


作者:潘人豪助理教授,元智大學大數據與數位匯流創新中心
最近時常帶著來台灣受訓考察的外國朋友,到國內大型醫院做數位化醫院的介紹與教學。當中最讓人感到有趣的,就是這些來自發展中國家的朋友們,對台灣高度資訊化的醫療現場、醫院流程總是處處充滿著驚奇與讚嘆,但這些資訊化的醫院程序,對於居住在台灣的我們來說,彷彿理所當然般的熟悉,但,我們是否有曾經思考過,這些再普遍不過的醫院就醫流程,到底是怎麼發生在我們身活的周遭裡呢?

不知你是否曾想過,當你到醫院看病時,必須與所有病人擠在鐵閘門外彷彿沙丁魚罐頭般毫無秩序的等待著自己名字被呼喊,而醫生則彷彿珍奇異獸般在那保護周密的籠子裡幫人看診。不知你又是否能想像,當醫生要求你要拍攝 X 光片或檢驗時,你必須等到「改天」再回來「戶外」的放射間拍攝,隨後「改天」自行回來找你的 X 光片後,再「改天」重新化身沙丁魚回診讓醫生幫你看片做診斷,而這手沖的 X 光片,並沒有人會幫你分類保管,而是要你自己好好地攜帶保存,更不用說醫院會保存那屬於你的病歷資料。而這些才是屬於當地人們理所當然的日常生活。

在世界名列前茅醫療資訊高度發展的台灣,看診時從網路掛號、候診順序、診間病歷調閱、醫師醫令、處方開立,一直到放射影像存取、檢查檢驗資料儲存等等,無數的數據資訊悄悄的在我們沒有注意的時候在醫院各個角落中傳遞、交換、儲存,在你拍完 X 光片還沒走回診間時,X 光設備便已經透過光纖將你的資料送達儲存在資訊機房設備中,當你返回醫師診間時,醫生便能透過診間電腦進行調閱診斷。同時,大多數你的生理檢驗資訊,同樣的在你回診時得以從電子病歷中檢索。這些我們感覺理所當然資訊處理,在發展中國家甚至需要一個月時間才能完成所有步驟,但在台灣我們只要一天甚至一個早上便達成了!
這一切正是仰賴醫學資訊分析的與醫療大數據交換處理。醫學大數據的產生,主要歸功於醫療設備數位化及電子化病歷發展兩大領域的突破,透過儀器數位化(如放射設備、檢驗設備與電子訊號儀器等),醫院得以獲得更多病人疾病與健康資訊紀錄。然而在病人醫療診斷上,為了妥善紀錄病患個人資料、診斷資料與過往醫療紀錄、照護紀錄與前面提及的放射、檢驗結果等,即促成了電子病歷系統發展。
電子病歷的發展由過去由紙張紀錄抄寫、早期的數位化紀錄病人個人資訊、生理數據與疾病健康資訊紀錄的電子健康資訊系統(electronic health record,EHR),一路發展至目前國內醫療院所普遍使用,醫師可於診斷時在診間電腦進行病歷、檢查檢驗、放射影像數據等資料調用的病歷資料電腦化系統(computerized medical records,CMR),再到目前當紅發展,藉由設備間共通協定進行資料的交換串接,實現自動資訊蒐集的醫療記錄自動化系統(automated medical record,AMR),如自動化檢驗設備流程平台、移動護理資訊系統等等透過電腦自動化數據傳輸將檢體檢驗數據結果或是病人生理資訊,自動將該檢體與病人條碼自動配對與結果回傳儲存,取代以往的人工抄寫輸入流程。
醫學大數據發展的軌跡由過去紙張記錄、紙本資訊數位化、醫學紀錄儲存到現今多資訊整合,其數據量驚人的成長,不僅由過去個人社經資訊、診斷資訊等文字媒介,更擴展到多媒體影像資訊(X 光影像、高解析靜態影像)、動態視訊影像資訊(如磁振造影(magnetic resonance imaging, MRI)動態影像檔、內視鏡攝影)以及電訊號資訊,如心電圖(Electrocardiogram, EKG / ECG)、腦波訊號(Electroencephalography, EEG)等等,這些龐大醫學數據的彙集與高度整合技術能力,正是台灣醫學資訊發展超群的主因,同時更顯見醫學數據發展的多元應用與其重要性。

