清代最常被偷的東西是什麼?——應用「歷史犯罪學」揭開竊盜謎團
本文轉載自中央研究院「研之有物」,為「中研院廣告」
自古流傳許多描述「偷竊」的成語,信手拈來就有偷雞摸狗、順手牽羊、樑上君子,這是否說明古代常發生竊盜案呢?細看清代司法類檔案,竊盜案數量的確居於首位,為何竊賊在當時如此猖獗?
中央研究院 111 年胡適院長科普講座邀請院內近代史研究所巫仁恕研究員,以「歷史學與犯罪學的相遇:19 世紀中葉竊盜犯罪的分析」為題開講,應用歷史犯罪學發掘清代竊盜案中令人意想不到的現象!
傳奇俠盜「一枝梅」
 圖/研之有物
圖/研之有物翻開明末小說《二刻拍案驚奇》,傳奇俠盜「一枝梅」瞬間抓住眾人目光,只見他出入如鬼神、來去如風雨,不一會功夫便偷來士大夫家的金銀珠寶、竊走公子哥兒的西洋異錦被,甚至戲弄地偷換道士的百柱帽。每次行竊得手後,即在牆上畫一枝梅花,並將錢財送給貧民,「人間第一偷」稱號可說當之無愧!
 俠盜一枝梅,每次行竊得手後,即在牆上畫一枝梅花,並將錢財送給貧民,享有「人間第一偷」稱號!圖/明人凌濛初《二刻拍案驚奇》刊本插圖
俠盜一枝梅,每次行竊得手後,即在牆上畫一枝梅花,並將錢財送給貧民,享有「人間第一偷」稱號!圖/明人凌濛初《二刻拍案驚奇》刊本插圖竊盜案是明清時期常見的犯罪類型,可惜並非每位竊賊都是如同一枝梅的義賊。為何人們會淪為竊賊?哪類東西與對象最常被偷?清朝官府又是如何辦案?
面對重重疑雲,中研院近代史研究所巫仁恕研究員決心讓歷史學與犯罪學相遇,逐步揭開 19 世紀中葉竊盜犯罪的神秘面紗!
重返竊盜現場
巫仁恕以清代《巴縣檔案》(今四川省重慶市一帶)為研究材料,分析當中的司法類檔案後發現,從乾隆至宣統年間,最常見的犯罪類型就是竊盜案,尤其 19 世紀中葉同治朝的年平均數量最多,13 年間累積 3 千多起竊盜案。
當中最常見的竊盜方式是「入室行竊」,狡猾的竊賊會趁四下無人時鑿穿牆壁,鑽入屋內行竊。其他還有類似現代金光黨的「迷竊」,犯人會用迷煙或迷藥將人迷昏後大肆洗劫。小說中飛簷走壁的「飛竊」並不常見,但偶爾也會發生。
 鑿壁入室行竊是常見的竊盜方式。圖/〈張夫人智驅偷兒(附圖)〉,《輿論時事報圖畫》,1910 年第 2 卷第 29 期,頁 2。
鑿壁入室行竊是常見的竊盜方式。圖/〈張夫人智驅偷兒(附圖)〉,《輿論時事報圖畫》,1910 年第 2 卷第 29 期,頁 2。那麼竊賊最常偷的東西又是什麼呢?從《巴縣檔案》記載的失單可窺知竊賊最常下手的目標,也連帶顯示清代百姓生活中的物質消費與品味。
失物排行榜第一名竟不是金銀珠寶,而是人們穿戴的帽子、馬褂、布鞋等,甚至有流行服飾與西洋衣料,因重量輕、有市場、好銷贓,成為竊賊的首選,其次才是金屬器皿。此外,像是硯台、高級墨、書畫等象徵身分品味的文化用品與藝術品也時有所見。
 《巴縣檔案》記載的失單,遭竊的物品多為服飾類、日用品(如綠框內的油紙傘),當中不乏進口洋貨(如紅框內的西洋衣料),凸顯時人生活品味。圖/清代巴縣檔案
