- 作者/施登騰 中國科技大學互動娛樂設計系主任

今年(2018)年 3 月 14 日傳來史蒂芬・霍金(Stephen Hawking )博士 76 歲長眠的消息,舉世同哀。早上開電腦上網後,看到有更多他的相關消息與回顧,這些熱烈討論從昨天到今天都仍持續不斷著。
霍金的語音代言人

曾與家人一同欣賞史蒂芬・霍金的傳記電影「愛的萬物論 (The Theory of Everything)」(頗喜歡這中英文片名),不過沒看他的「時間簡史」,只借閱過他親筆自傳《我的人生簡史》。電影透過戲劇呈現霍金博士的生平,算來是個奇特經驗。我們比較熟悉的霍金博士,是那個因罹患漸凍症,後來失去說話能力,需透過電腦語音代言,卻仍不減溝通能力與幽默的霍金博士。當然,電影中也演出了這段經歷,透過電腦語音重拾溝通能力並不簡單。
網路上可以找到霍金博士親自說明,電腦語音如何協助他發言,可以點以下影片聆聽他的熟悉聲音。
還有一個網站提供「霍金聲音生成器 (Stephen Hawking Voice Generator)」。霍金博士在影片中提到,他當時使用的語音合成軟硬體設備,是由「劍橋精益通訊公司(Cambridge Adaptive Communication)」的 David Mason 幫他裝設在電動輪椅後面;使用的是一款名為「Equalizer (等化器)」的軟體,由加州電腦專家華托茲(Walt Woltosz)於 1985 年幫霍金博士研發的,這在他的自傳中也有提到。
這合成的聲音不僅像機器人說話,而且還有美國口音。《Meet the man who lent Stephen Hawking his voice》(將聲音借給霍金的人)這篇報導中,作者 Rachel Kraus 引述雜誌《Wired》的深入報導,寫到這個聲音原屬 Dennis Klatt 這位美國麻省理工的學者,以他自己的聲音透過電腦合成而成。在 80 年,當霍金博士失去口語能力時,找到了 Dennis Klatt 所合作的《DECtalk》公司的語音合成軟體(Speech synthesizer),透過文字輸入方式進行語音合成(Text-to-Speech,TTS)。

目前霍金所使用的語音合成軟體《Equalizer》已經提供開源碼,希望能嘉惠更多有需要的人;正式的官方名稱為「Assistive Context-Aware Toolkit (輔助式語意感知工具包)」,適用於有 Windows 7 以後的版本、使用 C# 語言;不支援 Mac 系統。有需要進一步資訊的話, 雜誌《Wired》2015 年 8 月的這篇報導「You Can Now Use Stephen Hawking’s Speech Software For Free」(免費使用霍金用的說話軟體!)會更清楚。
由於漸凍症的緣故,霍金博士除了逐漸失去說話能力;即使電腦語音的拼字輸入方式,也因症狀加劇而逐漸弱化。到了後期,霍金博士甚至需要借助 IR 去偵測臉頰肌肉運動進行輸入控制,使用的是《Words Plus》公司的軟體《EZ Keys》,只要輸入幾個字,前方螢幕會據以顯示候選字句,讓霍金博士以臉頰的微幅動作控制選字句組合,然後再透過 《Equalizer》轉成聲音檔,也就是那個美國口音的機器人聲 。
據 Rachel Kraus 引述雜誌《Wired》的報導,霍金博士不僅在《DECtalk》公司進行語音合成軟體升級時,要求使用原聲音檔,甚至後來 Intel 為他建置新的軟體時,還在他的堅持下,找回 Dennis Klatt 的原始聲音檔去進行軟體升級。大家可以欣賞「Master Of The Universe: Stephen Hawking」(宇宙大師:霍金)這部紀錄片,片中 22:10~22:40 這一段就有霍金博士以臉頰動作輸入文字的畫面。

人機互動──語音助理可以做到什麼?
這令人遺憾的新聞確實讓我想到「人機互動 (HCI)」的發展(很抱歉),加上最近跟好友借用了《Amazon Echo》跟《Echo Dot》來玩,常常在早上就使用,會「請」Alexa 服務,說聲「Alexa, Play music.」,Amazon 的語音助理 Alexa,就會幫我播「70 年代電台音樂」,也玩過《Jeopardy 猜謎》,這是 24,000 多個 Alexa Skills(技能)提供的服務(根據 2017.12 數據)。

