

本文轉載自中央研究院研之有物,泛科學為宣傳推廣執行單位。
- 採訪撰文/田偲妤
- 美術設計/蔡宛潔
AI 的誕生,文理缺一不可
人工智慧(Artificial Intelligence,簡稱 AI)在 21 世紀的今日已大量運用在生活當中,近期掀起熱議的聊天機器人 LaMDA、特斯拉自駕系統、AI 算圖生成藝術品等,都是 AI 技術的應用。多數 AI 的研發秉持改善人類生活的人文思維,除了仰賴工程師的先進技術,更需要人文社會領域人才的加入。
中央研究院「研之有物」專訪院內人文社會科學研究中心蔡宗翰研究員,帶大家釐清什麼是 AI?文科人與工程師合作時,需具備什麼基本 AI 知識?AI 如何應用在人文社會領域的工作當中?

詩詞大對決:人與 AI 誰獲勝?
一場緊張刺激的詩詞對決在線上展開!人類代表是有「AI 界李白」稱號的蔡宗翰研究員,AI 代表則是能秒速成詩的北京清華九歌寫詩機器人,兩位以「人工智慧」、「類神經」為命題創作七言絕句,猜猜看以下兩首詩各是誰的創作?你比較喜歡哪一首詩呢?

答案揭曉!A 詩是蔡宗翰研究員的創作,B 詩是寫詩機器人的創作。細細賞讀可發覺,A 詩的內容充滿巧思,為了符合格律,將「類神經」改成「類審經」;詩中的「福落天赦」是「天赦福落」的倒裝,多念幾次會發現,原來是 Google 開發的機器學習開源軟體庫「Tensor Flow」的音譯;而「拍拓曲」則是 Facebook 開發的機器學習庫「Pytorch」的音譯,整首詩創意十足,充滿令人會心一笑的魅力!
相較之下,B 詩雖然有將「人工」兩字穿插引用在詩中,但整體內容並沒有呼應命題,只是在詩的既有框架內排列字句。這場人機詩詞對決明顯由人類獲勝!
由此可見,當前的 AI 缺乏創作所需的感受力與想像力,無法做出超越預先設定的創意行為。然而,在不久的將來,AI 是否會逐漸產生情感,演變成電影《A.I. 人工智慧》中渴望人類關愛的機器人?
AI 其實沒有想像中聰明?
近期有一則新聞「AI 有情感像 8 歲孩童?Google 工程師爆驚人對話遭停職」,讓 AI 是否已發展出「自我意識」再度成為眾人議論的焦點。蔡宗翰研究員表示:「當前的 AI 還是要看過資料、或是看過怎麼判讀資料,經過對應問題與答案的訓練才能夠運作。換而言之,AI 無法超越程式,做它沒看過的事情,更無法替人類主宰一切!」
會產生 AI 可能發展出情感、甚至主宰人類命運的傳言,多半是因為我們對 AI 的訓練流程認識不足,也缺乏實際使用 AI 工具的經驗,因而對其懷抱戒慎恐懼的心態。這種狀況特別容易發生在文科人身上,更延伸到文科人與理科人的合作溝通上,因不了解彼此領域而產生誤會與衝突。如果文科人可以對 AI 的研發與應用有基本認識,不僅能讓跨領域的合作更加順利,還能在工作中應用 AI 解決許多棘手問題。
「職場上常遇到的狀況是,由於文科人不了解 AI 的訓練流程,因此對 AI 產生錯誤的期待,認為辛苦標注的上千筆資料,應該下個月就能看到成果,結果還是錯誤百出,準確率卡在 60、70% 而已。如果工程師又不肯解釋清楚,兩方就會陷入僵局,導致合作無疾而終。」蔡宗翰研究員分享多年的觀察與建議:
如果文科人了解基本的 AI 訓練流程,並在每個訓練階段協助分析:錯誤偏向哪些面向?AI 是否看過這方面資料?文科人就可以補充缺少的資料,讓 AI 再進行更完善的訓練。
史上最認真的學生:AI
認識 AI 的第一步,我們先從分辨什麼是 AI 做起。現在的數位工具五花八門,究竟什麼才是 AI 的應用?真正的 AI 有什麼樣的特徵?
