



本文轉載自中央研究院「研之有物」,為「中研院廣告」
- 採訪撰文/田偲妤
- 知識諮詢/羅宇志
- 美術設計/蔡宛潔
「0~6 歲國家一起養」這是 2022 年行政院推出的國家重要政策,為了挽救逐年破新低的出生數,讓年輕人敢婚、願生、樂養,中央與地方政府紛紛加碼生育獎勵,希望藉由減輕育兒負擔,鼓勵人民多生幾個,但這樣的政策真的有效嗎?
中央研究院「研之有物」專訪院內經濟研究所楊子霆副研究員,他與政治大學臺灣研究中心合作,透過分析幸運獲得高額獎金對人們生育決策造成的改變,探討家戶財富/所得對生育的影響。發錢真的能刺激生育?一起抽絲剝繭,探討低生育率的問題癥結!

死亡大於出生,從金錢與時間挽救生育
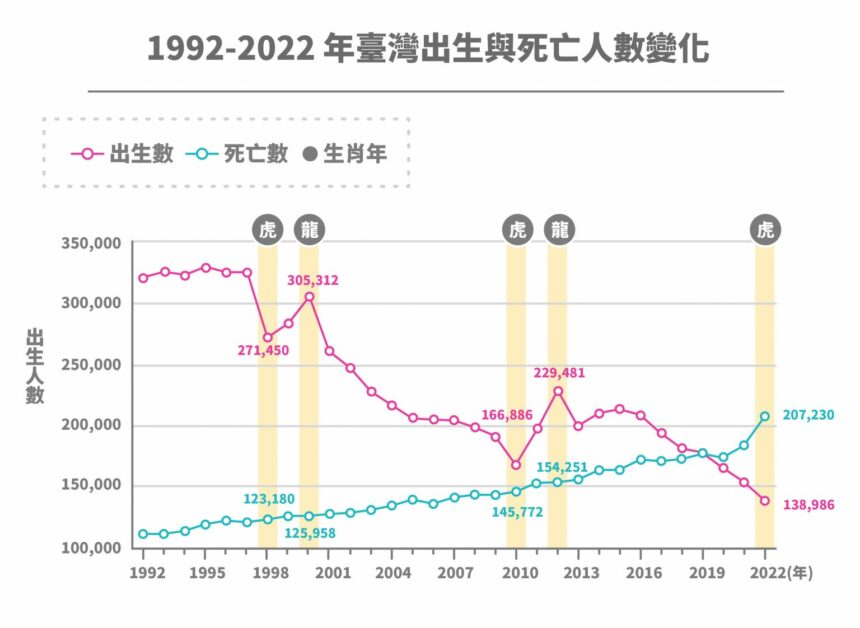
臺灣出生數再破新低!根據內政部 2022 年臺灣人口統計,全年出生數僅 13 萬 8,986 人、死亡數則為 20 萬 7,230 人,已連續三年人口負成長。為了挽救臺灣「生不如死」的現況,中央與地方政府接連加碼推出生育補助政策,但當前的政策能否有效刺激生育?經濟學如何幫助我們找出問題癥結?
從經濟學的角度來看,生養孩子代表家庭面臨兩大轉變。首先,小孩的誕生將對家戶財務資源造成衝擊,父母需要準備足夠的資金,以支付孩子的生活、教育等大筆開銷。此外,小孩的成長仰賴雙親花時間照顧與陪伴,父母勢必得改變個人目前的時間安排與職涯規劃。
因此,政府在制定相關生育政策時,得先了解現在人們不願生小孩的原因。究竟是因為大家沒有足夠收入養育孩子?還是害怕生下小孩,將無法兼顧自己的工作,必須放棄原先的生涯發展?
