你聽過「量子意識」嗎?電子雙狹縫實驗讓人猜測意識會影響物質世界,真的假的?

在市面上,我們常會看到號稱運用量子力學原理的商品或課程,像是量子內褲、量子能量貼片、量子首飾、量子寵物溝通、量子速讀、量子算命、量子身心靈成長課程等等。有人說,量子力學代表了意識具有能量,藉由調整心靈的共振頻率,就能保持身心健康,只要你利用量子力學原理進行療癒或冥想,就能提昇自己的能量,人能長高、身體變壯、每次考試都考一百分;又像是,量子力學就代表一種信息場,讓你跟別人有心電感應,只要轉念,讓宇宙能量幫助你,你就能發大財還能避免塞車。也有人說,別人吃一個下午茶,你也馬上吃一個下午茶,別人喝一杯咖啡,你也馬上喝一杯咖啡,別人跟家人吵架,你也馬上找一件事跟家人吵架,這就是量子糾纏。
然而,量子到底是什麼?跟身心靈、宗教和玄學真的扯得上關係嗎?是否真能幫助你維持健康又賺大錢呢?
在這一系列影片裡,我們就要來討論,量子力學的原理為何?背後又是基於哪些科學的研究成果。等你看完之後,相信對於量子力學跟上述五花八門商品究竟有沒有關係,心裡自然會有所答案。
量子力學和意識有關?
坊間常會聽到量子力學跟意識有關的說法;或許也是因為這樣,量子力學被許多身心靈成長課程甚至玄學拿來作為背書。但,量子力學真的是這樣子嗎?
說到量子力學跟意識的關係,我們就必須來看看,量子力學最著名的實驗之一,20 世紀的物理學大師費曼(Feynman)甚至曾經說過,這個實驗「包含了量子力學的核心思想。事實上,它包含了量子力學唯一的奧秘。」它,就是雙狹縫干涉實驗。
雙狹縫干涉實驗
現在我拿的器材,上面有兩道狹縫,中間間隔了非常短的距離。等一下,我們會讓雷射光通過這兩道狹縫,看看會發生什麼事。
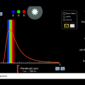
我們看到,雷射光在打向雙狹縫之後,於後面的牆上呈現有亮有暗的條紋分布,這跟我們在國、高中學過的波的性質有關。
在兩道光波的波峰相會之處,會產生建設性干涉,即亮紋的位置;而暗紋的部分,則是來自破壞性干涉,是兩道光的波峰和波谷交會之處,亦即,光的效應被抵銷了。
在歷史上,雙狹縫干涉實驗占有非常重要的地位。19 世紀初,英國科學家、也是被譽為「世界上最後一個什麼都知道的人」的湯瑪士.楊(Thomas Young),利用雙狹縫實驗,證明了光是一種波。
那麼,如果我們拿不是波的東西,來進行雙狹縫實驗,會看到什麼結果呢?讓我們試驗一下。
現在我手邊有一堆的彈珠,前面是用紙板做成的兩道狹縫,後面則是統計彈珠落點的紙板。我們讓這些彈珠朝狹縫的地方滾過去,並在彈珠最後的落點劃下記號;若在同樣位置的記號越多,就代表有越多彈珠打中該位置。
在丟了一百顆彈珠之後,我們可以看到,扣除掉一部份因為路徑被擋住、通不過狹縫的彈珠之外,彈珠最終抵達的位置,大致分別以兩道狹縫的正後方為最多,呈現兩個區塊的分布,不像先前光的雙狹縫干涉實驗中,出現明暗相間的變化。
所以,我們得到結論:若是拿具有物理實體的東西進行雙狹縫實驗,因為其一次只能選一邊通過,所以落點最終只會聚集在兩個狹縫後方的位置;而且要是行進的路徑不對,還可能會被擋住。
至於波的情形,那就不同了,只要狹縫的大小適當,波可以同時通過兩個狹縫,並互相干涉,產生明暗相間的條紋。
換言之,是波,還是物質,兩者在雙狹縫實驗的表現是截然不同的。
只不過,以上的實驗似乎並沒有什麼太令人感到意外的地方,我們也看不出來,它跟量子,還有意識,到底有什麼關係?事實上,若要真正顯示出它的獨特之處,就要來看電子的雙狹縫干涉實驗。
電子的雙狹縫干涉實驗
我們知道,電子是組成原子的基本粒子之一,而原子又組成了世間萬物。可以說,電子是屬於物質的一種極微小粒子。
在電子的雙狹縫干涉實驗,科學家朝雙狹縫每次發射一顆電子,並在發射了很多顆電子之後,觀察電子的最終落點分布會怎麼呈現。
既然電子是物質的微小粒子,那麼在想像中,應該會跟我們前面使用彈珠得到的結果差不多,電子會分別聚集在兩道狹縫後方的區域。
從實驗的記錄影片中可以看到,在一開始、電子數量還很少的時候,其落點比較難看得出有明顯規律,但隨著電子的數目越來越多,我們慢慢能夠看出畫面上具有明暗分布,跟使用光進行雙狹縫實驗時得到的干涉條紋,有著類似的結構。
這樣的結果,著實令人困惑。直覺來想,既然電子是一顆一顆發射的,它勢必不可能像光波一樣,同時通過兩個狹縫,並且兩邊互相干涉,產生明暗相間的條紋。
但無可否認,當我們用電子進行雙狹縫實驗時,最後得到的結果,看起來就跟干涉條紋沒什麼兩樣。
對這出人意表的觀測結果,為了搞清楚發生什麼事,科學家又做了更進一步的實驗:
在狹縫旁放置偵測器,以一一確認這些電子到底是通過哪一個狹縫、又如何可能在通過狹縫後發生干涉。
這下子,謎底就能被解開了――正當大家這麼想的時候,大自然彷彿就像在嘲笑人類的智慧一樣,反將一軍。
科學家發現,如果我們去觀測電子的移動路徑,只會看到電子一顆一顆地通過兩個狹縫其中之一,並最終分別聚集在兩個狹縫的後面――換言之,干涉條紋消失了!