基本上,有「預測」功能的才是 AI,你無法得知每次 AI 會做出什麼判斷。如果只是整合資料後視覺化呈現,而且人類手工操作就辦得到,那就不是 AI。
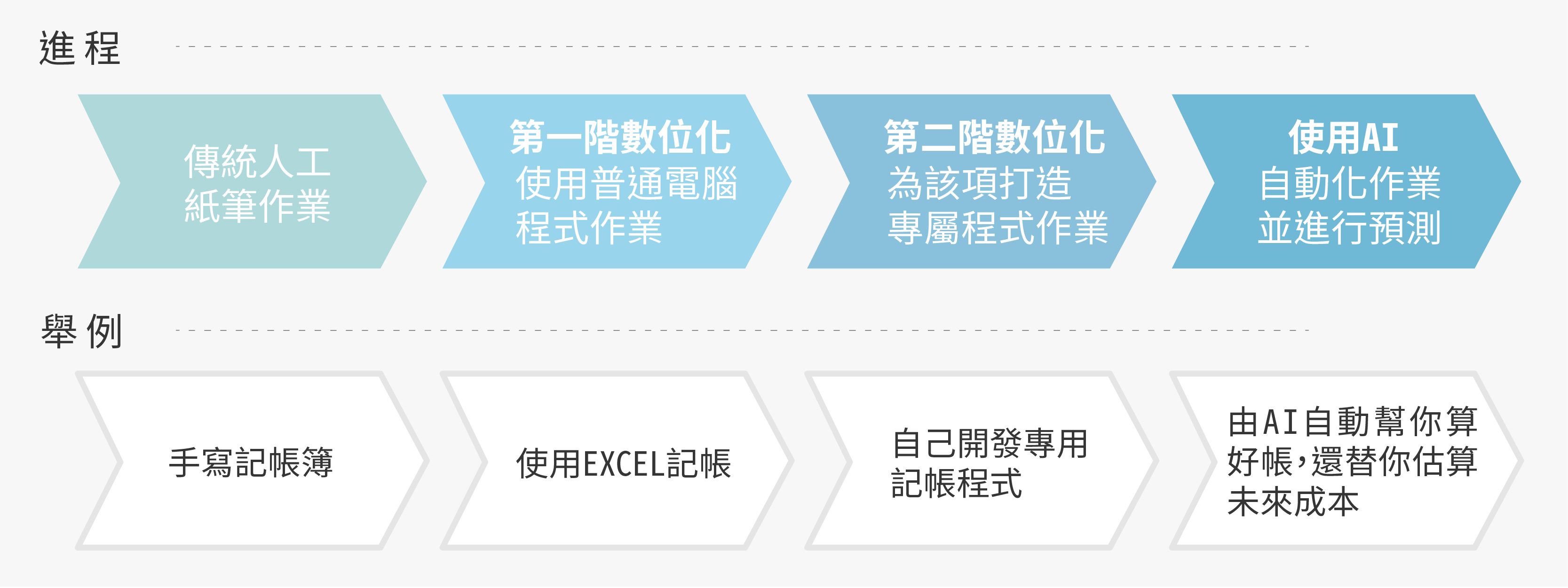
蔡宗翰研究員以今日常見的語音辨識系統為例,大家可以試著對 Siri、Line 或 Google 上的語音辨識系統講一句話,你會發現自己無法事先知曉將產生什麼文字或回應,結果可能正是你想要的、也可能牛頭不對馬嘴。此現象點出 AI 與一般數位工具最明顯的不同:AI 無法百分之百正確!
