




文 / Louis|畢業於台大土木所交通組,高考交通技術及格,交通工程技師及格

在《塞車:看不見的時間小偷》一文中,我們已經討論過交通壅塞的基本觀念,本文將用實際數據來描繪交通壅塞的情形。另外,在交通管理的工作中,會使用一些圖形工具來觀察時間、空間以及交通量之間的關係,這些工具相當直覺易懂,也將於本文中一併介紹。
那我們就開始囉!
所以說那個「交通車流數據」呢?

自 2014 年起高速公路改採計程電子收費,除使車流更順暢外,其附加價值是產生大量的交通資料,供政府單位交通管理、學術單位研究或是民間介接使用。有關高速公路局交通資料蒐集支援系統(Traffic Data Collection System,TDCS)所提供之交通資料,可至交通資料庫或是政府資料開放平臺免費下載使用。

順帶一提,為能妥適應用由 ETC 所蒐集的交通資料,高速公路局透過創意競賽的手段並結合民間共同參與,以期激盪出 ETC 資料在交通管理之創意發想與應用。目前該競賽正舉辦第三屆,主題為「資料視覺化應用」,歡迎對交通科學或是資料科學有興趣的讀者朋友可以嘗試挑戰。
目前所有縱向高速公路佈設的 ETC 偵測站超過 300 座,且高速公路車輛使用 ETC 的比率達 92%,所蒐集之交通資料相當綿密,並有很好的品質,相當適合用來進行資料探勘。而本文所有數據、圖形也皆是以ETC交通資料分析繪製。
塞車,總是在不斷地重現歷史?
由於高速公路肩負中長程運輸的重要任務,根據經驗,整體而言高速公路最壅塞的時間會發生在連續假期第一天的南下方向。圖一是以今年 228 連續假期第 1 日(106 年 2 月 25日)國道 1 號南下方向的資料繪製,橫軸編號代表國道 1 號由北至南各路段,縱軸代表的是時間(0-24時),而每一個格子的顏色深淺,代表該路段-時段的平均速率,顏色越深代表速率越低,這張圖我們稱之為「時空圖」。
我們在此將高速公路交通壅塞的發生,定義為速率低於每小時 40 公里以下且持續超過 2 個小時以上的路段。藉由圖一的觀察,106 年 2 月 25 日首先發生壅塞現象為湖口-竹北路段(橫軸編號 24),時間大致從早上 7 點開始,下午 5 點結束。
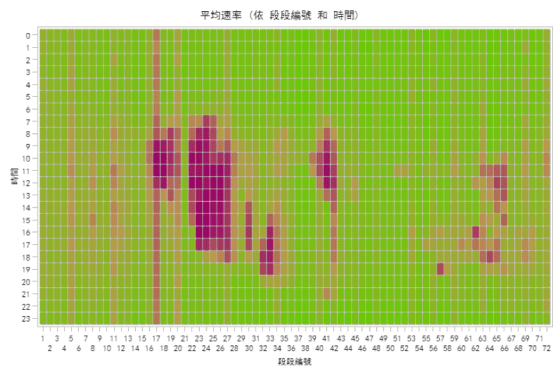
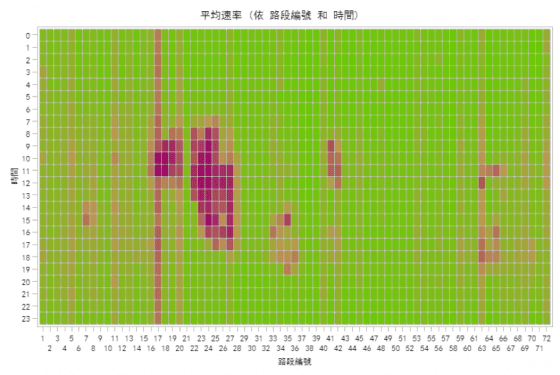
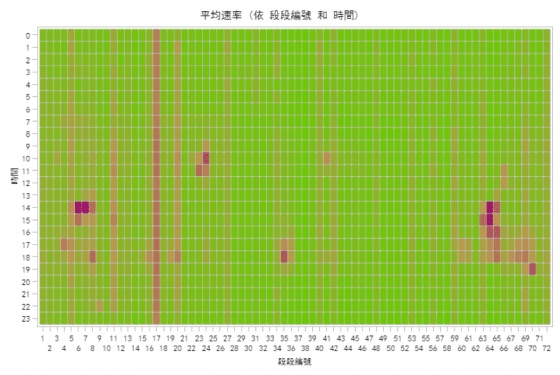
回顧一下去年228連續假期第 1 日(105 年 2 月 25 日,如圖二)以及今年一般假日星期六(106 年 2 月 18日,如圖三)國道 1 號南下的交通情形。可以發現,今年 228 連續假期第 1 日的車流狀況與去年 228 第 1 日較為相似,而與一般假日(如星期六)有很大的差異。我們可以知道,時間絕對是分析交通壅塞現象的重要變數,而交通壅塞現象仍是不斷的重現。
