



- 作者/照護線上編輯部
- 本文轉載自 Care Online 照護線上《突破治療困境!新一代口服標靶BTK抑制劑,為邊緣區淋巴瘤MZL患者帶來治療新曙光,血液腫瘤專科醫師圖文解說》,歡迎喜歡這篇文章的朋友訂閱支持 Care Online 喔
- 加入照護線上 LINE 官方帳號,健康資訊不漏接

年近八十歲的陳老先生(化名),某天因胃不適而去做胃鏡檢查,意外發現罹患胃部邊緣區淋巴瘤,且蔓延到淋巴結、脾臟,全身都受到影響。高雄長庚血液腫瘤科副科主任王銘崇醫師指出,「由於患者的腎功能與心肺功能較差,所以治療藥物的選擇較有限,使用傳統治療成效也較不理想,遺憾不到一年的時間就離世了。」
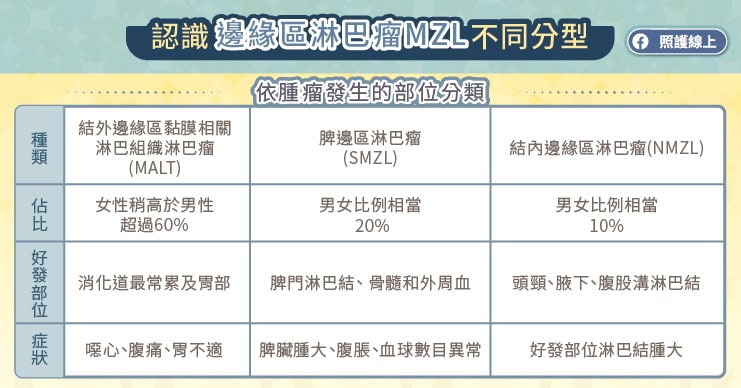
邊緣區淋巴瘤(MZL,marginal zone lymphoma)是一種源自 B 細胞的非何杰金氏淋巴瘤,王銘崇醫師解釋,臨床上將 B 細胞淋巴瘤區分為低惡性度、中惡性度、高惡性度,而 MZL 是屬於低惡性度的 B 細胞淋巴瘤,腫瘤生長與分裂緩慢,部分患者不需立即接受治療,而是採「觀察及等待」。王銘崇醫師指出,MZL 較常發生在中老年人,根據國際學術期刊全球患者發生部位可分為三種亞型,結外邊緣區粘膜相關淋巴組織淋巴瘤(MALT)佔超過 60%、脾邊緣區淋巴瘤(SMZL)約佔 20% 、結內邊緣區淋巴瘤(NMZL)約佔 10%[1],而根據其發生的部位不同,會造成相異的症狀,不過多數「沒有症狀」,患者較多是在接受其他檢查時意外發現。
低惡性度淋巴瘤也不可輕忽!好發部位影響預後應積極治療
邊緣區淋巴瘤(MZL)患者的預後與腫瘤生長部位有關,王銘崇醫師說,若腫瘤長在胃部,積極配合治療,患者的生命期和一般人沒有太大的差別;但長在肺部可能影響呼吸,有胸痛、咳嗽,甚至咳血等症狀較危及性命;或為結內邊緣區淋巴瘤(NMZL)可能干擾造血功能,而影響存活。王銘崇醫師表示,臨床醫師與病理科醫師會根據臨床症狀、骨髓檢查、影像檢查等資訊,來決定邊緣區淋巴瘤的亞型,但也提醒腫瘤可能隨著時間轉移至其他部位,民眾不可輕忽,需持續追蹤觀察。
BTK 抑制劑助力 MZL 提供治療選擇
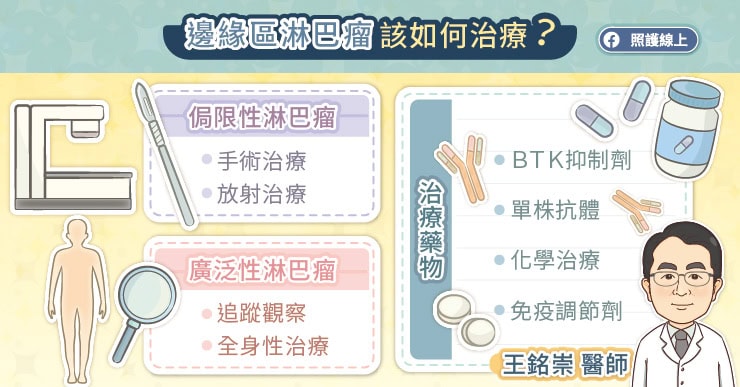
邊緣區淋巴瘤(MZL)的治療與腫瘤位置有關,根據臨床追蹤觀察,評估患者是否需要立即接受治療。王銘崇醫師指出,局限性的邊緣區淋巴瘤,可以考慮手術治療將腫瘤切除,然後再做放射治療;廣泛性的邊緣區淋巴瘤,可能需要全身性治療,包括單株抗體治療、化學治療、標靶治療、免疫調節劑等。
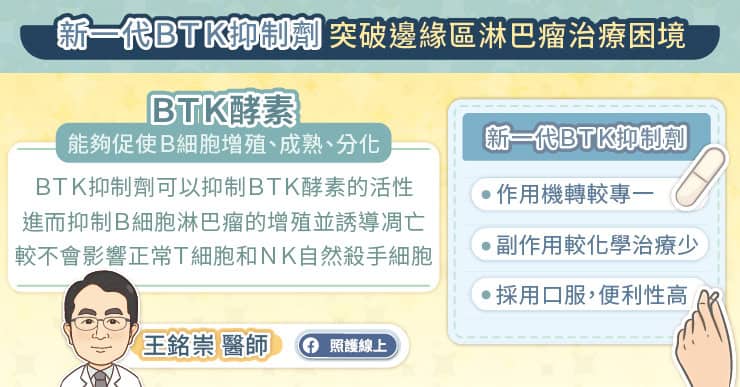
近年來,針對 BTK 靶點而發展出的 BTK 抑制劑標靶藥物,已被運用於治療相關癌症。BTK 抑製劑為抑制 BTK 活性的藥物,由於邊緣區淋巴瘤(MZL)是源自 B 細胞的惡性腫瘤,而 B 細胞表面會有一個 B 細胞受體,該受體一旦被激發,細胞的激酶 BTK 就會被激活,促進癌細胞的生長發育與轉移,把 BTK 靶點的活性抑制住,就能控制癌細胞的生長。
跟上國際治療趨勢 新一代口服BTK抑制劑有望對心臟提供更好的保護