因此,AI 的運作需建立在不斷訓練、測試與調整的基礎上,盡量維持 80、90% 的準確率。在整個製程中最重要的就是訓練階段,工程師彷彿化身老師,必須設計一套學習方法,提供有助學習的豐富教材。而 AI 則是史上最認真的學生,可以穩定、一字不漏、日以繼夜地學習所有課程。
AI 的學習方法主要分為「非監督式學習」、「監督式學習」。非監督式學習是將大批資料提供給 AI,讓其根據工程師所定義的資料相似度算法,逐漸學會將相似資料分在同一堆,再由人類檢視並標注每堆資料對應的類別,進而產生監督式學習所需的訓練資料。而監督式學習則是將大批「資料」和「答案」提供給 AI,讓其逐漸學會將任意資料對應到正確答案。

學習到一定階段後,工程師會出試題,測試 AI 的學習狀況,如果成績只有 60、70 分,AI 會針對答錯的地方調整自己的觀念,而工程師也應該與專門領域專家一起討論,想想是否需補充什麼教材,讓 AI 的準確率可以再往上提升。
就算 AI 最後通過測試、可以正式上場工作,也可能因為時事與技術的推陳出新,導致準確率下降。這時,AI 就要定時進修,針對使用者回報的錯誤進行修正,不斷補充新的學習內容,讓自己可以跟得上最新趨勢。
在了解 AI 的基本特徵與訓練流程後,蔡宗翰研究員建議:文科人可以看一些視覺化的操作影片,加深對訓練過程的認識,並實際參與檢視與標注資料的過程。現在網路上也有很多 playground,可以讓初學者練習怎麼訓練 AI,有了上述基本概念與實務經驗,就可以跟工程師溝通無礙了。
AI 能騙過人類,全靠「自然語言處理」
AI 的應用領域相當廣泛,而蔡宗翰研究員專精的是「自然語言處理」。問起當初想投入該領域的原因,他充滿自信地回答:因為自然語言處理是「AI 皇冠上的明珠」!這顆明珠開創 AI 發展的諸多可能性,可以快速讀過並分類所有資料,整理出能快速檢索的結構化內容,也可以如同真人般與人類溝通。
著名的「圖靈測試」(Turing Test)便證明了自然語言處理如何在 AI 智力提升上扮演關鍵角色。1950 年代,傳奇電腦科學家艾倫・圖靈(Alan Turing)設計了一個實驗,用來測試 AI 能否表現出與人類相當的智力水準。首先實驗者將 AI 架設好,並派一個人操作終端機,再找一個第三者來進行對話,判斷從終端機傳入的訊息是來自 AI 或真人,如果第三者無法判斷,代表 AI 通過測試。
換而言之,AI 必須擁有一定的智力,才可能成功騙過人類,讓人類不覺得自己在跟機器對話,而這有賴自然語言處理技術的精進。目前蔡宗翰的研究團隊有將自然語言處理應用在:人文研究文本分析、新聞真偽查核,更嘗試以合成語料訓練臺灣人專用的 AI 語言模型。
讓 AI 替你查資料,追溯文本的起源
目前幾乎所有正史、許多地方志都已經數位化,而大量數位化的經典更被主動分享到「Chinese Text Project」平台,讓 AI 自然語言處理有豐富的文本資料可以分析,包含一字不漏地快速閱讀大量文本,進一步畫出重點、分門別類、比較相似之處等功能,既節省整理文本的時間,更能橫跨大範圍的文本、時間、空間,擴展研究的多元可能性。
例如我們想了解經典傳說《白蛇傳》是怎麼形成的?就可以應用 AI 進行文本溯源。白蛇傳的故事起源於北宋,由鎮江、杭州一帶的說書人所創作,著有話本《西湖三塔記》流傳後世。直至明代馮夢龍的《警世通言》二十八卷〈白娘子永鎮雷峰塔〉,才讓流傳 600 年的故事大體成型。
我們可以透過「命名實體辨識技術」標記文本中的人名、地名、時間、職業、動植物等關鍵故事元素,接著用這批標記好的語料來訓練 BERT 等序列標注模型,以便將「文本向量化」,進而找出給定段落與其他文本的相似之處。
經過多種文本的比較之後發現,白蛇傳的原型可追溯自印度教的那伽蛇族故事,傳說那伽龍王的三女兒轉化成佛、輔佐觀世音,或許與白蛇誤食舍利成精的概念有所關連,推測印度神話應該是跟著海上絲路傳進鎮江與杭州等通商口岸。此外,故事的雛型可能早從唐代便開始醞釀,晚唐傳奇《博異志》便記載了白蛇化身美女誘惑男子的故事,而法海和尚、金山寺等關鍵人物與景點皆真實存在,金山寺最初就是由唐宣宗時期的高僧法海所建。

在 AI 的協助之下,我們得以跨時空比較不同文本,了解說書人如何結合印度神話、唐代傳奇、在地的真人真事,創作出流傳千年的白蛇傳經典。
最困難的挑戰:AI 如何判斷假新聞
除了應用在人文研究文本分析,AI 也可以查核新聞真偽,這對假新聞氾濫的當代社會是一大福音,但對 AI 來說可能是最困難的挑戰!蔡宗翰研究員指出 AI 的弱點:
如果是答案和數據很清楚的問題,就比較好訓練 AI。如果問題很複雜、變數很多,對 AI 來說就會很困難!
