




文/徐伯瑋
「每隻螞蟻,都有眼睛鼻子,它美不美麗?偏差有沒有一毫釐?有何關係?」
—《王菲‧開到荼蘼》
一般人往往覺得螞蟻的長相沒什麼差異,不過看在昆蟲分類學家的眼裡,可以「相差大過天地」。
2015 年秋季,我和森林遊憩課程的同學一同來到了南投縣進行兩天一夜的參訪。臨走之前,我從一處邊坡上挖了最後一袋土壤樣本之後便匆匆地回到小巴士上,準備返回台北。
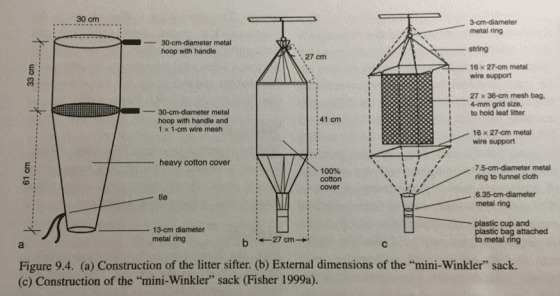
落葉袋採集法(Winkler extraction)是一種採集底棲無脊椎動物的方法,也是目前調查螞蟻種類最有效的方法之一:將一處土壤帶回來之後,放入一個類似洗衣袋但網目較大的袋子裡,再將它掛入另一個底部裝有酒精收集瓶的大布袋之中。由於過程中的擾動以及隨後土壤緩慢地乾燥,裡頭各式各樣的生物便會開始往外跑,最後掉入酒精瓶中。
(小蟲蟲:塊陶阿!)
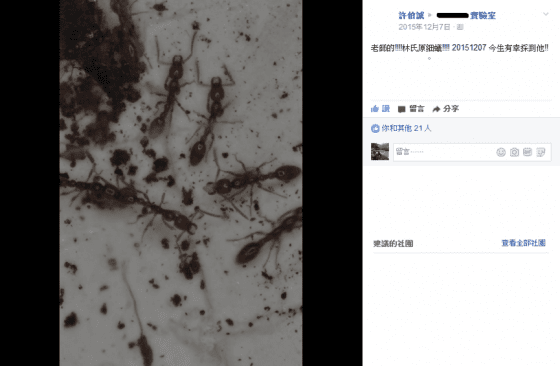
落葉袋懸掛了一周之後,我從那千里迢迢帶回來的樣本中找到了一隻小螞蟻。在用顯微鏡檢查之後我赫然發現,似乎這隻螞蟻與幾天前彰師大實驗室的許伯誠學長貼在臉書社團中的一種罕見的螞蟻有幾分神似。當時發現的是一整巢罕見的林氏原細蟻(Protanilla lini),除了新種發表時的樣本之外,這種螞蟻已經有近二十年沒有採集紀錄。而我採集到的這隻螞蟻看外貌是種原細蟻,然而牠的腰節卻與林氏原細蟻有明顯的不同。
再更進一步與螞蟻資料庫比對之後,我發現這隻螞蟻果然與世界上其他的原細蟻(不到十種)也都有顯著的不同,因此更確信牠為一個未曾被描述過的種類。此時,我便開始著手進行收集更多的研究材料。
模式標本是物種命名不可或缺的一部分。分類學家除了要選定唯一一隻標本作為正模式(Holotype)來乘載該物種的名稱,也可以指定其它標本做為副模式(Paratype),用以代表物種內的型態差異。
螞蟻屬於社會性昆蟲,除了不同隻工蟻本身就會有的差異之外,不同階級之間,像是蟻后與工蟻的差異甚至會更大(沒錯,這已經相差大過天地了)。因此若是能採集到更多的工蟻以及其它不同階級的螞蟻來比對,那對新種的描述以及未來的研究將會有非常大的幫助。
為此,隔年三月,我們在許伯誠學長的幫忙下,於同一地點採集到了一巢完整的新種螞蟻聚落,其中包含了珍貴的蟻后。綜合以上述材料,我們整理了臺灣原細蟻屬這兩個種類的分類及生態資料,提供工蟻和蟻后的型態描述與圖片、世界上已知工蟻的檢索表、以及生物學觀察,並將此研究發表在動物學分類《Zootaxa》中。
現今世界上共有 12 種已描述的原細蟻。和其它已知的細蟻亞科成員一樣,牠們的工蟻沒有眼睛,被認為長久居住於土壤之中,鮮少在地表活動,並專門以蜈蚣為食。除了和其它大多數螞蟻一樣擁有可癱瘓獵物的螫針,原細蟻還具有類似於顎針蟻 (Anochetus)或鋸針蟻(Odontomachus)的陷阱式大顎(trap-jaw),這種大顎就像捕獸夾一樣,會在獵捕或警戒時打開至180度,等遇到目標時再快速合起,緊抓住獵物或敵人。
臺灣目前的 2 種原細蟻,包含了 2009 年寺山先生所發表,以採集者林宗岐教授為名的林氏原細蟻,以及本研究首次描述的新種,鍾氏原細蟻(P. jongi)。這個名字紀念帶領我開始研究螞蟻的鍾兆晉老師,並且剛好能讓他與認識多年的好友林宗岐教授以特殊的方式一同留名。

除了新種之外,還記得剛才提到鍾氏原細蟻那個引起我注意的腰節特徵嗎?這個非典型的原細蟻特徵,其實與中國的叉齒細蟻屬 (Furcotanilla)極為相似。因此藉由我們在鍾氏原細蟻這個新種所發現到的,介於原細蟻與叉齒細蟻的形態資訊,我們便能理解到原細蟻屬內特徵的變異範圍。
幾經考慮,我們最後認為叉齒細蟻屬應該定位成原細蟻屬內的一個特化支系,最後將其視為原細蟻屬的同物異名(synonym)。我想這樣一個簡單的研究案例,也彰顯出了現代基礎分類學的重要性。因為每一個演化支系的發現,都能幫助我們對整個類群有進一步的了解。
故事自此,相信客倌您已經知道王菲是錯的。螞蟻的眼睛鼻子真的真的很重要,而且你還會發現不是每隻螞蟻都有眼睛的。不過話又說回來,「螞蟻的鼻子」這個東西,到底該怎麼定義呢?
參考資料
- Hsu PW., Hsu FC., Hsiao Y., Lin CC. 2017. Taxonomic notes on the genus Protanilla (Hymenoptera: Formicidae: Leptanillinae) from Taiwan. Zootaxa 4268 (1): 117–130
- Agosti D., Majer JD., Alonso LE., Schultz TR. 2000. Ants – Standard methods for measuring and monitoring biodiversity. Smithsonian Institution Press, Washington, D.C.
- 此文由徐伯瑋撰寫,響應 PanSci 「自己的研究自己寫」,以增進眾人對基礎科學研究的了解。






