Amazon 也開放 Alexa Skills Kit,歡迎第三方參與開發。iOS 的 Siri 自然我也常用,因為上下班搭車移動中習慣戴耳機,所以都會長按耳機控制鈕呼叫出Siri,要她播音樂或撥電話。但有許多科技報導說得很直白,直接指出 Siri 不僅被遠遠拋在 Amazon Alexa 與 Google Assistant 後面,更不用說相關應用根本跟不上Amazon Alexa Skills 與 Google Me-Too 的第三方應用那樣的快速發展。
也有篇科技新訊提出相關分析,並特別點出三家公司在發展「Voice First Platform」這種新型個人數位服務與應用平台上的顯著差距,或許會成為影響三家公司發展前景的致命關鍵。

替 Siri 配音的人
此外,再談談原音重現。就像霍金博士的語音合成的原音是 Dennis Klatt。iOS Siri 在發音上非常接近自然人聲,而最常用的女音則是 Susan Bennet 的聲音組合的(見下圖),而男聲版本的,可以查到資料的是幫英國 Siri 版配音的 Jon Briggs,他算是 iPhone 4 第一代 Siri 的男聲。
而根據 Susan Bennett 接受訪問的錄音內容「Siri is dying. Long live Susan Bennett」,她提到她在2005年接到一個配音委託,當時她不知道這些錄音是做什麼用的,整整花了 1 個月,每天 4 小時去錄許多短句,後來還是同事在 2011 年問她,她才知道是用在 Siri 的人聲語音服務上。只不過 Apple 也未曾正式承認 Susan Bennett 就是 Siri 這個機器人助理的幕後人聲。
但對 Susan 來說,至少 CNN 請了專家鑑定確定,她在 TED 以「Accidentally Famous: The Story Behind the Original Voice of Siri 」為題演講過;但根據報導,Jon Briggs 卻還接到 Apple 電話,被要求不要公開談論他就是 Siri 的男聲,理由就是「不希望 Apple 的數位語音助理被聯想到特定的人」。他們兩位曾同時被訪問過這些特殊經驗,有興趣者可以看這篇訪問稿:「Hey, Siri! Meet the real people behind Apple’s voice-activated assistant」。

如何讓數位語音助理「聽起來」越來越像人?
那就接續談談在發音上越來越接近人聲的數位語音助理(Digital Voice Assistant)吧!
之前在「The Voice of Museum」這篇分享中(博物館學會網站刊載連結),曾於針對博物館科技應用談到「數位語音助理」與「語音服務」時,有提到如下的內容:
無論是把 Echo、 Siri,、Cortana 稱之為語音助理(Voice Assistant)、虛擬助理(Virtual Assistant)、人工智慧助理(AI Assistant、AI-Powered Virtual Assistant),而且就像「The Surprising Repercussion of Making AI Assistants Sound Human」以及「Why Do So Many Digital Assistants Have Feminine Names」談到的議題,我們對人工智慧科技服務的具體想像,其實不是機器人助理,而是更接近「人」的虛擬助理,無論是在語音對答服務時更像真人的語調,或者是在命名與性別上。
文章中提到所謂的「依存互動 Contingent Interaction」,並引用研究說人類比較能夠對可以來回反應、對話與互動的人事物有所連結。報導也都提出不僅「擬人 Humanlike」是具體目標,兼有個性與實用性(Personality and Utility)的虛擬助理服務也是眾所企求的。
這也讓我想起在智慧博物館《AI 上博物館》中,引述 Deeson 廣告公司的科技策略總監 Ronald Ashiri 在文章《How Museums Are Using Chatbots》(博物館如何應用聊天機器人),其中的概念「Giving chatbots a face」(賦予聊天機器人個性形貌)。就從上述所分享的實際案例來看,目前的人工智慧發展已讓「想像」逐漸成真。
其中所提的數位語音助理的 Humanlike、擬人化( anthropomorphic)傾向,以及命名女性化的特徵,在在顯示了數位助理的研發,是在追求一個全知的 AI 語音助理;或許在具體樣貌上,就會越來越接近電影《鋼鐵人》的人工智慧助理:J.A V.I.S. (Just Another Rather Very Intelligent System的縮寫) 。