如果是因為財務資源不足而不願生育,則透過提高生育獎勵等現金補助政策,或許就能刺激生育率。但若是養育小孩造成父母面臨是否得犧牲個人工作職涯的抉擇,則增加現金補助未必能達成目標,反而是普及公共托育服務、提供育嬰留停的工作保障等,讓父母能兼顧工作與家庭的政策,才能有效提高大家的生育意願。
常有人說收入不夠是國人生育意願低落的主因,要驗證這個因果關係並不容易,因為家戶收入高低往往跟教育程度、工作型態等同時會影響生育決策的因素有關。為了排除這些干擾因素,最好的方式是,隨機分配高額獎金給一群正值生育年齡的男女,一組人很幸運得到一大筆意外之財,另外一群人則沒有。
接著觀察這兩組人在幾年後的生育狀況,由於獎金是隨機分配,跟任何因素都無關,因而我們可以確認兩組人生育狀況的差異,可能就是來自意外之財造成的收入提升所致。這種天上掉餡餅的荒唐事聽起來就像中樂透。
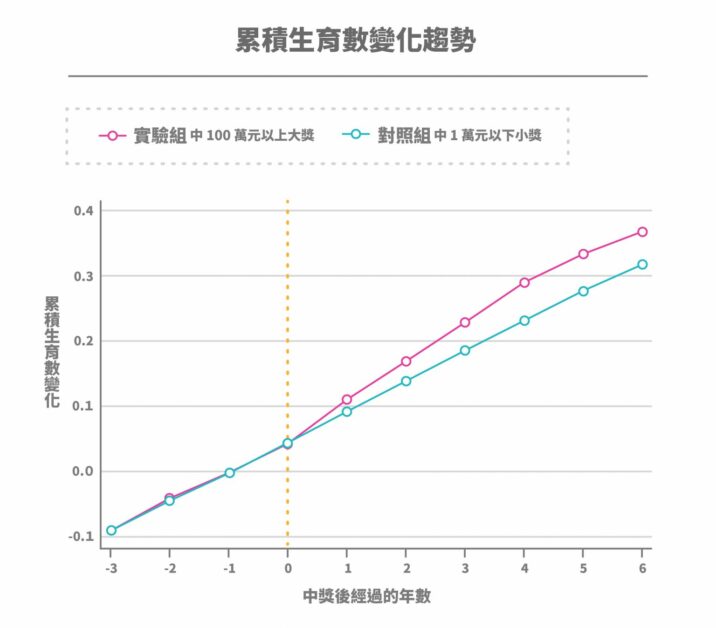
沒錯,中樂透!中研院經濟研究所楊子霆副研究員與政治大學臺灣研究中心的研究團隊合作,利用 2004 至 2018 年的行政資料為研究材料,選擇 20 至 44 歲曾經中過樂透與統一發票的家戶,比較中 100 萬元以上大獎(實驗組)與中 1 萬元以下小獎(對照組)的家戶,在中獎前 3 年到中獎後 6 年之間的累積生育數變化。
中越大獎越能刺激生育?
研究結果顯示,中 100 萬元以上大獎者,在中獎後 6 年的累積生育數,相較於中小獎者大約增加 0.07 個。換句話說,每 100 個中 100 萬元以上大獎的家戶,最後會有 7 個小孩因這筆意外之財而誕生。然而,這樣的生育個數變化,相較於這群人的財富增加量,變化程度不算大。