《巴縣檔案》記載的失單,遭竊的物品多為服飾類、日用品(如綠框內的油紙傘),當中不乏進口洋貨(如紅框內的西洋衣料),凸顯時人生活品味。圖/清代巴縣檔案最常被竊賊光顧的也不是家財萬貫的富翁,反而是資產百兩以上卻不足千兩的中產之家。這類人家有時不會去報官,因為大部分只損失一、二兩價值的物品,打官司要花的交通與時間成本比失物的成本還高。
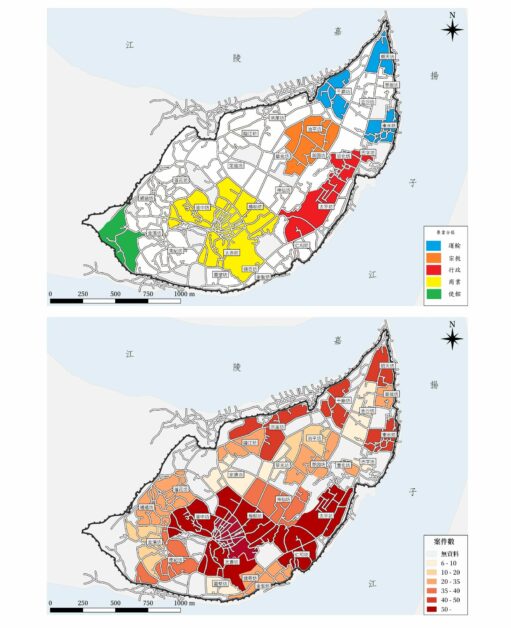
竊賊最常出沒的地點與時機,其實和現代社會頗為類似。疊合清代重慶城市分區功能圖、同治朝巴縣城內各坊竊盜案分布圖後發現,竊盜案多集中在商業和行政中心,行竊的熱門期間常在考試、市場趕集或舉行婚禮節慶時。
竊賊東西到手後最常去當舖、市場銷贓,或賣給收購贓物的小販。特別的是當時有所謂的「窩賊之家」,藉由開設客棧掩人耳目,實為慣竊的幕後黑手與藏匿竊犯的賊窟。
 疊合清代重慶城市分區功能圖(上)、同治朝巴縣城內各坊竊盜案分布圖(下)後發現,竊盜案多集中在商業和行政中心。圖/巫仁恕提供,參考清代巴縣檔案繪製
疊合清代重慶城市分區功能圖(上)、同治朝巴縣城內各坊竊盜案分布圖(下)後發現,竊盜案多集中在商業和行政中心。圖/巫仁恕提供,參考清代巴縣檔案繪製被大環境所逼而犯罪
一般認知的犯罪者多是不務正業或受貧窮所苦的社會邊緣份子,巫仁恕應用犯罪學理論分析《巴縣檔案》中犯人的口供,從不同視角層層剖析犯罪動機。他發現竊嫌中,有一群被稱為「下力活生」的低階勞動階層佔了多數,他們沒有加入同業公會,靠著四處打零工謀生,生活較不穩定。
從理性抉擇論分析,如果這名有犯罪傾向的偷竊者認為,行竊可以讓生活過得更好,就可能選擇鋌而走險,這解釋了為何貧窮者容易傾向偷竊。再者,從社會聚合論來看,很多竊盜案都是集體犯罪,因為人多勢眾好照應的心態強化了犯罪合理性。
然而,巫仁恕又發現,有相當數量的竊賊是有正當工作的,當中不乏工商業主、受雇服務業者,甚至是公務人員或基層精英。上述案例顯示,貧窮不一定是引發偷竊的原因,當中還藏有其他因素。
從日常生活理論來看,只要集結三種要素即可能誘發竊案:有犯罪傾向的偷竊者、有價值的標的物、監督者不在場。此外,從情境預防理論分析,某些偷竊者是在日常情境下擋不住眼前誘惑,突然萌生行竊慾望,例如缺錢的兒子偷爸爸的錢、耕田時偷拔鄰居家的菜,或員工趁老闆不在時偷拿錢財。
 笨賊竊耕牛,笨賊見牛隻無人看守,遂順手牽「牛」,卻因牛隻特徵太明顯,被人當場識破。圖/〈笨賊竊耕牛(附圖)〉,《輿論時事報圖畫》,1910 年五月初三,頁 1。
笨賊竊耕牛,笨賊見牛隻無人看守,遂順手牽「牛」,卻因牛隻特徵太明顯,被人當場識破。圖/〈笨賊竊耕牛(附圖)〉,《輿論時事報圖畫》,1910 年五月初三,頁 1。事實上,多數人淪為竊賊是被大環境所逼,同治初期的巴縣即發生多起社會動亂,嚴重影響民生經濟,導致治安敗壞。
例如 1850 年爆發的太平天國之亂造成多個省份死傷慘重,同治年間太平軍的殘餘勢力入侵四川,大批巴縣團練(地方民兵)前往隘口守衛家園,許多宵小常趁團練隊員不在家時闖空門。