塞車發生的又快又急:交通量與速率的關係
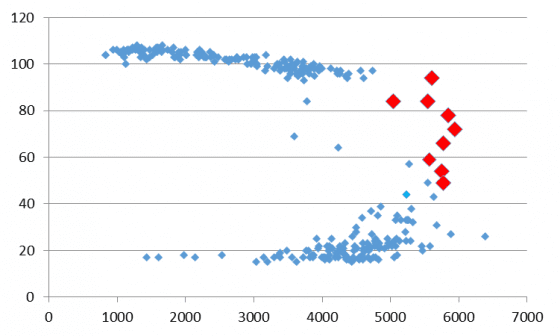
為方便分析,以下分析交通量,均先將 5 分鐘交通量換算成 1 小時的流率。既然壅塞是由湖口-竹北路段開始發生,便進一步針對該路段做分析。圖四為 106 年 2 月 25 日每 5 分鐘的平均速率與交通量(5 分鐘交通量換算成 1 小時)所繪之雙軸圖,從上午 6 時 40 分(虛線部份)平均速率開始快速下降,不到 60 分鐘的時間便由時速 94 公里降至低於 40 公里,隨後則是長達 5 小時的低速率。而在 6 點 40 分至 7 時 20 分之間,路段卻維持相當大的交通量(5,500~6,000 輛)。
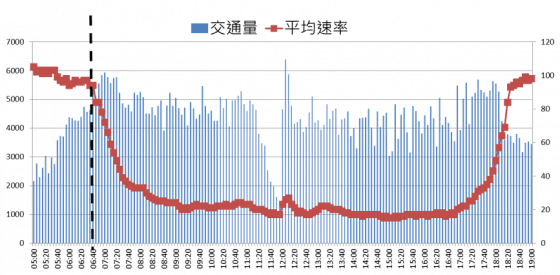
若將前述資料以散佈圖呈現,橫軸為交通量,縱軸為平均速率,其分佈會近似於二次式線型(如圖五)。我們將 6 點 40 分至 7 點 20 分之間的樣本特別以紅色標記,可以發現這些樣本約略是線型的極值,也就是該路段經常能夠通過的最大交通量,又稱之為「容量」。
若路段交通量能夠一直接近容量,將會達到相當大的效率。但事與願違,交通量接近容量時,路段上的車間距已經達到臨界值,其狀況相當不穩定,一點擾動就會造成壅塞開始發生,因此無法長時間的維持,相關內容請參閱前文《塞車:看不見的時間小偷》。
是哪裡來的車被塞在路上?
車輛被塞在路上的同時,本身也是塞車的成因,這便是所謂的外部成本。以下分析關鍵的 106 年 2 月 25 日 6 點 40 分至 7 點 20 分通過湖口-竹北路段交通量的組成,究竟這些車輛是從哪裡來,往哪裡去,並且是從何時出發的呢?
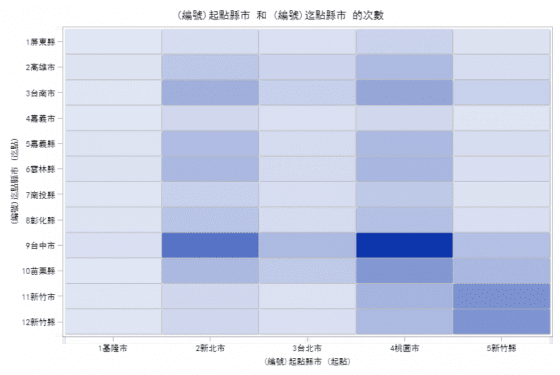
圖六橫軸代表車輛由該縣市進入高速公路(起點),縱軸代表車輛離開高速公路(迄點),方格顏色代表旅次數量(起點至迄點的車輛數),顏色越深代表旅次數量越多,這張圖在交通管理的應用中,稱為「旅次起迄表」(O-D table)。由圖六可以知道,最多的旅次為桃園市至台中市(11%),其次為新北市至台中市(7%),再來則是新竹縣至新竹市及新竹縣縣內旅次(5.3%、5.1%)。
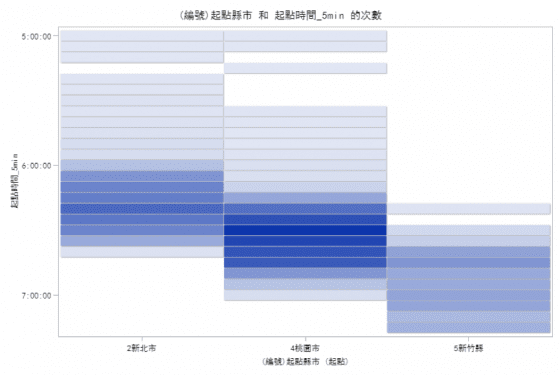