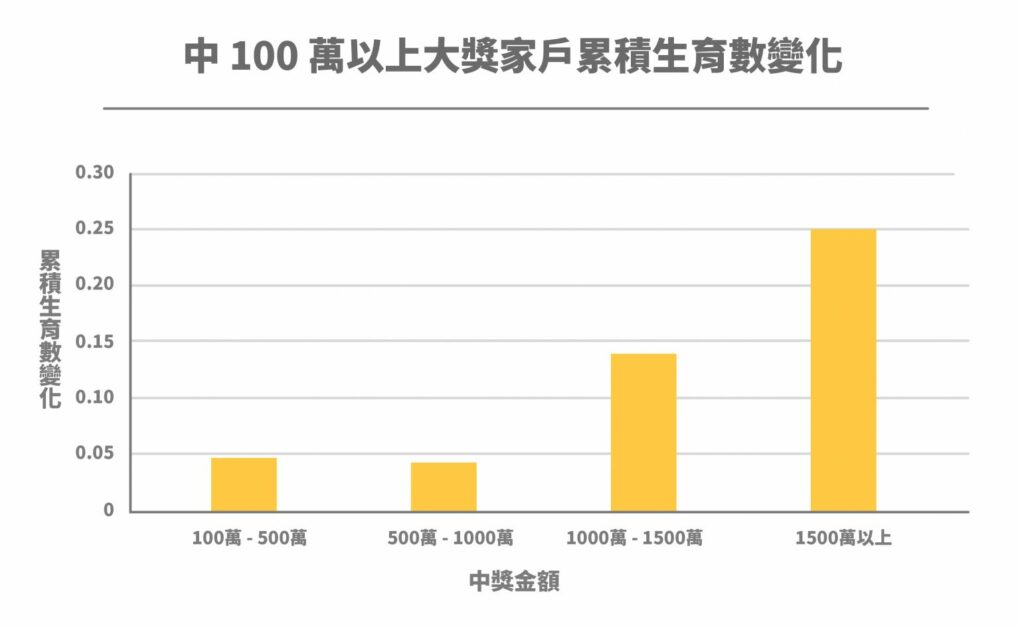
由於養育小孩開銷很大,中獎金額若是不夠高,未必能讓人願意生育。於是,研究團隊又將中 100 萬元以上大獎的實驗組進一步區分,比較不同中獎金額家戶的生育個數變化。
研究結果發現,中大獎金額若在 1,000 萬元以下的家戶,儘管也是得到相當高額的獎金,但他們的生育個數並不會因為這筆意外之財而有明顯的提升。中大獎造成的生育效果多集中在那些獲得 1,000 萬元以上高額獎金的家戶,平均來說,每 100 個家戶會多生 25 個小孩。巧合的是,新聞曾經報導,將一個孩子從出生養到 18 歲,所需的平均花費正好大約是 1,000 萬元。
若再進一步分析不同類型家戶的生育反應,則發現中獎造成的財富增加,主要是讓低收入家戶願意生育。此外,對於本來已有小孩的家戶,得到高額獎金後,有可能將這筆錢用來栽培現有的子女,並沒有讓他們再多生幾個孩子。因此,生育效果大多來自那些未婚且沒有小孩的家戶。
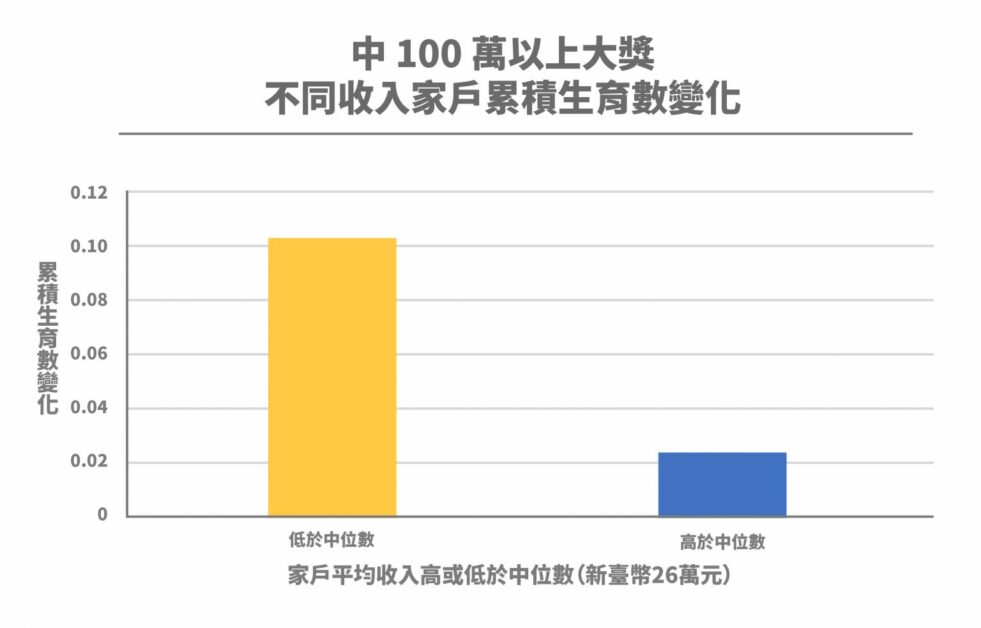
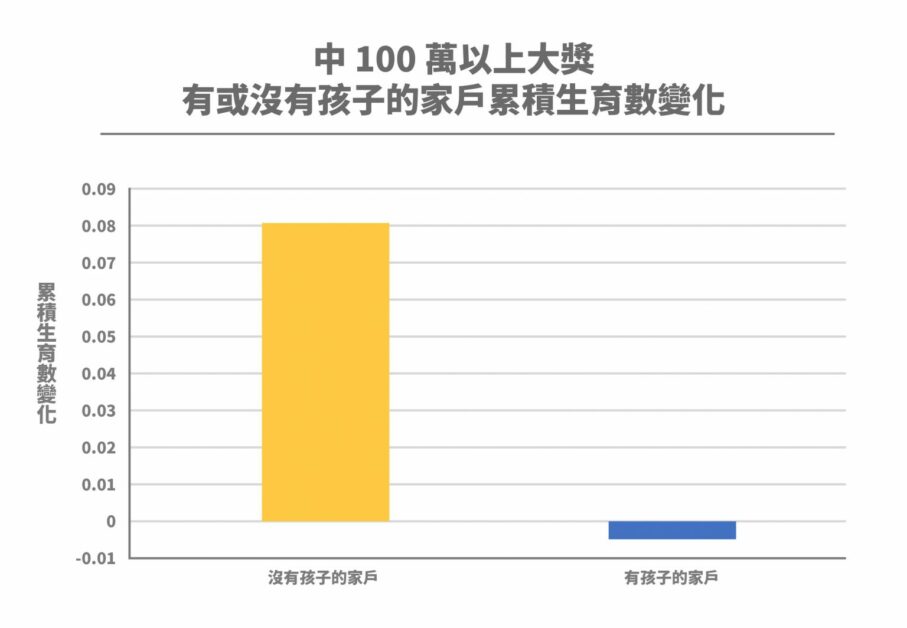
抽絲剝繭低生育率問題
總結上述研究結果,我們發現提高收入確實會增加生育個數,但金額要相當高,才會看到明顯的變化。這對政府生育補貼政策有一些啟示:
仰賴發錢提高生育率,效果可能相當有限!
