者〉第二十三屆東元獎科技類,廖弘源受訪報導
本文轉載自中央研究院研之有物,原文為《一眼揪出你有沒有超速!世界第一物件偵測技術: YOLOv4》,泛科學為宣傳推廣執行單位

































