


「天下沒有兩句話的聲音數據是一樣的!」人類語言的聲音數據千變萬化,同一個人說同一句話兩次,其數據絕對差很多;這是發展語音技術的最主要困難點。
好在人類語言有結構,因此語音技術必須透視聲音的結構。本文整理中研院李琳山院士在講座中的演講精華,一同了解華語語音技術的前世、今生並展望來生。

中央研究院李琳山院士演講的這一天,已經是臺北連續第五天微雨。前往會場的路上,你可能會問 Siri 明天天氣如何,並於一秒後聽到她回覆:「陰天,22 度」,還附上參考網址。究竟機器是如何聽懂人話的?
「語音技術,即是藉由機器處理語音訊號的數據。」李琳山開場時表示,人的語言的聲音是聲波,用麥克風收下來變成訊號後成為時間函數,再把任一小段「聲波波形」轉變成「實數序列」,也就是數據,再進行分析處理。
語音技術的最主要困難點,在於「聲波波形」的千變萬化。
例如,李琳山展示某一個人說一句話「到不到臺灣大學」的聲波,發現句中兩個「到」字聲波長得完全不一樣、音高也很不同,「天下沒有兩句話是一樣的!」
此外,我們熟知的是華語中有很多同音字,如說到「今」、「天」時,為什麼不會認為前者是黃金的「金」?李琳山解釋,聲音的訊號是有結構的,人腦中有類似辭典及文法、還有遠遠更為複雜的知識,我們會根據這些知識及前後文判斷出正確文字。因此,語音技術必須透視聲音的結構。
要讓電腦像人一樣,學會「聽」和「說」人類語言有多難?得從華語語音技術的前世說起。
語音技術前世:口齒不清牙牙學語的機器
1980 年,李琳山剛取得博士學位不久,回到臺灣。當時製作一份中文文件,得使用嵌有幾千個鉛字的大鍵盤中文打字機,臺北街頭還有不少打字行在徵求打字員。當時很多人思考:中文字輸入機器真的這麼困難嗎?並提出了許多解決方案,例如字根法、注音符號法等。李琳山則想著是否可以用「聲音」輸入中文。但是,以當時技術及臺灣的研究環境而言,他說:「太難了」。

李琳山百思不得其解:人說話不就是把這些音拼起來嗎?為什麼機器拼的聽起來不知所云?直到 1983 年,聽到一位語言學家的專業建議,李琳山開始尋找華語語句中每個字發音的「調整抑揚頓挫的一般性規則」。
華語語句中每個字只要前後字不同,就會有不同的抑揚頓挫,也就是音高、音量、音長和停頓的變化。
看來,唯一辦法是從數據中找答案。李琳山決定土法煉鋼,造出一堆句子並錄音,透過人工手動分析,確實慢慢發現若干一般性規則。

