




文/潘昌志|「你地質系的?」不,但我待過地質所,而且還是海研所的碩士。無論在氣象局、小牛頓…都一樣熱愛地科與科普。現在從事試題研發工作,並持續在《地球故事書》、《泛科學》、《國語日報》等專欄分享地科的各種知識,想以科普寫作喚醒人們對地球的愛。

這篇我們來聊聊稍微難一點點的地震科學,不過會盡可能用簡單方式切入。
過去,如果有機會和對小朋友講到地震成因時,我經常會提一個很簡單又不簡單的問題:
我:「地震是怎麼來的?」
小朋友:「是板塊運動!」
我:「那板塊是什麼?」
小朋友:「是我們腳下的地方」
我:「板塊『運動』就會地震?那板塊是地震時才運動?還是一直都在動呢?」
這可不是故意要刁難孩子們,而是在科普推廣的經驗中發現了許多常見的盲點,一有機會我就會想盡辦法導正。過往許多教育或某些片段的科普知識,在「地震成因」的部分,經常會以板塊構造運動的學說,來解釋板塊運動伴隨而生的地震。

不過,事情才沒這麼簡單呢!人們嘗試用不同方式去了解地震成因的歷史已有數千年,不過到了 1906 年舊金山地震後,人們才連結了地震與斷層的關聯,至於 1960 年代才興起板塊學說,也和地震的關係密不可分,板塊學說可以用來解釋地震,地震其實也是建構板塊學說模型的佐證,今天我們不止談科學,也談歷史,從地震的科學史來看人們探尋地震成因的脈絡。
將地震和斷層摻在一起的第一人:萊尹爾爵士
最早的人們觀測地震的狀況,不過就是「地在搖晃」而已,但因為大地沒事不會搖晃,加上古代人也不會知道地下除了石頭之外還有些什麼,所以也根本想不懂地震是哪來的。
自古以來有許多人嘗試了解地震,不過因為距離理論仍太遙遠,我們直接跳到較重要的一位主角:英國地質學家萊尹爾爵士。
你可能沒聽過他,但他是在地質學和演化論的發展上皆扮演了重要角色,他支持赫登的「均變說」,覺得世間的許多地質的現象都是經年累月慢慢形成的,就像滴水能穿石般的緩慢……而後來達爾文在發展演化論時,多少也受到地質學的影響(這又是另一個故事,我們之後再聊)。

回到正題,萊伊爾走遍大江南北,看了很多「斷層」,他的想法是:
「斷層不是一天造成的!」
我們在國中課本上看到的斷層,經常都會看得出它的「錯動」方向,但實際上很多時候斷層長得又是另一種樣子,甚至斷層兩側是八竿子打不著邊的岩層,認真一算,搞不好從古至今滑動了好幾十公尺。所以,萊伊爾就覺得這應該是一點一滴累積而成的。
這時,恰巧有一起證萊伊爾想法的地震發生,1855 年地震發生時紐西蘭雖不能算是殖民地,但也是英國的好朋友,萊尹爾就從紐西蘭地震後得到的資料,確認了地震與斷層的關聯。
不過對於當時萊伊爾的想法僅止於找出「相關」而非「因果」,這就像是雞生蛋在先,還是蛋生雞在先的問題一般,到底地震是「怎麼樣發生」,還無法解釋。
感謝那些地震後變形的圍籬
時間跳到近 50 年後,1906 年舊金山地震造成加州灣區嚴重的傷亡,但也因為它發生在人們已充分開發的地區,所以有完整的測量資料,就像是我們現在家家戶戶都有畫好地圖地籍一樣。地震後重新測量,發現有些地方的錯動量十分驚人啊!
欸?不對啊,這件事不是跟萊伊爾看到的狀況一致?到底是要怎麼看出斷層「怎麼動」的?
這時就要感謝辛勤的加州的畜牧業者,幫我們記下了斷層在地面留下的痕跡,如果要開個牧場,勢必要蓋圍籬。有些牧場的圍籬就正好蓋在斷層線上,在地震過後,正好就發現了這些先來後到的圍籬,記下了截然不同的變形。

