

本文轉載自中央研究院「研之有物」,為「中研院廣告」
- 採訪撰文|莊崇暉、田偲妤
- 責任編輯|田偲妤
- 美術設計|蔡宛潔
不要再轉傳假訊息了!
「我家親戚群組又在 LINE 傳假訊息了!」這是常在年輕族群中聽到的抱怨,彷彿隨意散播謠言是長輩特有的行為,當你願意了解長輩的數位社交生活,將發現事實並非如此。中央研究院「研之有物」專訪院內民族學研究所李梅君助研究員,在研究 Cofacts 事實查核協作計畫時發現,臺灣民眾對公共議題的關注存在世代衝突,該衝突延伸至日常相處上,卻在事實查核的協作過程中看到正向溝通的曙光。究竟臺灣長輩發展出什麼樣的數位社交生活?如何應用第三方資訊與長輩溝通,甚至邀請長輩加入闢謠打怪行列?

2018 年臺灣地方選舉和公民投票讓存在已久的世代衝突瞬間引爆,面對韓流現象、同性婚姻、性平教育等議題,厭世代年輕人(1990 年代左右出生)和戰後嬰兒潮世代長輩(約 1946-1964 年出生)因經濟與社會生長背景的不同,常發生意見分歧而爭吵不休的情形。
在臺灣最多人使用的 LINE 即時通訊軟體中,出現不實謠言滿天飛的亂象,年輕人紛紛將矛頭指向長輩,批評長輩不先查核資訊真假就亂發文。
中研院民族所李梅君助研究員在研究 Cofacts 事實查核協作計畫時,發覺臺灣世代衝突問題的嚴重性。年輕人認定長輩就是假訊息的傳遞者,但事實上,許多年輕人也常在無意間互傳不實謠言。
「大眾常急著為長輩貼標籤,卻從來不去了解他們怎麼使用數位工具。這樣並無助於解決問題,只會加深彼此的誤會。」研究過程中逐一浮現的問題為李梅君指引出一條研究道路,從事實查核協作行動出發,逐步深入長輩的數位社交生活,探索緩解世代衝突、提升全民媒體素養的可能途徑。
「早安圖」的背後:長輩獨特的數位社交

從了解長輩的數位社交生活做起,應有助於促進不同世代的相互理解,李梅君選擇由長輩們發展出的「早安圖」文化來切入研究。
科技與生活的緊密結合讓人手一機成為常態,再加上疫情造成的人群接觸減少,讓人們日漸習慣將社交重心從實體轉往線上。越來越多長輩靠 LINE 群組維繫親友感情、接收外界資訊,每天一早發布的「早安圖」經常是長輩社交生活的起頭。
然而,早安圖一直有被汙名化的傾向,溫馨圖片配上吉祥文字的簡單排版被貼上具有長輩風格的標籤,甚至還被戲稱為「長輩圖」。李梅君與長輩相處後發現,早安圖的存在對於長輩的社交生活具有深刻意義。
首先,早安圖是長輩證明自己跟的上年輕人腳步的重要象徵!身為晚近才接觸手機、電腦的「數位移民」,長輩常因不會操作數位工具、又害怕晚輩覺得自己笨拙,而感到焦躁不安。因此,當自己好不容易學會用手機拍照、修圖、發早安圖,對長輩來說是自信心的累積,代表自己沒被時代淘汰。
此外,早安圖也是長輩與人互動的敲門磚。李梅君察覺,有些長輩在傳訊息時相當在意社交分寸,不像年輕人想到什麼就 LINE 一下朋友,反而擔心隨意發文會被當成不懂規矩的「老人」。因此,當與新朋友開啟話題時,他們會先禮貌性地試探,這時無害的早安圖就是最好的敲門磚,可以從對方回傳的字句、貼圖或已讀不回,判斷能否進一步交談。
如果我們願意深入體會早安圖對長輩的意義,你將發現早安圖是長輩表達「關懷」的重要媒介。
例如在不方便見面的疫情期間,許多長輩會互相分享充滿溫馨祝福的早安圖、早安短影片,當中包含一些身體保健資訊,即時表達對遠方親友的關心,也讓對方知道自己過的很好。
但是,伴隨著早安圖的問候,群組裡轉傳的文字與圖像影片卻可能含有具爭議性的農場內容,例如每天喝檸檬水可以防疫、常喝地瓜葉牛奶可以防癌等,讓以關懷為出發點的長輩成為散播謠言的代罪羔羊。為此,有越來越多公民團體開始號召民眾一起打擊假訊息,李梅君研究的 Cofacts 就是其中一個針對 LINE 假訊息亂象所發展的計畫。
聽到外面的聲音:「事實查核協作社群」打開群組封閉的大門

