

- 本文轉載自科技大觀園,原文為《AI 智鬥駭客,數位戰警網路掃黑》
- 作者/李宗祐|科技大觀園特約編輯

網路數位世界黑影幢幢,美國有線電視新聞網 CNN 曾報導,全世界每天產生超過 100 萬個惡意程式;臺灣軟體聯盟也曾發布調查報告,全球企業因惡意程式攻擊,每年損失超過 10 兆新臺幣,相當於我國 109 年度政府總預算的 5 倍。駭客散播惡意程式橫行網路,不僅企業深受其害,各國政府也防不勝防。
行政院資通安全處偵測統計,我國各政府單位每月被攻擊次數高達 2,000 萬到 4,000 萬次。近期最受矚目的就是,總統府在蔡英文總統 520 連任就職前夕,驚傳遭駭客入侵電腦竊取資料;接著 5 月底美國資安公司「Cyble Inc」揭露駭客在暗網[1]兜售「臺灣全國戶政登記資料庫」超過 2,000 萬筆臺灣民眾個資,接連引發輿論譁然。
面對駭客無窮盡的闇黑攻擊,臺灣大學電機工程學系教授林宗男從 2018 年開始,帶領團隊利用資料科學處理分析,建立網路異常與攻擊預測模式,發展「AI Cyber Security」(人工智慧網路安全)系統,從偵測藏身於 Windows 與 Android 系統的惡意程式、暗網流量分類與網路惡意流量偵測等「四管齊下」,全面展開網路掃黑行動,防堵駭客散播惡意程式搞破壞。