人機互動的溝通:語音轉文字,文字轉語音
前面提到,霍金博士透過軟體《EZ Keys》選擇字句,再由軟體《Equalizer》轉譯成聲音。這種 Text-to-Speech(TTS,文字轉語音)的數位轉譯形式對現在的數位技術來說其實是很簡單的應用,因為已有很多 App 都能支援,即使是逆向工程:Speech-to-Text(STT,語音轉文字),也已經很普及,像是現在手機輸入法中內建的語音輸入法。
特別再提及這點,是因為「文字」與「語音」都是與 AI 數位助理溝通的重要媒介與元素。就如同在《AI 上博物館》與《AI 上互動娛樂設計系》[註1](這兩篇所介紹的許多數位語音應用,博物館與其不同業界所使用的「AI 聊天機器人」,不管是「純簡訊服務類(text messaging service)」、「即時對話服務類 (chatbot conversational service) 」、「問與答諮詢類(Q&A chatbot service)」類;基本上,人機互動都是透過「文字」或/與「語音」溝通。
像 Google 就研發了專屬的「語音合成標記語言」( the Speech Synthesis Markup Language;SSML )技術來支援語音合成應用程式,並操控互動語音系統;使得與 AI 數位語音助理的對話,可以像是跟某人說話互動一樣。
舉兩個實際的應用案例:
Google Story Speaker (互動故事閱讀器)
基本概念是將在網路文件編輯器 《Google Doc 》上所編寫的互動腳本(文字檔),透過 Add-On (附加元件)加入應用程式《Story Speaker》,就可以使用智慧管家《Google Home》或語音助理《Google Assistant》,以語音播放;「文字朗讀功能(TTS)」再加上「語音辨識功能(STT)」,就可以讓《Google Home》成為《Story Speaker》,而且還會在特定段落詢問閱聽者的決定,提供不同路線的故事內容,導引到不同的故事結局。
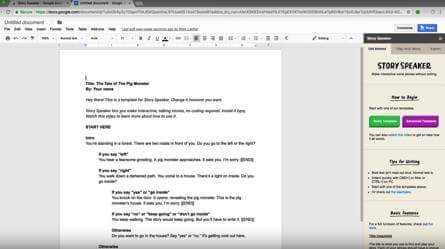
Google Grilled Murder Mystery(互動偵探角色扮演)
此應用的概念,是讓玩家在這個語音互動應用程式中的謀殺案中扮演偵探的角色,玩家透過訪問四名嫌犯中的每一名去調查餐館老闆的命案的線索,以確定誰才是兇手。此應用程式也使用了 SSML 語音合成標記語言技術,所以玩家就像是透過一位「助理」的協助,進行命案的偵查。

現代人工智慧可以執行什麼任務?
所以無論與語音助理之間的溝通,是透過 TTS 或 STT 形式,在未來,透過人工智慧、自然語言處理、機器學習等先進技術的導入,要在現實生活中有 JAVIS 協助打點一切,並提供全知的資訊服務,並非不可能。
「語境(Context)」、「語言(Language)」、「推理(Reasoning)」被視為人工智慧的三大挑戰,但如果是要考慮的 AI 數位語音助理之研發應用的話,它們也是機器學習、自然語言處理兩項技術的重大挑戰。
現如今,金融特別是一個全面採用 AI 技術、自動化技術的行業,也就是大家熟悉的 FinTech 趨勢。針對「數據資料導向任務(Data-Driven Task)」的自動化來說,AI 技術已被充分運用了,AI 財經機器人已能自動撰寫處理「基金財務報告 Fund Reporting」、「損益分析報告 Profit & Loss Reports」、「信用管理報告 Credit Management Reporting」、「銷售報告 Sales Reporting」(資料來源)。看來,許多挑戰已隨著應用需求與科技發展,而逐漸被克服。
而我的重點是,人工智慧技術、機器學習模型已經能夠自動判斷文本的結構和含義,像是根據霍金博士輸入的幾個字,自動判斷後提供「選用字句(Candidate Sentence)」,有效減少輸入次數;或者像前面例舉的「互動偵探角色扮演(Grilled Murder Mystery)」此一類型的智慧語音應用。
「全知型」互動對話導覽服務
在 TTS、STT、AI、Machine Learning、NLP 等技術的持續發展,以及典藏資料庫的內容支援下,很期待未來有機會在博物館、商展、展演機構見到「全知型」互動對話導覽服務的出現。