如果是已經蓋好非常久的圍籬,地震後幾乎完美的截成兩半,明顯的看出斷層的變形。不過,如果是地震前沒多久才蓋好的圍籬,卻是斷成弧形的,這樣太奇怪了!
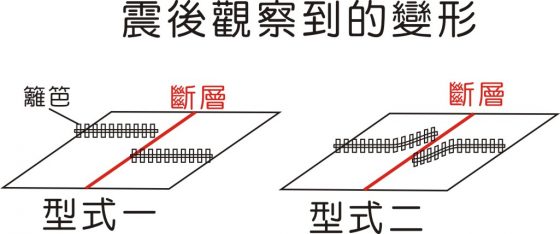
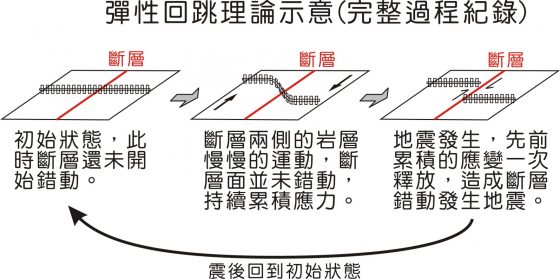
然後,在 1906 地震後多達一千六百多頁的報告中,有一篇「地震的機制」,作者里德(Henry Fielding Reid)闡述了地震與斷層的關係,提出彈性回跳理論來解釋斷層上發生的現象和地震之間的關係…真要細講應該寫個三個星期都講不完,所以還是先跳結論-斷層錯動引發地震的過程可以分成三個階段:
第一階段:斷層未受外力的作用也沒產生變形的階段
第二階段:隨著力量的累積,變形也慢慢的變化,而此時斷層面因為摩擦力的作用,是整塊卡住還沒有斷開的,整塊地層像有彈性般變形。
第三階段:斷層上面的作用力和摩擦力的平衡達到臨界點,一口氣錯動開來,並同時發生地震,地震就是釋放突然錯動產生的能量變化。
就加州的聖安德列斯斷層來說,斷層上的地震便以這樣的方式周而復始發生,在一次大地震後,就有點像是重置這個循環回到第一階段一樣。這個理論不是隨便說說,而是建立在精密的震後測量上,包括前面提到的圍籬變形方式。
而前面提到的「型式二」的變形方式與彈性回跳理論並不矛盾,反而是忠實呈現接近同震的變形:
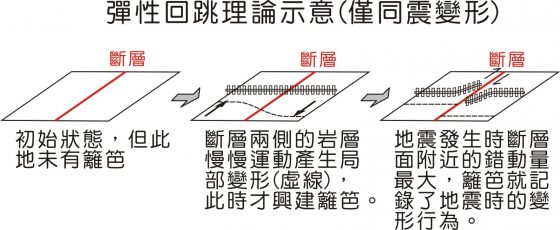
更重要的是,上述用圍籬的示意方式,不僅僅是個概念上的理論,還能用數學式子來解釋。因此現在我們才能運用地震波、精密測量與地震後的觀察紀錄來研究斷層的行為,雖然並不是每個斷層的特性都相同,但多數經過重覆的觀察後都可以簡化成上述的行為與方式,這也是目前我們對於地震成因的認識。
雖然這個理論至今仍普遍用來解釋地震的成因,不過其實當時的這個理論還沒辦法完全幫我們解開問題。從前文的脈絡至少就可以列出幾點疑問:
1. 這個理論有沒有例外?
2. 讓斷層附近變形和錯動的「外力」是哪來的?
3. 理論上提到的狀況是已經有斷層了,那斷層又怎麼「從無到有?」
我們先來聊聊「例外」的情況,有沒有不是循這種模式的呢?
有!譬如火山地區岩漿庫內的岩漿增加、移動或冷卻時所造成的地震。

而就算是與斷層作用相關的地震,也不是百分之分就能分成這三個階段,有些斷層經常緩緩的錯動,不發生地震或是僅發生規模很小的地震,有些斷層則是既會發生大地震,也會發生無震的滑移或是小地震,這些差異受了很多因素影響,像是斷層面上的摩擦性質、外力作用的大小與變化,甚至鄰近地區的大地震,也可能間接改變了斷層面性質與能量累積的臨界等,這種種差異,也讓現今科學家不斷修正、調整各項理論的看法。
至於第 2 和第 3 點疑問?其實現今的科學已早有解答。板塊構造學說用板塊運動解釋了「為什麼會有外力」讓地表附近的岩層產生各種變形,而斷層怎麼「從無到有」,則又可以從實驗室中岩石力學的實驗來驗證。不過這兩項又得再花個兩篇文章來細說分明,就暫且賣個關子或請參閱延伸閱讀略知一二吧。
讀到這裡,可以發現「地震成因」在科學上仍然是個待解之謎,我們還有更長的路要走,這些假說、理論都還有調整修改的空間。即使如此,也沒什麼好洩氣的,更不要想「這些理論又不一定是真理」而認為地震學者都在做些無意義的事,起碼這些層層疊疊的前人肩膀,逐漸長高到讓我們越來越靠近真理。未來若有人能完全解開所有的地震機制之謎,可以想見他也是像牛頓一樣,站在巨人的肩膀上吧!
本文原發表於《震識:那些你想知道的震事》部落格,或是加入按讚我們的粉絲專頁持續關注。將會得到最科學前緣的地震時事、最淺顯易懂的地震知識、還有最貼近人心的地震故事。
延伸閱讀:
- 彈性回跳理論的介紹與互動動畫(英文網頁)
- 感謝終於有人關心到地震成因(by 阿樹)
- 地震的原因(台大地質數位典藏計畫網頁)
關於地震機制的文獻:
- Scholz, C. H. The Mechanics of Earthquakes and Faulting 439New York: Cambridge University Press, 1990.
關於彈性回跳理論的文獻:
- Reid, H.F., The Mechanics of the Earthquake, The California Earthquake of April 18, 1906, Report of the State Investigation Commission, Vol.2, Carnegie Institution of Washington, Washington, D.C. 1910































{kind=link}
.jpg){kind=link}
{kind=link}