李琳山分析上圖這句話的文法結構,發現各個字之間有各種不同的文法結構邊界,原來前述三聲變化規則可以橫跨某些邊界,但不能橫跨其他邊界。如此一來就有答案了。把全部規則兜起來以後,再讓電腦用單音拼成一句話,並照規則調整每個字的抑揚頓挫,此時電腦雖然有點口齒不清,但大致能聽得懂電腦在說什麼了。
1984 年,短短一年後,口齒不清的電腦成為全球首台能說出華語的機器。李琳山给它一個很直白的名稱:「電腦說國語」,此套系統只要輸入文字或注音,就可以輸出聲音。由於聲音還是不太入耳,李琳山的研究團隊三年後改良出更好的系統,甚至能表演相聲,展現豐富的抑揚頓挫,例如下面音檔示範:
「電腦說語音」技術研發故事(演講現場播放)
李琳山之後開始想訓練機器聽華語。他提出三個基本假設,試圖讓華語語音辨識(Speech recognition)的問題變得比較可以解決。
首先,一次只輸入一個音就好,也就是一字一字「斷開」輸入,藉此避免連續語句中不同的前後字影響,造成不同的聲音訊號變化的問題。第二,每一位使用者自己說話訓練機器聽他的聲音,也就是要避免不同說話者的「音質」、「口音」等等差異。第三,辨識過程中一定會出現錯誤,讓人工操作軟體來更正就是了。這三個假設讓問題比較有機會解決。
機器操作時,需要當年看來極為龐大的運算能力,也需要複雜的硬體電路支援,然而因為當時軟體的計算能力太弱了,而不同的硬體電路拼湊困難始終不成功,後來李琳山決定傾盡研究室的財力,自國外購買平行運算電腦(transputer),終於在 1992 年完成第一部語音辨識系統,命名為「金聲一號 」(Golden Mandarin I)。這是全球首見的華語語音輸入系統,但一次只能輸入一個字,且那一個字需要好幾秒才看到辨識結果。之後不斷修改翻新,三年後的金聲三號(Golden Mandarin III) 終於不需要斷開文字,可以直接用連續語音輸入中文字。
李琳山說:「以前最大的問題是,華語中每個音的訊號的波形,長相都會因為前後字不同而改變。到金聲三號時我們已經讓機器自行由數據中,學出這些變化來解決這個問題。以現代名稱來說,就是古代的機器學習(machine learning) 。」李琳山說,以今天科技進步的速度來看,1990 年代稱為「古代」應屬合理。
今生:語音辨識加上雲端巨量資料庫
隨著機器學習等技術的進步,今天各種語音個人助理如 Siri 等等,聲控與回應能力也越來越強 。李琳山說明,其實 Siri 並沒有太多特別了不起的技術。
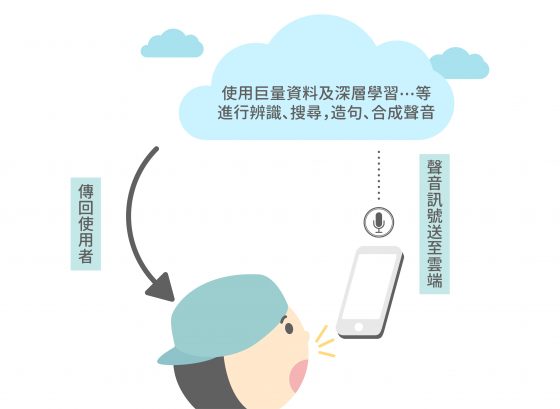
如上圖,開發者把龐大的機器及計算資源、數據模型等設置在雲端,使用者對智慧型手機說話後,聲音訊號被送至「雲端」。雲端的龐大機器分析巨量資料、透過深層學習(Deep Learning,或譯深度學習)得到的技術來進行聲音辨識、資料搜尋,造句並合成聲音等,再傳回使用者。
如果除去雲端架構、巨量資料、深層學習等今日尖端技術及龐大的運算資源,Siri 剩下的華語語音辨識核心技術和 1995 年李琳山團隊的金聲三號差別並不大。
提及「華語語音」辨識技術與「西方語音」辨識技術的差異,李琳山說明,華語是方塊字非拼音語言,由字構詞,由詞造句。詞的定義和在整句文句中詞的邊界也不明確。我們時常自動把很多小詞串起來變成長詞,又可以把長詞縮短變成短詞等等,也隨時自動產生很多新詞。
為了辨識語音、理解語意,機器自然需要詞典資料庫。然而開發者遇到的第一個問題可能是──該放多少詞?哪些詞?因為華語的詞幾乎是無限多的。
再者,華語一字一音,音的總數有限,但字總數很多,故同音字多,不同聲調和不同音的組合,產生出千變萬化的詞和句。例如,二人都說喜歡「城市」,乍聽並不易判斷他們到底是喜歡「城市」或「程式」。
華語中只有少數有限的「音」,每個「音」可代表很多同音字,這些字可拼成千千萬萬的詞和句。
華語的「音」帶有極豐富的語言訊息,這種「音」的層次的語言單位是西方語言所沒有的。
