




在所有的固體裡,都存在著或多或少的缺陷。
有些缺陷來自於晶格空穴,這些空穴與鄰近原子之間可能形成「二能級系統(two-level systems, TLSs)」,使得一顆/一團原子在空間緊鄰、能量又相近的二個位置∕晶格組態之間來回躍動,構成一種「動態結構缺陷(dynamical structural defects)」,簡稱「動態缺陷(dynamic defects)」,如下圖(A)所示。
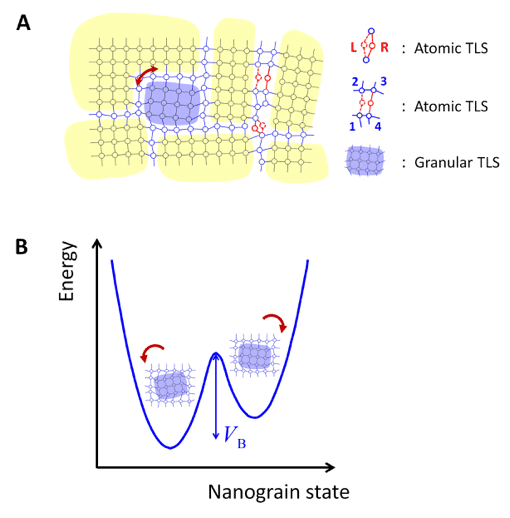
二能級系統的概念早在 1972 年就由 P. W. Anderson(1977 年諾貝爾物理學獎得主)與 W. A. Phillips 等人分別提出,用於解釋非晶態材料的低溫比熱與熱傳導的奇特行為。這種動態缺陷的自發性反覆來回躍動(fluctuations 或 repeated switches),對奈米尺度元件的效能會造成惡性影響。例如,造成超導量子位元的量子糾纏態破壞,降低量子同調時間;造成奈米機電(NEMS)元件能量耗散,降低其品質因子(quality factor),進而影響量子極限量測的能力;和造成低頻雜訊(1/f noise),影響奈米電子元件的性能等。
幾十年來的研究證實,動態缺陷大多源於單顆原子在空間中的躍動,稱為「原子二能級系統(atomic TLSs)」。至於材料中的奈米尺度晶粒(nanocrystalline grain)——包含上千、甚至上萬顆原子——是否也能如原子二能級系統般,在二個晶格組態之間來回躍動,則是科學文獻中的一個長久未解之謎。上圖(B)表示我們稱之為「晶粒二能級系統(granular TLSs)」的理論模型,二個介穩晶格組態被位能障 VB 分隔,晶粒可以藉由熱激發(高溫時)或是量子穿隧(低溫時)在二個位能阱之間不斷反覆變換位置。
從缺陷到奈米元件
就基礎研究層面而言,如某些特殊磁性材料中,電子自旋會形成晶格般的有序排列結構(skyrmions),此結構的邊界,最近被發現乃是由材料中原子晶格的晶粒邊界所衍生。因此,材料中的晶粒如果產生躍動行為,將導致這類自旋排列邊界的擾動,從而影響 skyrmion 的動力學性質。就技術應用層面而言,工業上對量產與大面積材料的強烈需求,使得市面元件大多呈多晶體(polycrystalline)結構。如大面積化學氣相沉積的石墨烯,薄膜矽奈米線生物感測器等都是。倘使奈米尺度晶粒產生躍動,將嚴重影響這類元件的精密效能。因此,晶粒二能級系統具有重大和即時的產學研發意義。
最近,我們在室溫下觀測到二氧化釕(RuO2)金屬奈米線中奈米晶粒的自發性整體來回躍動行為。高解析穿透式電子顯微鏡的影像顯示,二氧化釕奈米線內部含有許多奈米尺度晶粒,如下圖中(A) G1 到 G6 黃框所標示。二氧化釕中的氧缺陷(空穴),則會形成原子二能級系統,很可能大量處於晶粒邊界,因此造成晶粒之間的鍵結減弱,從而產生晶粒轉/滑動現象。
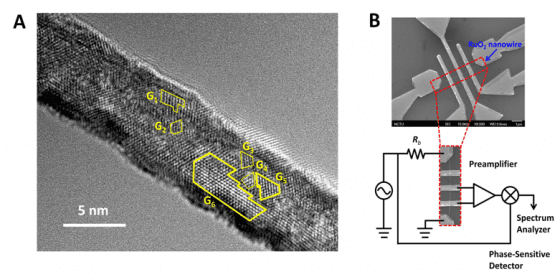
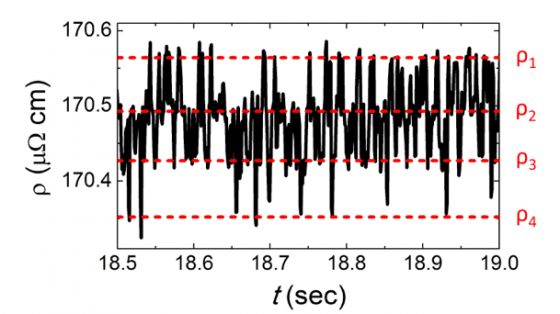
上圖中(B)顯示由電子束微影技術製作的奈米線元件。我們使用調變–解調方法,將前置放大器的輸入雜訊降到最低。下圖顯示奈米線電阻隨著時間在幾個固定值(由 ρ1 到 ρ4 四條紅色虛線標示)之間來回變動。這些跳動值遠大於電子的熱雜訊,也遠大於由原子二能級系統造成的電阻變化。詳細計算和分析顯示,這些電阻跳動來自於晶粒二能級系統的整體躍動(collective motion)行為,躍動晶粒的大小與電子顯微鏡的觀測結果一致。進一步的分析可以算出奈米晶粒的遲豫時間(relaxation time),和晶粒邊界的鍵結強度(VB)——這些微觀參數無法從其他實驗方法獲得。晶粒邊界的鍵結強度是決定奈米元件機械強度的一個重要因素。
半導體工業對微小化的迫切需求,使得元件間導線的寬度不斷縮減,電流密度從而增大,造成原子因電流撞擊而移動,即「電致遷移(electromigration)」現象。電致遷移最終會導致元件之間斷路,使得積體電路的「可靠性(reliability)」成為一個嚴峻課題。我們的高精度電性測量方法能用於研究電致遷移現象,有助於次 10 奈米元件連接線材料的開發。
- 這項研究由交通大學物理所葉勝玄博士後研究員、張文耀碩士生(已畢業)和林志忠教授合作完成,發表於 2017 年 6 月 23 日《Science Advances》期刊。
- 本文感謝葉勝玄博士、林志忠教授(交通大學物理研究所)撰稿。林志忠老師網頁

本文摘自《物理雙月刊》39 卷 8 月號 ,更多文章請見物理雙月刊網站。





