抓出惡意程式的 AI 網路安全系統
這項研究計畫今年邁進第 3 年,「我們做出來的技術,都是可以馬上用的真槍實彈!」林宗男透露,相關前瞻技術初步成果陸續發表後,「國家安全局就找上門,要跟我們技術合作。」隨著世界各國競相重點投資,引領 AI 成為國力象徵,研究團隊除了以建置臺灣國家級網路防禦系統為目標,更希望這套系統能夠推廣成為捍衛各國企業或組織的數位戰警。
就如同 CNN 報導,全世界每天產生超過 100 萬個惡意程式,網路數位世界危機四伏;但值得注意的是,這個數據還是 2015 年的統計,現在恐怕有增無減。研究團隊以先發制人策略,杜絕惡意程式伸出魔爪,利用 CNN(Convolutional Neural Networks,卷積神經網路)模型[2]訓練 AI ,偵測是否有惡意程式潛伏在使用者電腦 Windows 或手機 Android 系統蠢蠢欲動。
Windows 與 Android 的惡意程式偵測
「我們的目標是在他還沒有執行之前,阻止惡意程式啟動。」面對五花八門的應用程式,研究團隊指出,使用者在下載執行前,「把程式的 exe 執行檔轉換成圖片檔,放進我們建立的模型,AI 就會告訴你這個程式是惡意程式的機率是多少。如果很高,就不要執行,避免系統被惡意程式感染。」林宗男強調,能夠辨認程式碼到底是惡意或者是正常,是確保網路安全最重要的基本功。
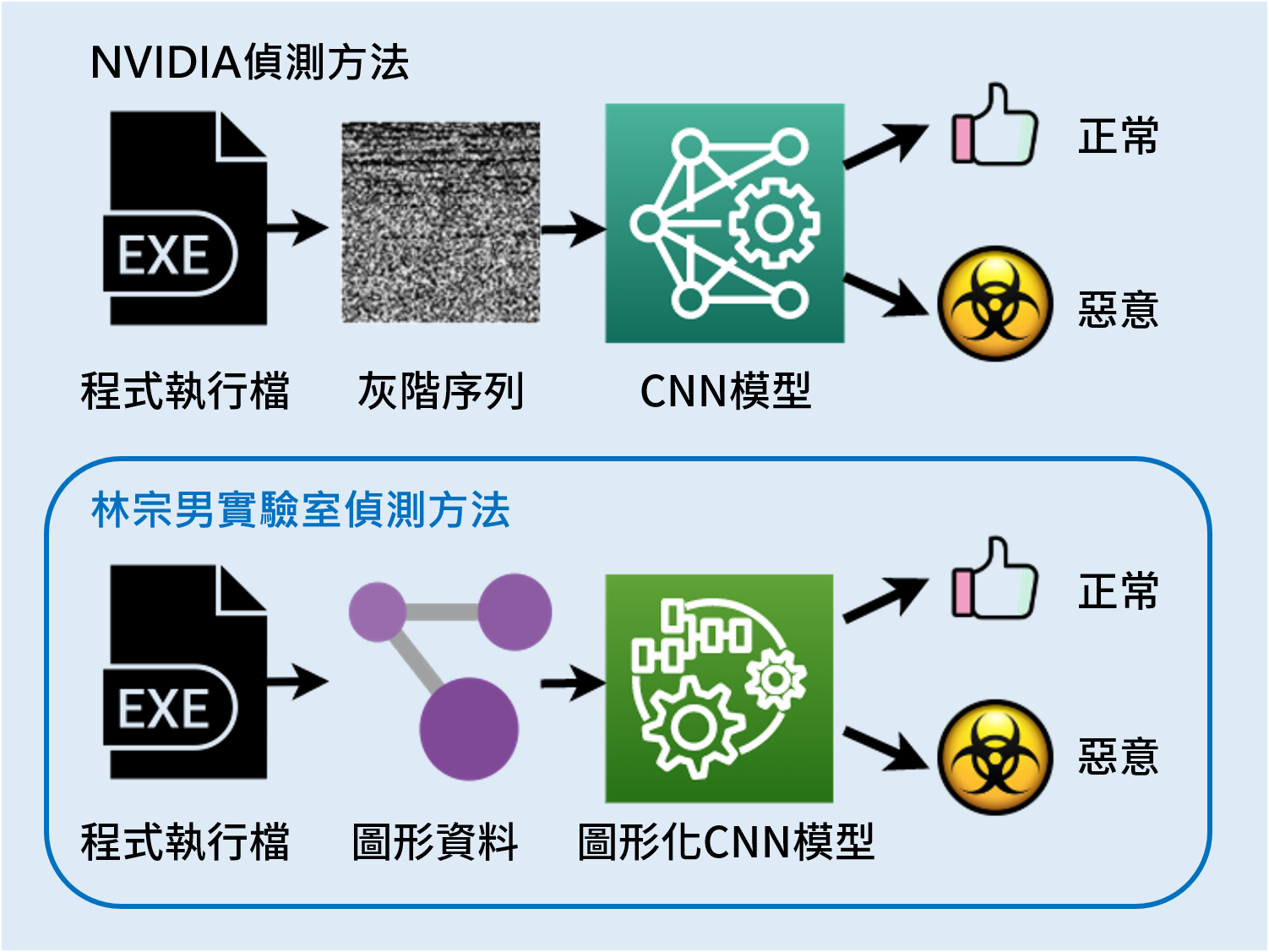
經過測試驗證,Windows 偵惡系統成功率與準確率達 88.9%,超越全球圖形處理器領導廠商 NVIDIA 發表的 AI 偵惡技術 7.2%。林宗男指出,很多軟體公司都競相投入研究,就過去已公開發表的研究論文,NVIDIA 抓駭效率暫時領先群雄;臺大團隊與擁有雄厚資源的 NVIDIA 研究團隊相較,就像是小蝦米與大鯨魚,能夠超越他們很不容易。「但這僅是初步研究結果,我們還在持續精進中。」
相對於 Windows 偵惡系統獨立開發,Android 偵惡系統則是與日本 NICT(情報通信研究機構)合作研發,利用臺大團隊提出的新演算法,把 NICT 研發的 AI 偵惡系統抓駭效率從 92% 提升到 96.2%,青出於藍而勝於藍,讓日本團隊印象深刻。
透過機器學習,分析暗網流量