圖七橫軸代表車輛由該縣市進入高速公路(僅列旅次數量前 3 名,新北市、桃園市及新竹縣),縱軸為車輛進入高速公路的時間,格子顏色越深代表旅次數量越多。我們藉此觀察早上 6 點 40 分至 7 點 20 通過湖口-竹北路段的車輛進入高速公路的時間。從新北市進入高速公路的時間集中分佈於6:00–6:40、桃園市分佈於6:15–7:00,新竹縣分佈於6:30–7:15。
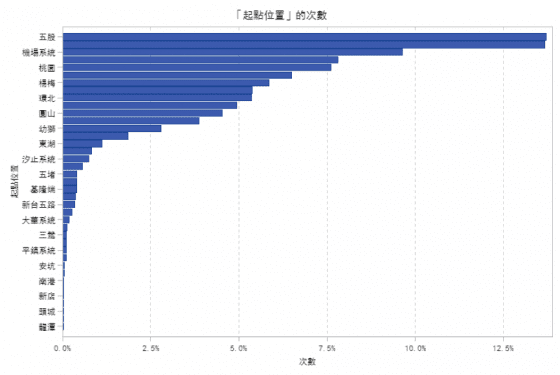
若將觀察維度由縣市更進一步至交流道,最多車輛由五股交流道(13.7%)進入,第 2 名為湖口交流道(13.6%),第 3 名為機場系統交流道(9.6%),第 4 名為林口交流道(7.8%),第 5 名為桃園交流道(7.6%)。圖八為所有交流道做為旅次起點的排名(由大至小)。
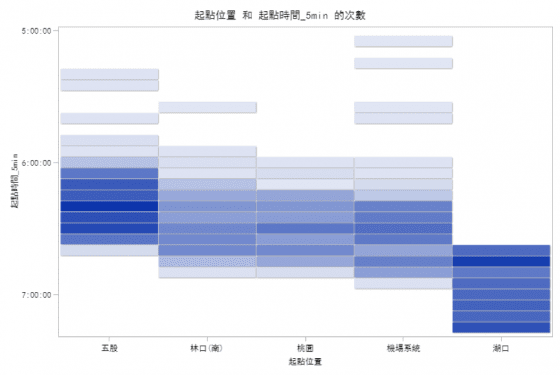
圖九橫軸為車輛進入高速公路交流道的前 5 名(五股、林口、桃園、機場系統、湖口),縱軸為車輛進入高速公路的時間,車輛由五股交流道進入高速公路的時間集中分佈於 6:05–6:40,林口交流道分佈於 6:10-6:50,桃園交流道分佈於 6:15–6:50,機場系統交流道分佈於6:20–6:55。
想要阻止塞車,還需要多少努力?
ETC 交通資料是根據車輛通過偵測站而蒐集,通過單一門架可以蒐集到交通量資料;通過相鄰兩門架可以蒐集路段的平均旅行時間、平均旅行速率;通過多個偵測站集到旅次資料,如車輛的起迄點、起迄時間、旅次長度等。本文以 106 年 2 月 25 日的 ETC歷史交通資料分析壅塞路段、時間以及路段容量,亦介紹了一些交通管理應用上的圖形工具。
在《塞車:看不見的時間小偷》一文中探討了交通壅塞的發生以及一些基本車流知識,我們可以知道當路段交通量接近容量時,也亦謂著壅塞即將發生。
既然路段的交通壅塞現象可能不斷重現,我們是否可以利用歷史資料的分析,改善現有的交通控制策略,並於路段交通量接近容量時,適時的於上游匝道減少車輛進入,阻止壅塞現象的發生?

「匝道儀控」係藉由號誌管制匝道車輛進入高速公路,目標是在不影響高速公路主線交通的前提下,使匝道通過最多的車輛,以緩和交通壅塞並紓解平面道路。我國於民國 87 年 8月 1 日開始實施,目前已經有許多關於「匝道儀控」的研究,但是在過去的研究中,資料來源多是根據單點偵測的交通資料。理論上從 ETC 交通資料中取得車輛旅次起點及進入高速公路的時間,將可以更有效的分配壅塞路段上游匝進入的車輛。
在理想的情況下,我們可以透過 ETC 所蒐集的交通資料,進行科學化的分析精進匝道儀控的實施,但是在實際上該如何執行,以及執行上可能面臨的一些問題,我們將在未來的文章中再繼續探討。































{kind=link}