李琳山認為,透過巨量資料及深層學習,有機會讓巨量資料涵蓋人類語言中的各種現象,也有可能讓機器找到人類尚未考慮到的答案。也就是說當機器非常強大、數據多到可以涵蓋所有語言現象時,機器「有可能」自動學習到所有這些現象。不過目前還沒有發生。
下階段目標:「語音版」google,用聲音搜尋資訊
談及下一階段語音技術發展的可能方向,李琳山認為自己一直是追尋「遙遠大夢」的人,投入的研究方向常常在短期內看不出有實質回收的機會,例如:他今日非常有興趣的領域之一是語音搜尋,這就是語音版的 Google 。
網路多媒體湧現,如 YouTube 或線上課程,多數影片內容常有非常豐富的「聲音」,但其中的文字必須由人輸入,而且文字量常常比聲音少。
但現有透過 Google 去搜尋 YouTube 或影音平台的功能,僅止於搜尋那些人為輸入、數量較少的「文字」,例如影片描述、字幕等等,卻不是影音本身的「聲音」。
李琳山說:「 Google 看盡天下文章後能幫人找出任何一篇文章。機器聽聲音正如看文章,應該也可以聽盡天下聲音後,找到其中任何一句話。」例如,如果有人想找有關「深層學習」的演說,機器聽到指令搜尋後,應能跟他說某部影片的某句話提到「深層學習」。
李琳山的團隊曾蒐集 110 小時、6000 則的公視新聞製作雛型系統,只要對機器說出「王建民讀的國小」,機器便會自動抓出含有「王建民」與「國小」兩個關鍵詞的新聞片段。
再以網路課程為例,李琳山的研究團隊曾開發「臺大虛擬教師」,把課程錄音以投影片為單位,將聲音切成小段,變成一張張有聲投影片。再從每張投影片中抽出「關鍵詞」建成關鍵詞圖,分析詞關鍵詞之間的關係。如此一來,機器不僅可以找出討論相關主題的課程段落,讓使用者知道所找到的投影片的大致內容,並可以建議學習的前後順序,也能自動摘要出其中的語音資訊。
李琳山現場展示「台大虛擬教師」的操作。例如,有一個學生聽演講時聽到類似 “Black word algorithm” (黑字演算法)的字眼,就上網查相關課程,發現果然有好幾張投影片都說到這個詞。不過一聽就發現,所找到的投影片真正說的是 “Backward algorithm” (反向演算法),那才是那個學生聽到的。李琳山說:「這可以證明我們搜尋的是聲音,而不是文字。」
來生:融會貫通多媒體數位內容,量身打造課程資訊
談起語音技術的未來,李琳山認為,未來機器有機會替人類把網路資訊去蕪存菁、融會貫通。例如 2015 年 YouTube 的尖峰時段每分鐘有 300 小時影片上傳 ,2016 年 Coursera 線上課程有將近 2000 門課。沒人有能力看完或聽完所有這些數位內容,人類的文明精華因而埋在大量不相干的資料堆中。但是機器可以看完、聽完它們。

李琳山舉例:機器有可能聽完全部內容並融會貫通,再為每個人抽出他所需要的部分,由機器量身訂製課程。例如一名工程師被派到奧地利出差,他跟機器說:「我想學莫札特作品的知識,但我是個工程師,沒有背景知識,願意花三小時來學。」李琳山認為技術上,機器有機會做得出這種「客製化課程」。
李琳山以「遙遠大夢」比喻語音技術的研究。
回顧華語語音技術三十幾年的發展,電腦機器已經從「牙牙學語」進展到「對答如流」,卻還有許多需著力之處。李琳山說「芝麻開門」是人類的千古大夢,希望開口說話就可以打開寶藏的大門。以今日眼光來看,網路是全人類的知識寶藏,未來隨口說句話便可以開啟寶藏大門是有機會的。他說:「大夢雖遙遠,有一天有人會實現它。」
延伸閱讀:
本著作由研之有物製作,原文為〈Google 可能會有語音版嗎?會長怎樣?「電腦聽說人類語言」技術的前世今生〉以創用CC 姓名標示–非商業性–禁止改作 4.0 國際 授權條款釋出。
本文轉載自中央研究院研之有物,泛科學為宣傳推廣執行單位








































{kind=link}