困難點在於新聞資訊的對錯會變動,可能這個時空是對的,另一個時空卻是錯的。雖然坊間有一些以「監督式學習」、「文本分類法」訓練出的假新聞分類器,可輸入當前的新聞讓機器去判讀真假,但過一段時間可能會失準,因為新的資訊源源不絕出現。而且道高一尺、魔高一丈,當 AI 好不容易能分辨出假新聞,製造假新聞的人就會破解偵測,創造出 AI 沒看過的新模式,讓先前的努力功虧一簣。
因此,現在多應用「事實查核法」,原理是讓 AI 模仿人類查核事實的過程,尋找權威資料庫中有無類似的陳述,可用來支持新聞上描述的事件、主張與說法。目前英國劍橋大學為主的學者群、Facebook 與 Amazon 等業界研究人員已組成 FEVEROUS 團隊,致力於建立英文事實查核法模型所能運用的資源,並透過舉辦國際競賽,廣邀全球學者專家投入研究。
蔡宗翰教授團隊 2021 年參加 FEVEROUS 競賽勇奪全球第三、學術團隊第一後,也與合作夥伴事實查核中心及資策會討論,正著手建立中文事實查核法模型所需資源。預期在不久的將來,AI 就能幫讀者標出新聞中所有說法的資料來源,節省讀者查證新聞真偽的時間。
AI 的無限可能:專屬於你的療癒「杯麵」

AI 的未來充滿無限可能,不僅可以成為分類與查證資料的得力助手,還能照護並撫慰人類的心靈,這對邁入高齡化社會的臺灣來說格外重要!許多青壯年陷入三明治人(上有老、下有小要照顧)的困境,期待有像動畫《大英雄天團》的「杯麵」(Baymax)機器人出現,幫忙分擔家務、照顧家人,在身心勞累時給你一個溫暖的擁抱。
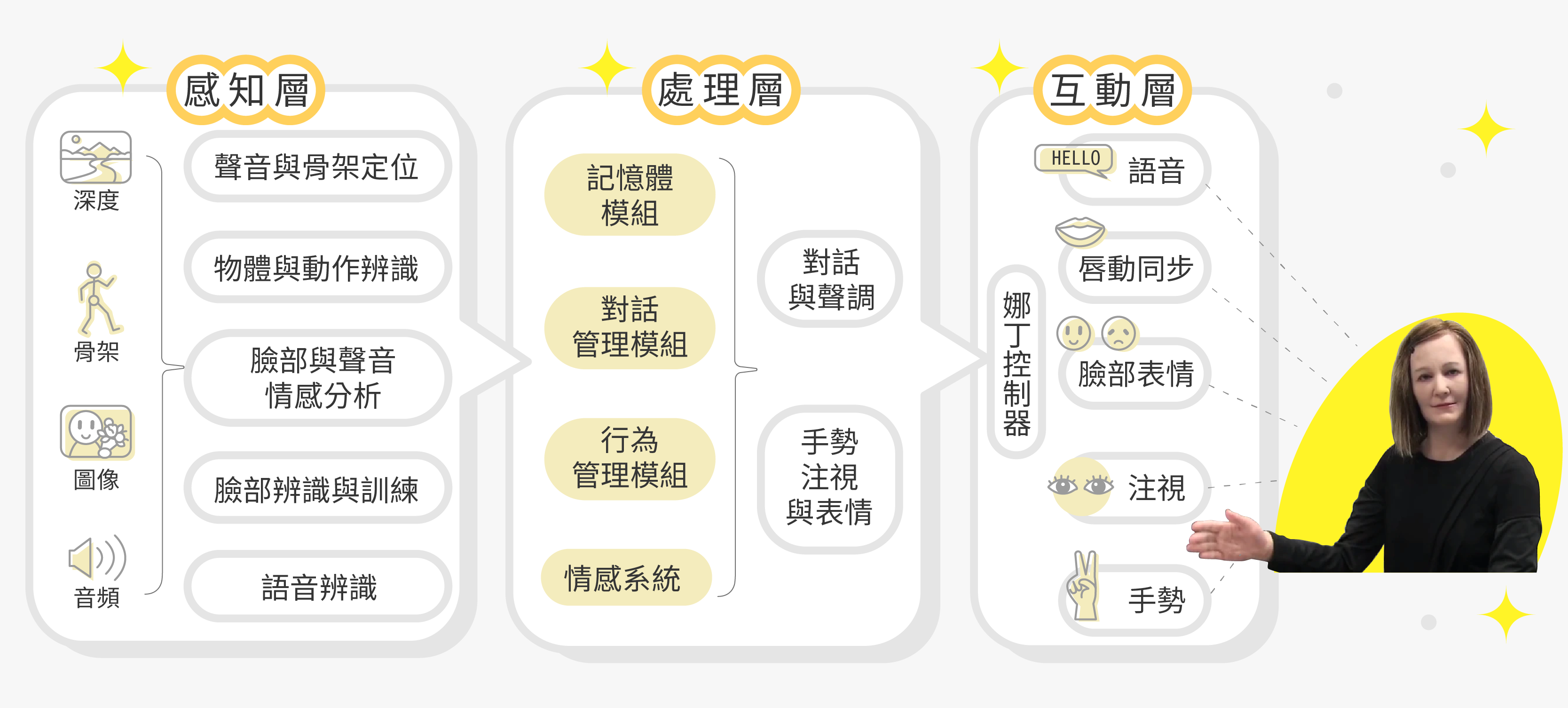
機器人陪伴高齡者已是現在進行式,新加坡南洋理工大學 Gauri Tulsulkar 教授等學者於 2021 年發表了一項部署在長照機構的機器人實驗。這名外表與人類相似的機器人叫「娜丁」(Nadine),由感知、處理、互動等三層架構組成,可以透過麥克風、3D和網路鏡頭感知用戶特徵、所處環境,並將上述資訊發送到處理層。處理層會依據感知層提供的資訊,連結該用戶先前與娜丁互動的記憶,讓互動層可以進行適當的對話、變化臉部表情、用手勢做出反應。