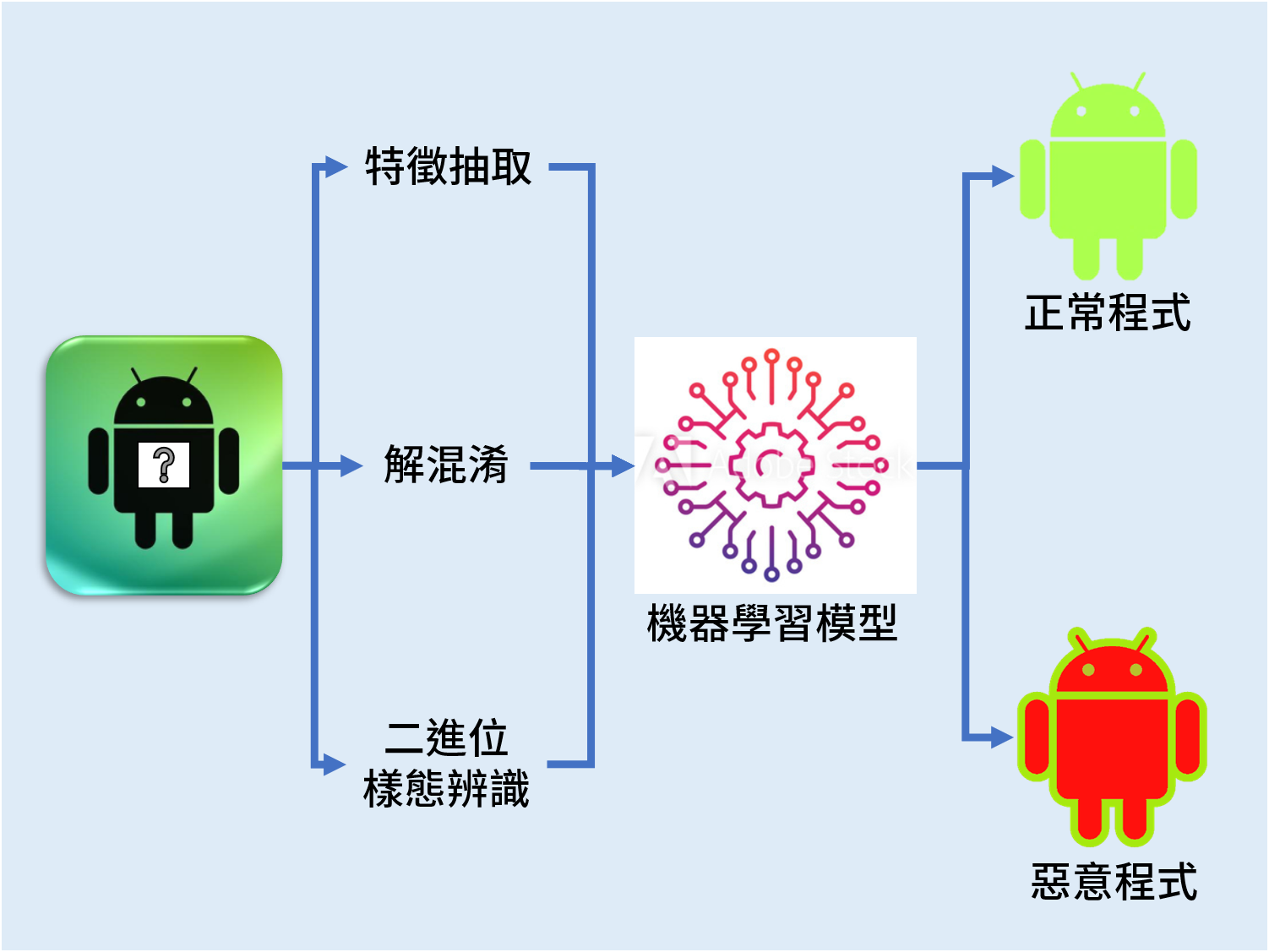
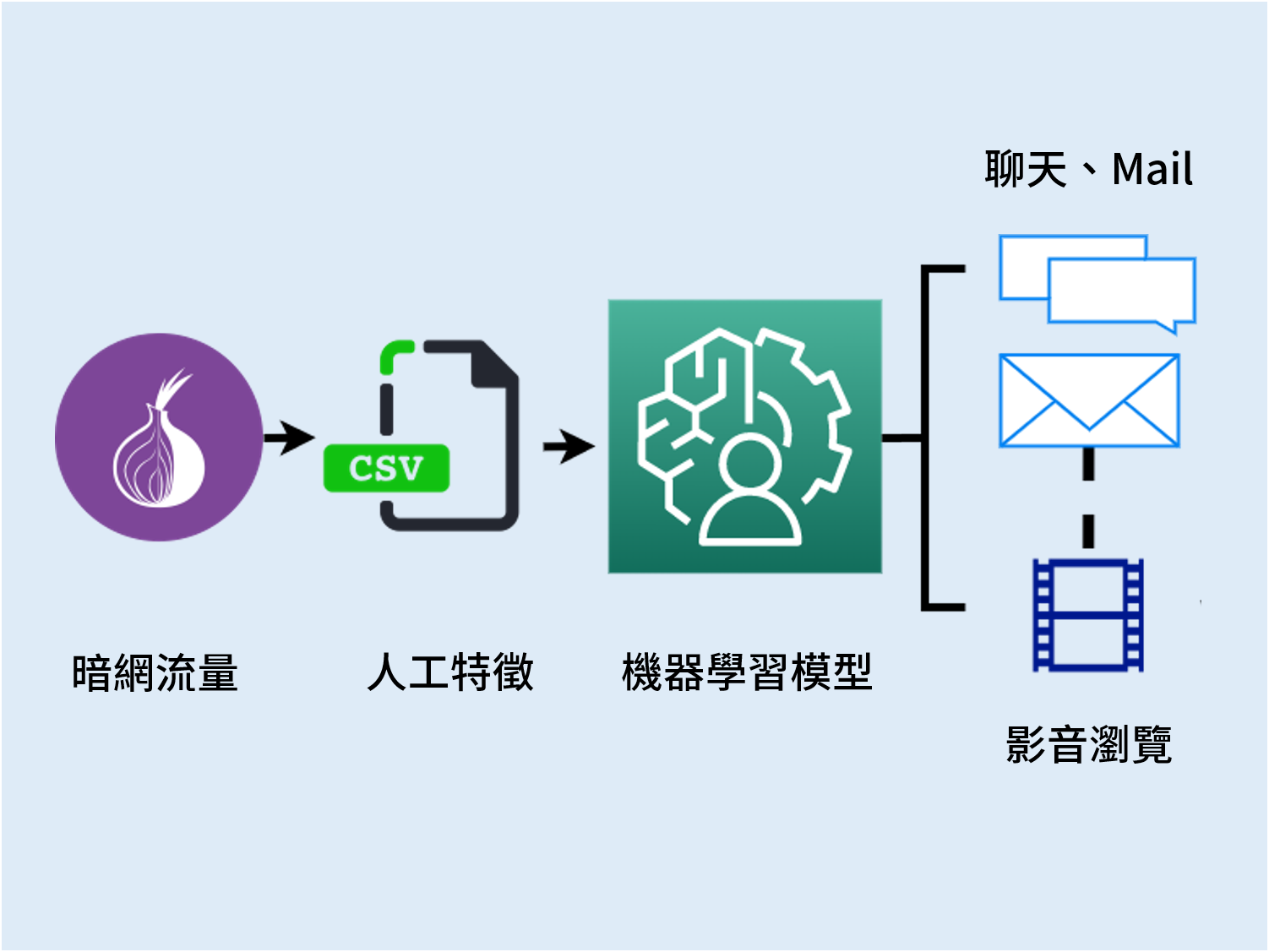
雖然無法做到百分之百滴水不漏,但為了知已知彼,研究團隊更直搗黃龍,「潛水」暗網蒐集情資,分析駭客行為特徵。林宗男表示,駭客為了躲避追蹤,都在暗網活動,因為透過 TOR 瀏覽器加密,網管人員無法辨識使用者到底是在上網聊天、傳資料、發送 Email,還是看 YouTube 聽音樂或追劇等。對追蹤技術研究者而言,到暗網觀察駭客「水面下」的活動,是很重要的情資來源。
研究團隊透過 AI 研究分析已知惡意程式的網路行為特徵,再側錄蒐集暗網不同使用者上傳流量與行為模式,找出「壞人經常走的路徑」,把暗網流量做善惡分類,研判哪些是正常上網行為,哪些是惡意程式發動攻擊。林宗男舉例,就像防疫期間每個人都戴著口罩,但年紀大的和年紀輕的行為就是不一樣,「我們就是利用 AI 從行為特徵分辨使用者上網行為是否正常。」
研究成果經與美國 IBM 和中華電信合作驗證測試,辨識率高達 99.6%,遠超過加拿大研究團隊的 81.6%。對 ISP(網路服務供應商)而言,若能明確辨識暗網流量分類,就不必把看影片或聽音樂等受到惡意攻擊可能性極低的影音串流,全部導入 IDS(入侵檢測系統)資安偵測,大幅節省資源。