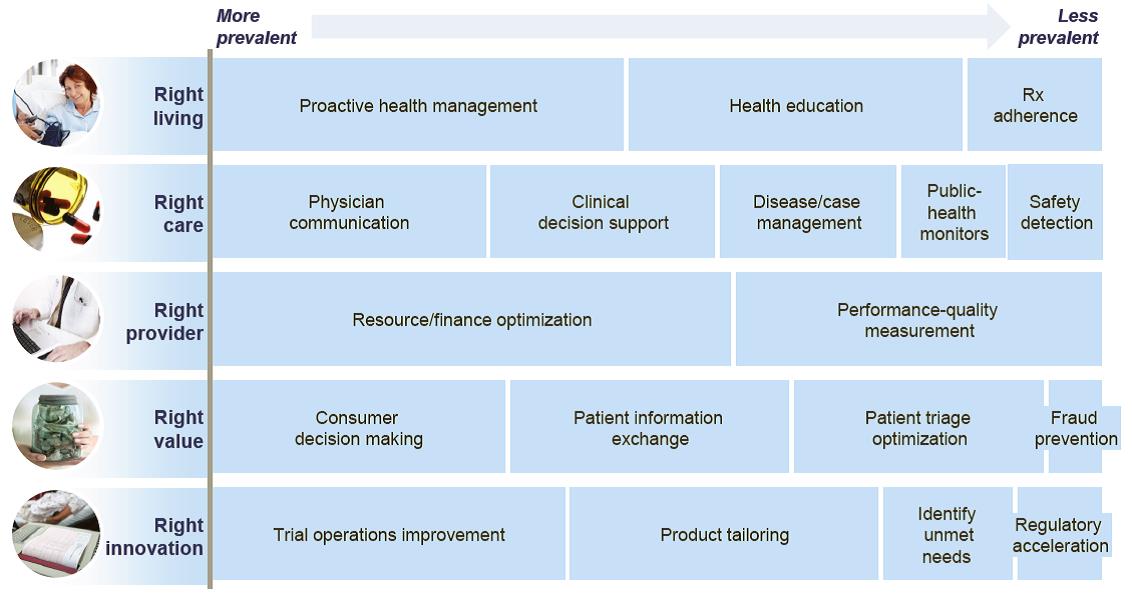
當今醫學大數據的發展趨勢,架構在臨床、非臨床、放射、檢驗、公共衛生以及醫療保險各領域之資訊彙整上,所衍生之各種分析、整合技術與服務,我們可以從麥肯錫公司(McKinsey & Company)於 2013 年所發表的 The “big data” revolution in healthcare 趨勢報告了解,未來醫學大數據發展及應用所朝向的五個目標,將鎖定在提供人們更佳的生活品質(Right living)、更安全的醫療照護(Right care)、更具水準的醫事人員(RIght provider)、產出更高醫療價值與降低醫療成本(Right value)以及更多創新(Right Innovation)醫療應用,其含括層次包含個人、醫事工作者、醫療單位、設施以及公共群體、政府政策與國際健康衛生,由下至上皆直接受惠於醫學大數據應用之發展,就像目前當紅的健保資料庫加值應用、穿戴式裝置的個人健康管理、遠距照護的資訊傳遞、個人保健雲,許許多多的創新應用都說明了醫學大數據未來的重要性與發展潛力。
在百花齊放的醫學大數據應用中,最後我們可以稍稍反思一下,依據 2012 年 10 月實施之新版個資法規範,如何確保隸屬於極端隱私的個人醫療資訊於大數據計算載體間傳遞並且符合個人資料保護原則、資料歸屬權與道德隱私等議題,相信會是未來醫學大數據發展的另一波衝擊與探討重點。當我們在享受就醫的便利與各種個人健康數據管理裝置、軟體的介入下,你是否開始認識自我資訊隱私的安全保護呢?
醫學大數據小辭典:
- 醫學影像存檔與通信系統(Picture archiving and communication system,PACS):在過去紙本化醫療紀錄制度中,影像資料如X光片、電腦斷層掃描(CT)、核磁共振(MRI)、超音波影像,僅能由專業儀器或是直接沖洗底片才得以讓醫師進行觀察與診斷。因此病例管理便顯得特別重要,因為若無法有效檢索,影像底片自然無處可尋。因此在許多開發中國家,甚至採用膠片讓病患自行帶回的方式,自行管理以避免資料丟失。但在PACS系統的發展後,透過數位化影像擷取技術將過去需要做底片沖洗的過程直接以數位化方式取代,並採用網路進行存取,醫事人員得以在診間,甚至病床端直接進行影像分析與診斷,更避免了過去實體文件儲存所花費的高額成本。(資料來源:潘人豪助理教授,元智大學大數據與數位匯流創新中心)
- 電子病歷 (Electronic medical records,EMR):紙本化手寫病歷是醫發展重要工具之一,透過對病況的紀錄與編撰,醫事人員得以瞭解該病患的疾病歷史、生理、心理狀況等資料,因此在醫師的訓練過程中,如何客觀評估病人狀態並給予正確診斷、處置並紀錄於病歷中,便是一門大學問,也因此發展出所謂的SOAP ( Subject, Objective, Assessment, Plan)紀錄方法。然而在醫院規模的成長,病歷的管理、儲存與調閱便越顯困難,在許多開發中國家甚至因為無法有效儲存,導致每次的看診都需重覆建檔,因而造成病人的醫療品質低落。而電子病歷便是因此而發展出,透過電腦建檔,電子病歷便可以在電子載體中儲存、複製與傳輸,更不會受限於紙本調閱在空間與時間上造成的成本耗損,醫事人員可以在醫院內任何受權存取的電腦或設備上進行讀取(前提是經過身份核準),而當下的電子病歷更大幅擴展到包含實驗室資訊、檢查報告、數據、護理紀錄,生命徵象紀錄,藥物使用記錄等等,將病人的疾病資料更加完整的整合,以提供醫師更精確的疾病資料以維持醫療品質與病人就醫安全。(資料來源:潘人豪助理教授,元智大學大數據與數位匯流創新中心)
想了解更多大數據知識,歡迎訂閱元智大學大數據匯流電子報創刊號




































-2-497x628.jpg)