同治二年則發生重慶反天主教案,一群暴民闖入教區燒殺虜掠,趁亂偷走許多物品。接著,同治三年巴縣一夕間米價徒漲,百姓一時難以負荷,生活陷入困境下不得不偷竊苟活。
嚴厲清律下的破案率
竊盜案如此猖獗,清廷又是怎麼懲治罪犯呢?巫仁恕以「犯罪學嚇阻理論」(deterrence theory)三要素:嚴厲性(seriousness)、迅速性(swiftness)、確定性(certainty)來評估清政府的犯罪防治效果。
細看當時的大清律例具備相當的嚴厲性!母法「律」會根據犯罪主從關係、初犯或累犯、贓物價值高低處以相對的刑責。例如偷 1 兩以下,罰杖刑六十大板;偷 50 兩以上,除杖刑伺候外,還要服勞役徒刑一年;如偷 100 兩以上,杖一百大板、外加發配邊疆兩千里;偷 120 兩以上最重會被判處絞刑。
至於子法「例」則會針對不同狀況做出懲戒,例如偷竊過程中揮刀殺人、暴力行為、特殊身分犯罪,或在皇室、官家等特殊場所犯罪都會加重刑責。其他會一併懲處的還包括:窩藏罪犯者、收人贓物者、官役失職沒抓到犯人等都有相關罰責。
雖然清廷看似有嚴厲的律例懲治竊賊,但一般百姓如果家中遭竊,並不會馬上報官,反而是先通報住家附近的團練或保甲長,由這些地方基層組織的負責人私下調解紛爭。如果調解不成才有可能走上報官一途。
究竟官府如何辦案呢?首先,報官者需稟狀並列出遭竊的物品與其價值清單,由書役調查後撰寫勘單(調查報告)。確定真為竊案後,知縣會下公文給差票,派捕役去逮捕嫌犯。接著撰寫比單(傳喚公文)傳喚受害者等一干證人升堂審訊。最終,竊賊罪證確鑿、抓到共犯後,還需撰寫供狀(口供)與畫押(結狀)。
 清代官府辦案程序。圖/研之有物
清代官府辦案程序。圖/研之有物經過長時間辦案後,最終的破案率又是如何呢?以同治年間巴縣的破案率為例,1064 件都市竊盜案中,捉到竊犯的有 204 件,破案率僅 19%;1917 件鄉村竊盜案中,捉到竊犯的有 629 件,破案率僅 33%。整體的平均破案率只有 28%。
整體來看,官府的破案率低、辦案程序冗長,又常因抓不到共犯而無法結案,空有嚴厲性但迅速性與確定性不足,無怪乎百姓不想報官,也難以起到嚇阻犯罪的作用。
用微觀的視角探索社會百態
這種結合歷史學與犯罪學的跨領域研究稱為「歷史犯罪學」(historical criminology),是新興的研究領域。
巫仁恕表示,歷史學家常聚焦研究戰爭、革命、叛亂等歷史大事件的發展始末,較少關注日常性的犯罪事件,原因之一在於史料的局限。
過去有關竊盜的史料常零星散見於筆記小說、公案小說、判牘檔案等文獻之中,無法全面看清竊盜案件的具體實態。
所幸近 20 年來,中國許多州縣檔案重見天日,當中的司法類檔案記載許多竊盜案,結合犯罪學一起分析後,能從更微觀的角度了解古人的犯罪動機、犯罪心理、犯罪防治等,進而看見不一樣的歷史面貌!
延伸閱讀
- 巫仁恕研究員個人網頁
- 巫仁恕、吳景傑(2021)。犯罪與城市―清代同治朝重慶城市竊盜案件的分析。臺大歷史學報第 67 期,頁 7-53。
- 111 年中研院知識饗宴—胡適院長科普講座「歷史學與犯罪學的相遇:19 世紀中葉竊盜犯罪的分析」