


中研院人工智慧系列活動
當有些人喊著 AI 會殺人,有些人搶先用 AI 來做聰明的事,甚至是救人一命!本文取自中央研究院「機器學習月」與「人工智慧跨域領袖營」活動內容,聊聊各領域最新的 AI 發展與應用。
用 AI 救人:觀察細微脈博
「余憶童稚時,能張目對日,明察秋毫。見藐小微物,必細察其紋理,故時有物外之趣。」若你曾在國文課本讀到這段,可曾驚嘆沈復的好眼力?
現在你可以拍拍沈復的肩膀說「以 AI 細視,汝更覺呀然驚恐」。因為人工智慧的影像處理技術宛如一副神奇眼鏡,能看到肉眼察覺不到的細微變化,例如:當血液隨脈博通過臉部,造成的膚色變化。

這個影像放大技術反之,也能藉由偵測臉部皮膚顏色變化的頻率,回推心跳速率。對於新手爸媽而言,常見的焦慮是「總想確認寶寶還在呼吸嗎」,因為嬰兒熟睡時一吸一吐的胸部起伏相當細微,從外觀難以分辨。
發展這個影像放大技術的團隊,發現也能從嬰兒睡覺的影像推估心跳速率,數值準確度可與醫療監測器相比,有機會應用於家庭日常的呼吸監測,預防嬰兒猝死症 (SIDS)。
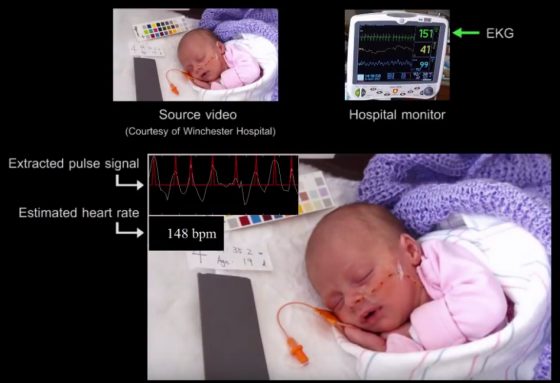
大眾看新聞時,經常好奇螢幕中人說話是否屬實,例如當立委說出「一生監督你一人」時,政府官員是否有動情。表情可以透過臉部肌肉控制,而脈搏跳動加快、引起血液流經臉部的膚色變化,透過這個訊號放大技術解析,就藏不住心跳了。
用 AI 聚集靈感:社會物理學
俗話說:「三個臭皮匠,勝過一個諸葛亮」,但如果臭皮匠高達成千上萬名呢?
透過社群網絡,串起成千上萬名臭皮匠互相交流資訊、溝通意念,並透過資料科學依此預測未來的行為、找出問題的對策,可說是「社會物理學 (Social Physics) 」的奧義。而提倡社會物理學這門新科學之人,是被《富比世》雜誌譽為「全球 7 大權威資料科學家之一」的 Alex “Sandy” Pentland 教授。

儘管 YouTube 出身的 HowHow 堪稱「邊緣人中的霸主」,而生活中也有許多人在群體中感到孤立,但 Alex “Sandy” Pentland 教授指出,無論在虛擬社群和真實社會中,沒有人是獨立切割的。
每個人都是社會的一部分,共享資料、共享資訊,這時意念彷彿化為一條時間長河、流動著,每個人涉身其中,從彼此的經驗想法中學習,最終成就我們自己的習慣和興趣。
而這些可共享、可分析的資料從何而來?就在人們身邊各處──包含通話紀錄、信用卡交易、 GPS 定位紀錄等等,像是糖果屋童話中撒下的「數位麵包屑」,表達著你的生活行蹤與選擇偏好,而差別是不會被森林裡的動物吃掉。
數位麵包屑與臉書(Facebook)貼文大不相同,臉書貼文是人們選擇性過濾、編輯的資訊。比起人們自己說自己做了什麼,日常的數位麵包屑反而更能反映個人真實情況。
年齡、性別沒辦法精準表達你是誰,更重要的是你去了哪裡、做了什麼。
Steve Jobs 曾說:「所謂的創造力,只是將事物聯繫起來」,而社會物理學基於貝氏網路 (Bayesian network)發展,透過數位麵包屑將不同情況聯繫起來,找出「情況 A 」和「相關情況」之間的機率關係。

Alex “Sandy” Pentland 教授再舉例,若在地圖看到 GPS 人流移動到了城郊某一地帶就停止,傳達的資訊是:當大多數人停止前往該區,代表該區容易有犯罪活動。並另以北京的資料指出,若當地的交通網絡完善、社群流動越密集,未來三年該區的經濟成長機率也偏高。這些社群行動觀察,有助於城市規劃與犯罪防治,而且運用的資料無須涉及記名資訊。
社群範圍也能縮小到公司。 Alex “Sandy” Pentland 團隊與美國銀行(Bank of America)的電話客服中心合作,實驗若客服員之間有越多的想法交流,是否能降低每通客服電話的處理時間。分析結果發現,比起客服員逐一單獨休息,讓整個客服團隊一起休息更好,因為有助增進團隊間的交談、交流工作竅門,讓處理客服電話的平均時間大幅降低。
從工人智慧到人工智慧,期待又怕受傷害