生育率的提升主要集中在那些得到 1,000 萬元以上大獎的家戶,但是政府不可能發放這麼高額的生育獎勵。那麼政府的生育政策應該如何調整呢?
楊子霆提出問題癥結:「養育小孩不單只是增加開銷,更重要的是對個人時間安排的衝擊,如何讓父母不因小孩出生而犧牲自己的發展,應該是政府促進生育政策處理的核心議題。」
當代社會對於自我實踐的追求,讓人們對生育卻步,此現象在已開發國家尤其常見。根據 2020 年調查的人均國內生產毛額(GDP)與總生育率關係顯示,人均國內生產毛額越高的國家,其總生育率也越低。
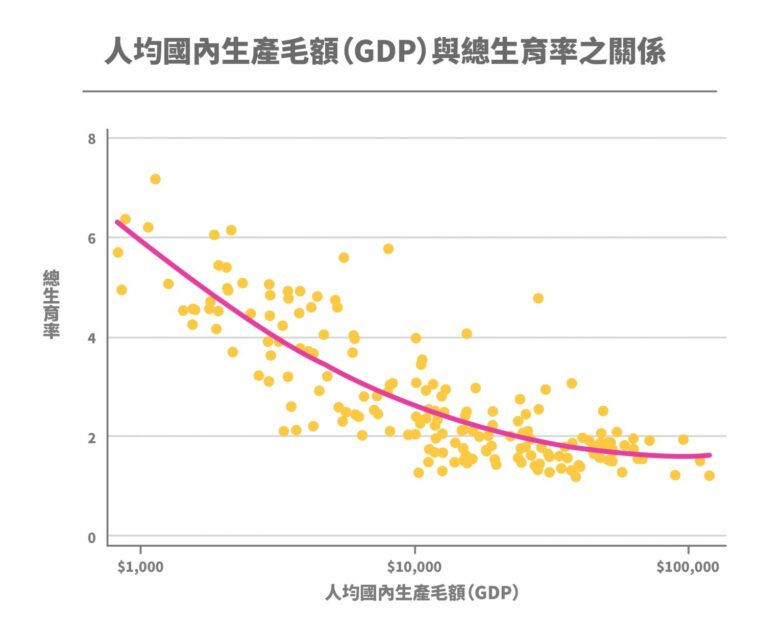
原因可能出在經濟繁榮的已開發國家,人民教育水平與個人所得偏高,若將時間花在工作上,可以獲得高報酬與高成就,但這也意味著因生育而犧牲的個人時間成本也越高,民眾生育的意願自然也較低。
東亞文化對生育率的影響
臺灣、日本、南韓等東亞國家的生育率在全球敬陪末座,除了上述原因之外,背後可能還受文化因素影響。東亞儒家社會普遍存在「先結婚後生子」的觀念,因此絕大多數孩子都是婚生子女。
根據統計,臺灣 90% 以上的已婚家庭都會生育孩子。換句話說,如果結婚率低,生育率也會連帶偏低。
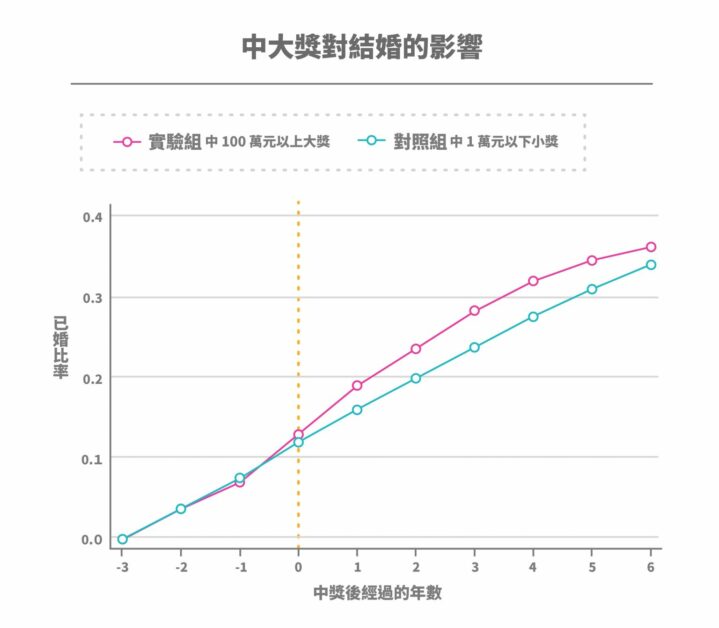
此外,許多東亞社會仍保有「男主外女主內」的傳統,這樣夫妻分工明確的現象最初是建立在男性教育程度與工作收入遠高於女性的情況下。然而,隨著時代改變,女性的教育程度提高,男女之間的收入差距也跟著縮小。但是,男主外女主內的觀念還是存在,似乎沒跟上社會發展的腳步。
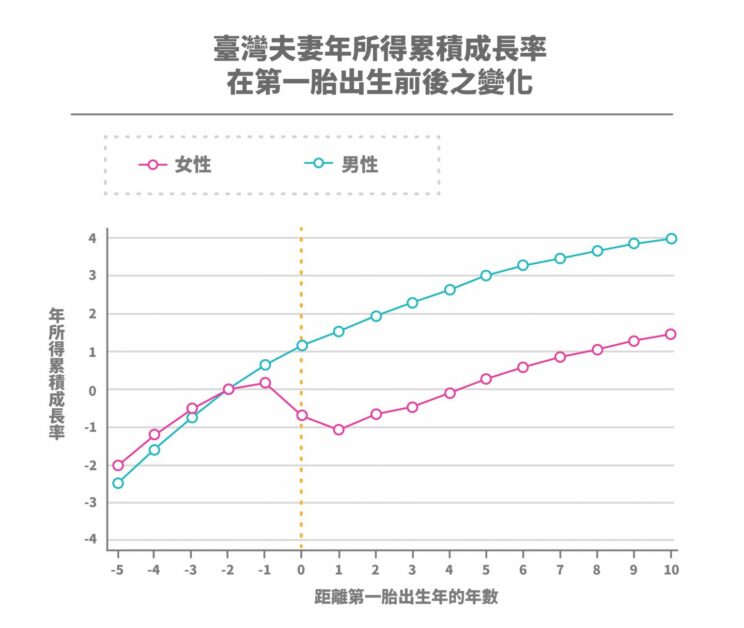