惡意流量偵測,鞏固第 2 道防線
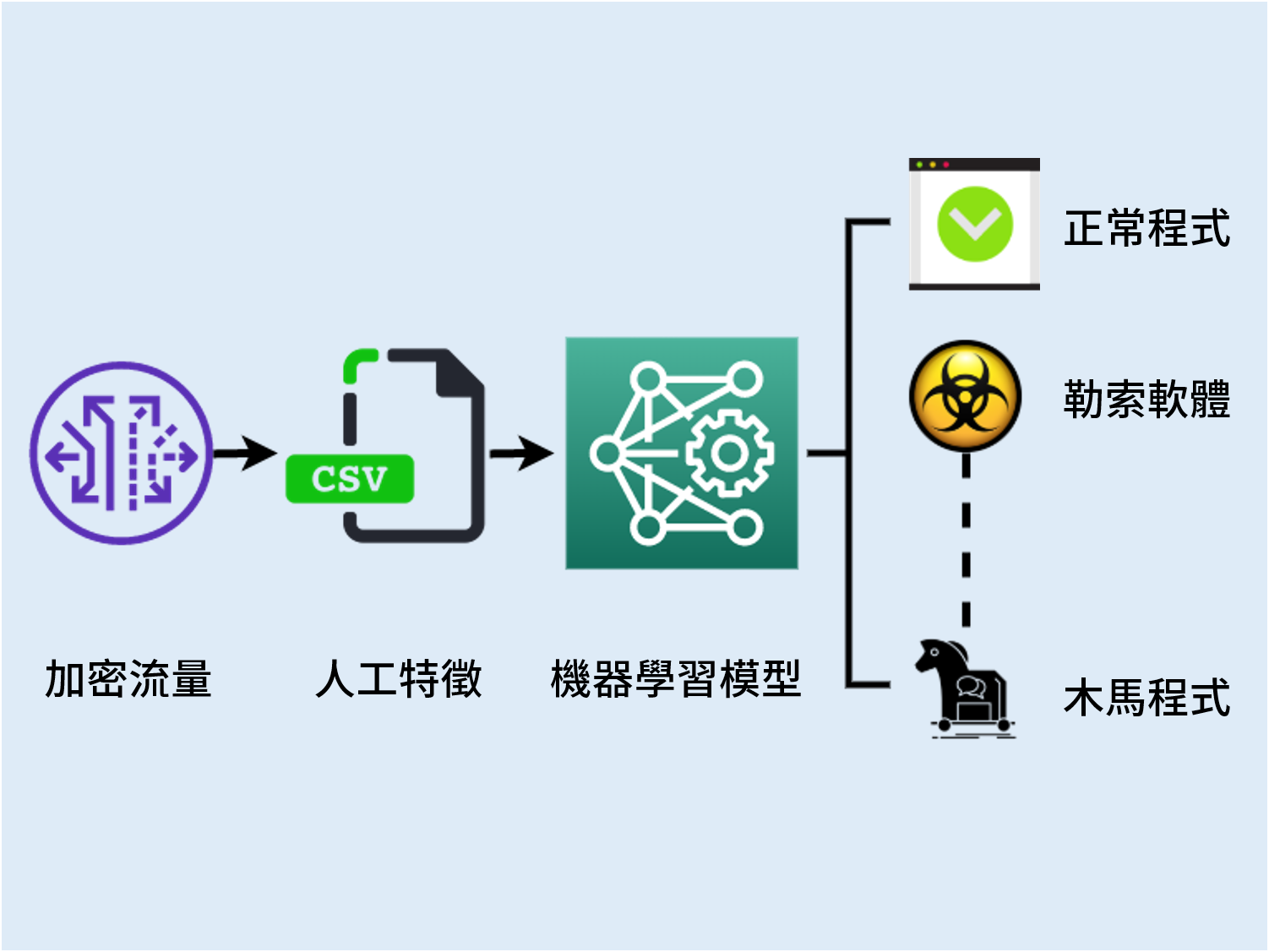
研究團隊也利用最近 3 年眾所周知的 10 種惡意程式,包括 2017 年肆虐全球的勒索軟體 WannaCry(想哭)進行惡意流量偵測「實兵演練」。畢竟惡意程式偵測不可能做到百分之百,漏網之魚在所難免。根據資安調查顯示,惡意程式滲透入侵電腦系統之後,平均長達 56 天才會被發現。
「惡意流量偵測其實是第 2 道防線!發生惡意流量代表電腦已經中毒了,我們的目標是在最短時間偵測出惡意流量。」林宗男透露,跨國網路科技公司 CISCO 現有商用偵測系統精確度已達 97.7%,「我們做得再好,也僅能微幅提升到 98.2%。」研究團隊再發揮 3 個臭皮匠勝過 1 個諸葛亮的精神,把 2 套系統截長補短,將精確度再向上提升 0.3%,堅持沒有最好、只有更好的信念,鍥而不捨地挑戰不可能的任務。
eID 的潛在風險