圖/Unsplash
LINE 假訊息亂象一直是假新聞議題中非常難處理的一塊,因為 LINE 不像 Facebook、Twitter 或 Instagram 有審查下架機制,LINE 聊天室裡所有的對話都經過加密,就算檢舉了某用戶的言論,LINE 官方也難以遏阻資訊傳播。
李梅君提到:「雖然 LINE 群組相當封閉,在臺灣卻已具有極大的公共性。」很多群組都涉及公共議題的討論,並累積千百人以上的成員,一旦有人惡意散播不實謠言,在缺乏查核機制的情況下,後果可能不堪設想。
因此,自 2016 年起,公民科技社群 g0v 臺灣零時政府的成員推出「Cofacts 真的假的 – 訊息回報機器人與查證協作社群」,邀請民眾主動回報在 LINE 上發現的可疑訊息,再由來自各領域的編輯志工進行事實查核,撰寫有助判斷訊息真假的回應。之後只要有民眾發出相似問題,機器人便會從資料庫中找出相關回應供民眾參考。收到回應的民眾如有不同看法,也可以補充新的回應。
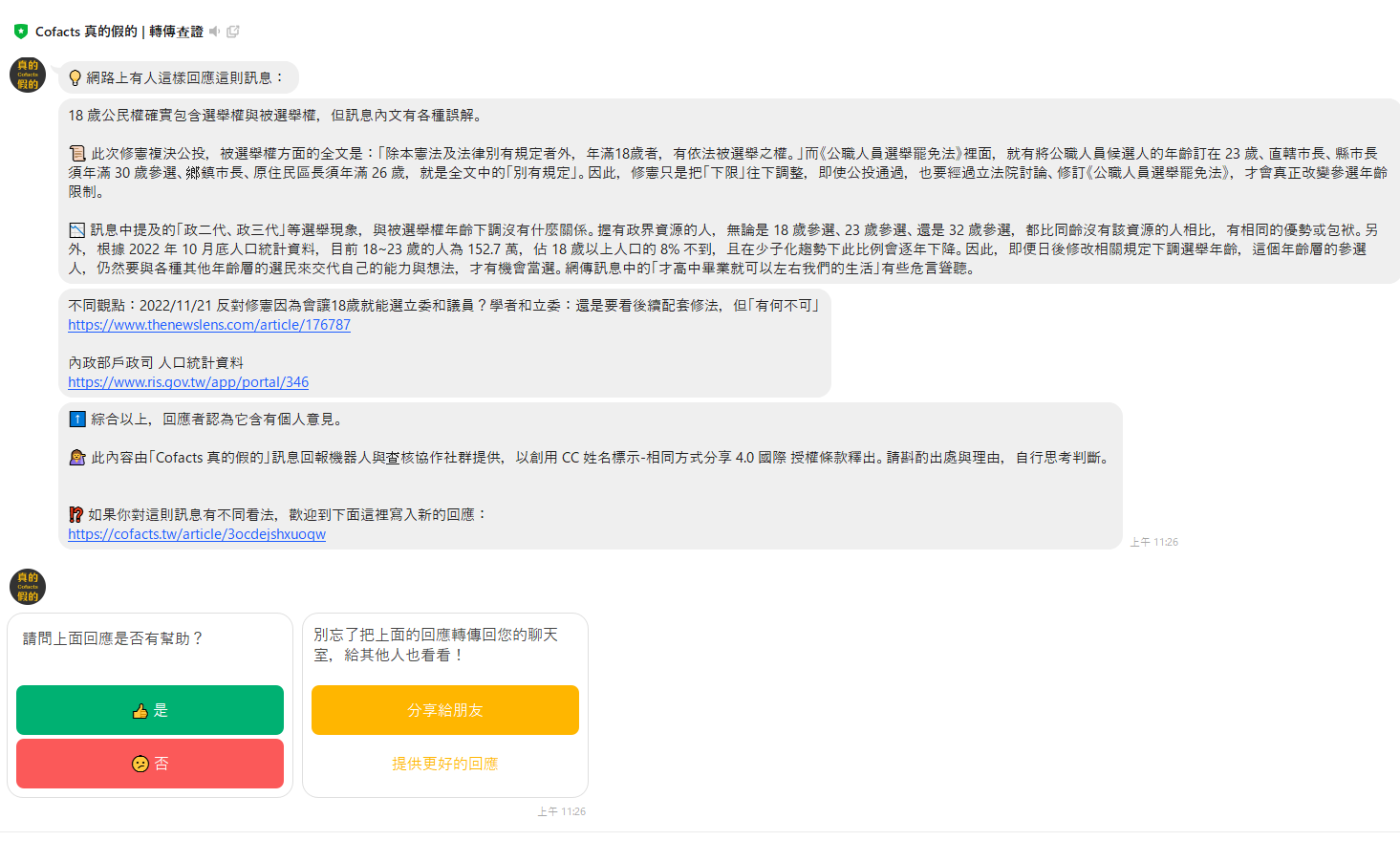
圖/截圖自 Cofacts 群組