適合發展 AI 的是「有特定知識」、「行為可預測」的領域,並且應善用「原本就有的資料」,例如臺灣累積豐富的醫學影像,這些影像透過機器學習就能轉換為知識,而非從頭開發網站,去蒐集新的使用者資料。
在 Google 有幾萬名工程師在進行幾千項專案,各種領域都有人嘗試,甚至包含用影像辨識判斷正在飛行是不是母蚊,是的話就擊殺,藉此來斷絕蚊子成為疾病傳染源。簡立峰分享, Google 若進行 5000 項 AI 專案,最後證實有用的不到 10 項,實作後會發現論文演算法講得頭頭是道,但實作後好像不是這回事,許多參數調不出來。
然而,這些過程不是白費。 Google 從這些專案裡的工程師選出 50 位較富經驗者、組成顧問團,再引導大家嘗試各種 AI 專案,而前提是要建立開源文化,開放讓所有員工自由修改程式碼,應用在自己的專案中。
臺灣的組織化領導,讓軟體高手沒有發揮空間,就算有神字輩也只是當兵用。
許多人會好奇,為什麼 Google 軟體開發這麼厲害?簡立峰提到,臺灣生產「硬體」的組織結構,是將軍關在辦公室,帶領生產線的幾千名士兵,一起完成最後的產品。「軟體」的思維要倒過來,Google 採取「有將軍沒有兵」的模式,人人都是將軍,讓神人站上第一線寫程式,自己 debug 解決問題。
「 AI 是當紅的產業趨勢,但我的小孩不是讀這個領域的怎麼辦?」在演講中,一位中年父親提出許多家長會有的疑問。
「通常華人的傳統,生了兩個小孩,一個會讓他出去外面的世界闖,一個會留下來照顧老家……」簡立峰從社會文化與人之常情,比喻臺灣整體產業發展。
在 AI 時代,科學可以突破百分之八九十,但最後一哩路比想像中難度更高。哪裡熱門、大家都趨之若鶩,即使可能史上最大的失敗就在眼前。這是出去闖的孩子會面對的問題。簡立峰提到,臺灣可以參考以色列的產業策略,弱水三千只取一瓢飲,著重發展大市場需要的尖端技術,例如臺灣的鏡頭技術世界知名,就有更多優勢延伸發展電腦視覺領域。
而若不在 AI 領域,留下來的孩子,則應跟臺灣土地有所連結,發展他國取代不了、有信賴感的產業:例如醫療、食品、農業,讓在外面闖的孩子無論什麼時候回家,都能感受到在地文化、安心踏實。
學界與產業離很遠?創造一個機會齊動腦!
2017 年政府宣示「臺灣 AI 元年」即刻開始,但要落實到業界尚有層層挑戰。為此,科技部與中研院舉辦五天四夜的密集研習,向國內外講師借智慧、聚集學員間的意念流,來討論各產業要懂哪些 AI 先備知識、遇到的問題如何解決。

以臺灣醫療產業而言,優勢是已累積豐富的影像診斷資料,若在保護病人隱私的前提下開放資料,就有機會透過電腦視覺協助醫師診斷病情,或是監測嬰兒老人的睡眠呼吸中止情況。甚至在診間,當病人聽完診斷滿臉問號,這時一旁的鏡頭偵測到病人表情,就能提醒醫生要再多加說明、增進醫病關係。
製造業的學員則回饋,若企業自己架設機房、自己租用雲端伺服器,這種燒錢行為會降低轉型意願,希望政府能提供雲端運算資源的協助,例如國家實驗研究院高速網路與計算中心(國網中心)的 GPU 伺服器。
「在華爾街大量招募資料科學家的趨勢下,臺灣的 FinTech(金融科技)仍受限法規,綁手綁腳無法前進!」來自金融界的學員表示。希望能透過調整金融法規、個資法規,讓去識別化的財務資料成為可應用數據,藉以分析客戶的潛在風險、或預測未來交易。或者,開戶時結合電腦視覺技術,透過影像辨識開戶者是否有異常的心跳表現、說謊的可能性,及早阻止不當的金融交易。
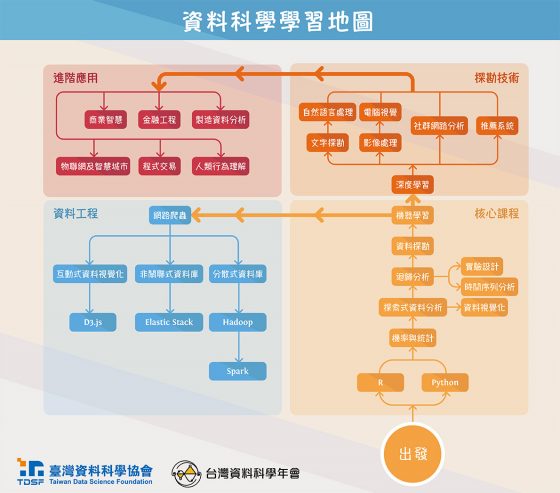
最後,無論是想出去或留下來的孩子,以及學界產業界的人士,若有興趣進一步了解 AI 領域中各技術有何不同,下圖的「資料科學學習地圖」將能作為指引。
儘管 AI 之路讓人既期待又怕受傷害,但如同電影《三個傻瓜》所言:「請把手放在心上說『一切都好』,我們的心太容易害怕,你得哄騙它。不管天大問題,告訴你的心『一切都好』,那會讓你有勇氣去面對問題。」
參考資料
本著作由研之有物製作,以創用CC 姓名標示–非商業性–禁止改作 4.0 國際 授權條款釋出。
本文轉載自中央研究院研之有物,泛科學為宣傳推廣執行單位






