長照機構的高齡住戶多數因身心因素、長期缺乏聊天對象,或對陌生事物感到不安,常選擇靜默不語,需要照護者主動引導。因此,娜丁內建了注視追蹤模型,當偵測到住戶已長時間處於被動狀態,就會自動發起話題。
實驗發現,在娜丁進駐長照機構一段時間後,住戶有一半的天數會去找她互動,而娜丁偵測到的住戶情緒多為微笑和中性,其中有 8 位認知障礙住戶的溝通能力與心理狀態有明顯改善。
至於未來的改進方向,研究團隊認為「語音辨識系統」仍有很大的改進空間,需要讓機器人能配合老年人緩慢且停頓較長的語速,音量也要能讓重聽者可以清楚聽見,並加強對方言與多語混雜的理解能力。
臺灣如要發展出能順暢溝通的機器人,首要任務就是要開發一套臺灣人專用的 AI 語言模型,包含華語、臺語、客語、原住民語及混合以上兩種語言的理解引擎。這需花費大量人力與經費蒐集各種語料、發展預訓練模型,期待政府能整合學界與業界的力量,降低各行各業導入 AI 相關語言服務的門檻。
或許 AI 無法發展出情感,但卻可以成為人類大腦的延伸,協助我們節省處理資料的時間,更可以心平氣和地回應人們的身心需求。與 AI 共存的未來即將來臨,如何讓自己的行事邏輯跟上 AI 時代,讓 AI 成為自己的助力,是值得你我關注的課題。
延伸閱讀
- 蔡宗翰(2022)。寫給中學生看的 AI 課:AI 生態系需要文理兼具的未來人才。三采文化出版。
- Tulsulkar, G., Mishra, N., Thalmann, N.M. et al (2021). Can a humanoid social robot stimulate the interactivity of cognitively impaired elderly? A thorough study based on computer vision methods. Vis Comput 37, 3019–3038.



