一旦家中多了需花時間照顧的孩子,又沒有其他親友或托兒所代勞,夫妻其中一方可能得犧牲工作來顧小孩。那麼誰是最常做出犧牲的一方?楊子霆秀出一張怵目驚心的圖,呈現臺灣夫妻的年所得在第一胎出生後的變化。
圖/研之有物(資料來源/楊子霆)
2004 至 2019 年間的資料顯示,在第一個孩子出生前,夫妻之間的年所得成長率差距不大,妻子甚至還略高於丈夫。但是在第一胎出生後的當年開始發生驚人轉變。妻子的收入成長率相較於丈夫直接下滑超過 20%,而且該差距再也沒有縮小。
這個驚人的差異除了是許多女性因生育而退出勞動市場帶來的影響外,對於那些留在職場的女性,他們可能為了兼顧育兒家務而放棄升遷的機會。如果上述情形沒有改變,將使得多數人不願意步入婚姻,生育率也跟著難以提升。
追根究柢,人們最擔心的是結婚生子後,可能得犧牲自己的生涯規劃。
如果想提升人們的生育意願,除了改變東亞傳統的家庭觀,政府應該提出更多能幫助父母同時兼顧生養子女與個人生涯的政策。例如:增加公共托育設施、居家托育服務、擬定方便育兒的請假制度,並保障請產假和育嬰假的勞工就業權利,讓人們不因生子而成為家庭的犧牲者,可以持續在社會上實踐自我。
延伸閱讀
- 楊子霆老師個人網站
- Tsai, Yung-Yu and Han, Hsing-Wen and Lo, Kuang-Ta and Yang, Tzu-Ting (2022). The Effect of Financial Resources on Fertility: Evidence from Administrative Data on Lottery Winners. Available at SSRN.
- 楊子霆(2022)。發錢能提高生育率嗎?獨立評論@天下。
- 【研之有物】為何孩子越生越少?人口學家鄭雁馨談少子化困境






