然而,林宗男也深知,資安不可能做到百分之百的絕對安全。當內政部決定在明年全面換發 new eID 數位身分證,建置 T-Road(政府資料傳輸平臺),打造跨政府機關資料通道網路,推動「一卡多用」串聯戶籍資料、健保資料庫、汽機車駕照交通監理資料、國民年金與勞保勞退年金等,同時政府也將讓 new eID 擁有線上交易完整性與不可否認性,做為電子商務交易憑證。林宗男對此呼籲政府應正視 new eID 缺乏法源依據的問題,更要從資訊安全的角度,重新審慎評估全面換發數位身分證的必要性。
「透過 new eID 建置 T-Road 聽起來好像很方便、很進步,但對駭客而言,要偷取全國 2,300 萬人的資料,也非常方便。一旦出現資安破口,整個系統就會因單點失效而全面瓦解。」林宗男說,「new eID 把國人從出生到死亡所有資料全部放在 T-Road,我們都知道網路沒有絕對安全,還要把所有的東西全部放在一個籃子裡面嗎?」政府應該要有分散風險的危機意識,數位身分證絕對不能「一卡多用」。
註解
- 利用 TOR(The Onion Router 洋蔥路由器)瀏覽器遮蔽使用者真實位址,避開網管系統追蹤的匿名網路。
- 參考人類大腦視覺組織建立的深度學習模型。






