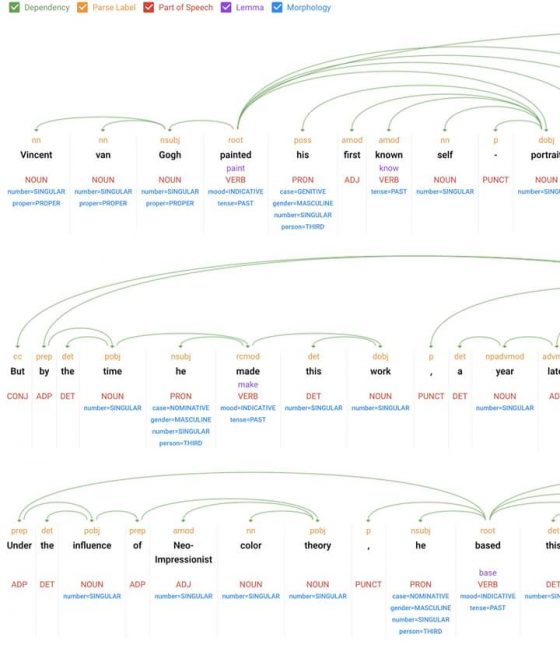
下圖是使用自然語言處理(NLP)技術,利用分析器(Parser)將一段「畫作說明文字」(梵谷自畫像)進行語法分析(Syntactic analysis)的結果。這段「畫作說明文字」在數位處理分析後,由分析器解構成各個詞彙單位,並呈現其結構和含義。語法分析也用來建立樹狀的語法樹(syntax tree),透過中間表述提供詞彙單位串流的語法結構。
該段說明文字如下:
「Vincent van Gogh painted his first known self-portrait in 1886, following the model of the 17th-century Dutch artist Rembrandt. But by the time he made this work, a year later, he had clearly shifted his allegiance from the Old Masters to the Parisian avant-garde. Under the influence of Neo-Impressionist color theory, he based this painting on the contrast of complementary colors.」
Syntax分析結果見下圖:
也就因為這些強大的數位技術支援,我們與機器的「文字」或「語音」互動對話,都能更自然,人工智慧更思考能力,人機互動更接近我們的日常行為。所以數位科技讓因為漸凍症無法言語的霍金博士仍能繼續寫作、演講;相信數位科技也打開了與具有龐大內容的數位語音助理/電腦/資料庫進行深度互動的機會。
WATSON,美術館中的全知數位導覽員
我個人認為的理想數位導覽應用典型,應該是是巴西奧美廣告公司與 IBM 公司合作,於 2017 年 6 月在巴西聖保羅博薩博物館(Pinacoteca do Estado de Sao Paulo) 所推出的數位導覽服務《The Voice of Art / with WASTON》。
這個 App 使用的數位語音技術就是由 IBM 研發的《WATSON》。研發團隊為了培養 WATSON 的應答能力,共花了 6 個月時間與西聖保羅州立博物館策展人和研究員合作,以大量的書籍、報導、傳記、訪談、網路資料、影片讓 WATSON 透過機器學習累積對於藝術作品豐富知識與答案,並擴大可對話與提供回覆的範疇,WATSON 就像個全知的數位導覽員。
在「The Voice of Art / with WASTON」的宣傳影片中,研發人員說:
「用預錄的聲音介紹藝術史,並不是真正的互動。」
所以他們花了非常大的努力,希望讓 WASTON 與使用者有更自然的對話。影片中,有位小孩則看著肖像畫,問畫中人物說「你喜歡踢足球嗎?」。我想 WASTON 的確做到了!!!!

- 本文轉載自作者臉書,原標題為〈數位「代言人」〉。
- 編按:相關內容也歡迎參考這篇報導–〈中國科大互動系推出對話機器人〉