邊緣區淋巴瘤(MZL)目前無法痊癒,患者必須定期追蹤檢查。王銘崇醫師指出,如果一開始治療效果就不好,或是治療後在兩年內復發,將被歸類為復發且難治型 R/R MZL 病人,「這類型患者的比例大概在一成左右,不過也與第一線的治療藥物有關,根據臨床癌症研究期刊 ( Clinical Cancer Research ) 於 2021 年所發表的研究報告指出—若使用新一代口服 BTK 抑制劑的反應率將大幅提升,部分患者可以得到完全緩解。[2] 」
而目前國際上對於邊緣區淋巴瘤(MZL)的治療共識肯定 BTK 抑制劑應用於 B 細胞惡性淋巴瘤的臨床優勢。為能對患者的心臟提供更好的保護與支持,目前美國國家癌症資訊網(NCCN)國際治療指引已將新一代 BTK 抑制列為用於治療 R/R MZL 優先選擇[3]。王銘崇醫師感嘆,「如果案例陳大哥有機會接受新型治療,也許會有不同的命運。」,現已有新一代口服標靶BTK抑制劑問世,提供多一種治療方案,有望提高患者生活品質,為 MZL 患者一大福音。
- 本文轉載自 Care Online 照護線上《突破治療困境!新一代口服標靶BTK抑制劑,為邊緣區淋巴瘤MZL患者帶來治療新曙光,血液腫瘤專科醫師圖文解說》,歡迎喜歡這篇文章的朋友訂閱支持 Care Online 喔
- 加入照護線上 LINE 官方帳號,健康資訊不漏接
參考資料:
- [1] Smith A, Crouch S, Lax S, Li J, Painter D, Howell D, et al. Lymphoma incidence, survival and prevalence 2004–2014: sub-type analyses from the UK’s Haematological Malignancy Research Network. Br J Cancer. 2015; 112(9): 1575–1584.
- [2] Opat S, Tedeschi A, Linton K, McKay P, Hu B, Chan H, Jin J, Sobieraj-Teague M, Zinzani PL, Coleman M, Thieblemont C, Browett P, Ke X, Sun M, Marcus R, Portell CA, Ardeshna K, Bijou F, Walker P, Hawkes EA, Mapp S, Ho SJ, Talaulikar D, Zhou KS, Co M, Li X, Zhou W, Cappellini M, Tankersley C, Huang J, Trotman J. The MAGNOLIA Trial: Zanubrutinib, a Next-Generation Bruton Tyrosine Kinase Inhibitor, Demonstrates Safety and Efficacy in Relapsed/Refractory Marginal Zone Lymphoma. Clin Cancer Res. 2021 Dec 1;27(23):6323-6332. doi: 10.1158/1078-0432.CCR-21-1704. Epub 2021 Sep 15. PMID: 34526366; PMCID: PMC9401507.
- [3] Experimental Hematology & Oncology (2023) 12:92 https://doi.org/10.1186/s40164-023-00448-5





