你可能會好奇,當今的「人工智慧」(AI)已可查核假訊息,為何 Cofacts 還在仰賴編輯志工這樣的「工人智慧」?李梅君指出,目前的 AI 僅可以偵查大規模的操弄訊息來源,或者評估影像有無修圖造假。當前要用 AI 來判讀文字內容的真偽還相當困難,因為一則文字訊息通常真假資訊參雜,當中還包括個人意見或情緒用詞,很難明確判定是真是假。
因此,Cofacts 的編輯志工除了指出訊息錯誤之處,也會提醒該則訊息是否含有個人意見,有助民眾從封閉的 LINE 群組接收外界聲音,進而創造一處可以參與討論的公共空間,共同思考謠言是什麼、怎麼跟謠言對話。
和時間賽跑 艱辛的闢謠之路
不過該計畫也有艱辛之處,由於需仰賴大量人力進行事實查核,Cofacts 經常面臨闢謠速度趕不上謠言散播的問題。根據統計,Cofacts 的 LINE 目前有 42 萬名好友,過去 10 週每週傳來約 650 則新謠言;目前登記的編輯志工大約有 2,600 多人,但每週會固定回應訊息者只有 20 人上下,平均澄清一則謠言要花 20 至 30 分鐘。
李梅君分享實際參與事實查核的心得:「一開始你可能很熱血地上線回應訊息,但回應了一、二天後,可能會逐漸失去參與感,畢竟你只是一個沒支薪的志工,而且很多謠言看了又很令人痛苦,還要耐著性子花 30 分鐘回應。」
因此,為了維持志工夥伴的參與熱情,Cofacts 每個月都會辦一次聚會,藉由分組競賽活動,讓志工們培養共同打怪的向心力,也可相互交流查核經驗、結交志同道合的朋友。