在那之後,科學家做過無數類似的實驗,都得到一樣的結果:只要你測量了電子的路徑或確切位置,那麼干涉條紋就會消失;反過來說,只要你不去測量電子的路徑或位置,那麼電子的雙狹縫實驗就會產生干涉條紋。
在整個過程中,簡直就像是電子知道有人在看一樣,並因此調整了行為表現。
在日常生活中,若有人要做壞事,往往會挑沒人看得到的地方;反過來說,當有其他人在看,我們就會讓自己的言行舉止符合公共空間的規範。
量子系統也有點像這樣,觀測者的存在與否,會直接影響到量子系統呈現的狀態。
只不過,這就帶出了一個問題:到底怎麼樣才算是觀測?如果我們在雙狹縫旁邊只放偵測器不去看結果算嗎?我們不放偵測器只用肉眼在旁邊看算嗎?或是,整個偵測過程沒有人在場算嗎?
這就是量子力學裡著名的觀測問題(measurement problem)。
結語
在量子力學剛開始發展的數十年,有許多地方都還不是那麼清楚,觀測問題就是其一。在歷史上,不乏一些物理學家,曾經認真思考,是否要有「人的意識」參與其中,才能代表「觀測」。
如果真是這樣的話,那麼「意識」就存在非常特別的意義,而且似乎暗示人的意識能夠改變物質世界的運作。
 有一些物理學家曾認真思考,是否要有「人的意識」參與其中,才能代表「觀測」。圖/envato
有一些物理學家曾認真思考,是否要有「人的意識」參與其中,才能代表「觀測」。圖/envato
可以想見地,上述出自量子力學觀測問題的猜測,後來受到部分所謂靈性導師跟身心靈作家的注意,於是,形形色色宣揚心靈力量或利用量子力學原理進行療癒、冥想或身心靈成長的偽科學紛紛出籠,直到近年都還非常流行。
另一方面,可能因為量子兩個字帶給人一種尖端科學的想像,坊間琳瑯滿目的商品即使跟量子力學一點關係都沒有,也都被冠上量子兩字;除此之外,商品宣傳裡也常出現一堆量子能量、量子共振等不知所謂的概念,不然就是濫用量子力學的專有名詞如量子糾纏、量子穿隧等,來幫自己的商品背書。只要有量子兩字,彷彿就是品質保證,讓你靈性提升、身體健康、心想事成。
對此,我就給三個字:敢按呢(Kám án-ne)?
事實上,量子力學至今仍是持續演進的學問,我們對量子力學的理解也隨時間變得越來越豐富。現代的物理學家,基本上不認為我們可以用意識改變物質世界,也不認為「意識」在「觀測」上佔據一席之地,甚至可以說正好相反,人的意識在觀測上根本無關緊要。
不過,我們不會那麼快就直接進入觀測問題的現代觀點。在之後接下來的幾集,我們會先從基本知識開始說起,循序漸進,讓你掌握量子力學的部分概念。而在本系列影片的最後一集,我們才會重新回到觀測問題,並介紹量子力學領域近幾十年來在此問題上獲得的進展。
歡迎訂閱 Pansci Youtube 頻道 獲取更多深入淺出的科學知識!


 因為答應了要在M.I.C. II分享「意識」這個主題,開始蒐集彙整資料,當然沒有辦法忽略七月份一群科學家們簽署的劍橋意識宣言(The Cambridge Declaration on Consciousness)。關於宣言的中文說明請參考這裡,美國的科學人雜誌也有一篇相關的報導。
因為答應了要在M.I.C. II分享「意識」這個主題,開始蒐集彙整資料,當然沒有辦法忽略七月份一群科學家們簽署的劍橋意識宣言(The Cambridge Declaration on Consciousness)。關於宣言的中文說明請參考這裡,美國的科學人雜誌也有一篇相關的報導。