圖/研之有物
至於使用 Cofacts 釐清謠言的民眾又有何回饋呢?李梅君聽過一些年輕志工分享參與事實查核的原因,主要是想透過 Cofacts 的第三方資訊與長輩對話。雖然不確定長輩能否接受,卻可盡量避免家人之間發生正面衝突。
根據李梅君的觀察,在政治議題上,純粹處理謠言無法真正化解世代衝突,因為謠言只是表現形式之一,背後牽涉每個人不同的價值觀與政治立場,需仰賴更多對話空間的產生。
不過,在疫情期間,與防疫相關的健康資訊則明顯受到不同世代的共同關注,Cofacts 的使用人數因此大幅成長,其中增加最多的就是 50 歲以上的使用者。因為健康資訊較不受政治立場影響,再加上全民必須共同面對疫情威脅,世代衝突的問題自然較少。
公民團體的辛勤奔走 努力提升全民媒體素養才是真正的關鍵
ChatGPT 等生成式 AI 問世後,未來可能會出現更多人為操作的假圖文,或是誤信 AI 偏差回覆等狀況。面對上述危機,李梅君認為:
應對關鍵在於,大眾是否具備足夠的「媒體素養」與「思辨能力」去判讀網路訊息。
可惜這在我們過去的教育裡並不受重視,直到近幾年教育部才開始在 108 課綱下推動「媒體素養教育」,要求在不同年級與學科中融入媒體素養課程。例如資訊課會介紹社群媒體用演算法投放廣告的邏輯;理化課會教學生分辨並思考「偽科學」的成因;國文課則透過閱讀不同文本培養思辨能力。
然而,社會上多數人沒有上過相關課程,很多還是不太熟悉數位工具的長輩,幸好現在有 Cofacts 以及多家臺灣公民團體在做媒體素養教育。他們主動走進長輩的生活圈,教長輩怎麼使用手機、如何確認訊息真假,甚至鼓勵長輩善用發早安圖的習慣,成為謠言破除推手。
李梅君目前的研究正在觀察這些公民團體怎麼採取行動。例如 NGO 組織「假新聞清潔劑」會前進廟口、菜市場或老人服務中心等長輩聚集地,舉辦街頭宣講活動。在宣講過程中,一開始不會直接跟長輩講假訊息,因為假訊息在臺灣的脈絡裡很容易被導向敏感的政治議題,誤以為要聊網軍。
因此,宣講的切入點通常會先問長輩是不是常收到詐騙訊息?接著,志工會分享一些受騙案例,例如有人買了網路一頁式廣告的保養品,結果臉爛掉;或是吃了來路不明的保健食品,最後弄壞身體。藉由生活化、無政治立場、令人感同身受的案例,讓長輩意識到學會辨別訊息真假很重要!
另一個事實查核的組織「MyGoPen|麥擱騙」會製作一則則精美的謠言澄清圖文,吸引長輩像發早安圖一樣,將這些闢謠圖文大量轉發到各個群組。如此一來,長輩本身既可釐清謠言,還可幫助更多長輩遠離詐騙,更證明自己擁有不輸給年輕人的知識與能力。

圖/截圖自 MyGoPen 群組
「我覺得這是很令人感動的事情,因為這個題目很難,可是有很多人願意用不同的角度去介入,而且大部分都是志工。」李梅君有感而發的說。
臺灣長期被國際視為境外假訊息泛濫的國度,如今一個提升全民媒體素養的生態圈正在形成,因假訊息而延伸出的世代衝突問題有待長時間相互理解溝通,但公民社群的力量讓人們看見改變的契機。

延伸閱讀
- 中研院民族所李梅君老師個人網頁
- Mei-chun Lee (2022). “Checking Facts by a Bot: Crowdsourcing Facts through LINE Chatbot in Post-Truth Taiwan.” Current Anthropology.
- Sam Robbins, Mei-chun Lee (2022). “Elderly Care: Taking the Good Morning Image Seriously.” A Broad and Ample Road.
- 【g0v 演講】 「沒有人」的運動:黑客、鄉民、與資料行動主義




































