

本文轉載自中央研究院研之有物,泛科學為宣傳推廣執行單位。
- 採訪撰文│林承勳
- 美術設計│林洵安
自動化音樂展演的可能性
人工智慧(簡稱 AI)技術日新月異,不只打敗人類圍棋高手,現在更用在醫療、交通、金融、資安各領域,遍佈了你我的日常生活。中央研究院資訊科學研究所副研究員蘇黎讓 AI 又多了一項新技能:自動化音樂展演。「虛擬音樂家系統」創造出具有動畫形象的虛擬人物,配合真人一同演出,而且演奏動畫和音樂伴奏皆可自動產生。未來,經營 VTuber(虛擬 YouTuber)背後可能不再需要龐大製作團隊,只要專注在企劃和劇本,其他讓 AI 幫你一鍵生成!

真實與虛擬合奏的貝多芬小提琴奏鳴曲
虛擬音樂家系統,這是蘇黎與其團隊最近的研究成果,他將 AI 應用到音樂表演現場,並試圖推展到整個多媒體產業。這套系統已實際在舞台演示,並與多個音樂展演團隊合作,包括:沛思文教基金會、清大 AI 樂團、長笛家林怡君、口口實驗室等。
以近年蘇黎舉辦的音樂會為例,主要可分為兩部分,一個是台上親手彈奏著貝多芬〈春〉第一樂章伴奏部分的真人鋼琴家;另一個,即為該場演奏的特別之處:正在螢幕裡演奏主旋律的虛擬小提琴音樂家。這場表演是人類與「虛擬音樂家系統」的巧妙組合,真人鋼琴家彈奏的過程中,虛擬音樂家系統除了負責合奏,同時還要生成螢幕上虛擬演奏者的動畫身影。

不放槍、不搶拍的自動伴奏系統
虛擬音樂家系統的「自動伴奏」,不同於卡拉 OK 的機器伴奏,演奏者不需配合伴唱音樂,而是程式控制伴唱音樂以配合演奏者,讓演奏者自由詮釋樂曲。但因為要配合真人演出的現場發揮與不確定性,自動伴奏的運算必須又快又準。蘇黎指出,這也是研究中比較具有挑戰性的部分。
自動伴奏系統的音樂偵測器、音樂追蹤器與位置估算單元,讓虛擬音樂家精準掌握真人演奏實況。
舉例來說,想要跟人合奏,首先要確定能同步開始,這個重責大任就由自動伴奏系統中的「音樂偵測器」擔綱。「音樂偵測器是偵測音樂什麼時候發出,但現場會有其他聲音,不可以讓機器聽到雜音就以為演奏開始了。」蘇黎說,因此團隊會先將整個樂譜,輸入到虛擬音樂家的自動伴奏系統中,並在演奏會場早早就讓系統持續待命,只要音樂偵測器偵測到樂譜的第一個音,伴奏隨即啟動。
自動伴奏系統在確認演奏開始之後,馬上又有另一項任務:追蹤音樂進度。因為每位音樂家會有自己的演奏風格,而且真人不管如何熟練,都還是有可能出現搶拍或延遲等變數。追蹤音樂進度的這項任務,便由自動伴奏系統中的「音樂追蹤器」和「位置估算單元」來執行。
「音樂追蹤器採用多執行緒線上動態時間校正(online dynamic time warping)演算法,每一個執行緒在最短時間內各自計算並取平均值,以找出最貼近該音樂家當下演奏速度的數值。」蘇黎解釋,追蹤器抓到現場演奏速度後拿來跟參考音樂檔案比對,就能推測多久後會演奏下一個音。至於位置估算單元,則是用來估計當下已演奏到整個樂譜的哪個位置。
虛擬音樂家系統藉由上述的自動伴奏技術,追蹤真人演奏進度,並自動觸發並演奏相應的聲部。目前團隊已經將偵測到觸發伴奏的平均延遲控制在 0.1 秒左右,但蘇黎的目標是要降低到「0.01」秒內。蘇黎表示,音樂心理學已證實,就算是沒有經過專業訓練的一般人,0.1 秒的誤差聽起來仍非常明顯,「延遲 0.01 秒可以勉強不引起業餘人士的注意;但面對專業音樂家時,延遲可能要到 0.001 秒左右才能過關。」

訓練 AI 自動生成虛擬音樂家動畫形象
現場音樂表演是影音的雙重享受,所以虛擬音樂家除了擁有自動伴奏的「聲音」,還需要擁有將表演動作形象化的動畫「影像」。
真人音樂家演奏時,不論是情感的表達、與其他合奏者及觀眾互動、還有操作樂器的動作等,都存在個人差異,沒有一套固定標準。例如拉琴的手勢,10 個音樂家可以有 10 種不同的習慣。因此蘇黎與研究團隊採取的方法是:取得大量影音資料,讓 AI 學習如何製造虛擬音樂家的肢體動作。
首先,徵求多位專業小提琴演奏者,穿上有標記點的特殊衣服,站在有動態捕捉裝置的空間中,演奏不同風格曲目。蘇黎使用的 3D 動作偵測技術,會偵測音樂家全身骨骼的關節點,作為虛擬音樂家動畫生成的訓練資料,並在訓練動畫生成模型的過程中,重點關注持弓的右手如何移動。
透過 U 型網路、自注意力機制等核心技術,來輸出虛擬音樂家動態肢體影像。
在訓練 AI 與生成動畫影像的過程中,需要卷積神經網路來協助完成工作。蘇黎團隊採用的模型是 U 型網路(U-net),負責圖像之間的轉換,由編碼圖層傳到解碼圖層。它的優點是速度快,而且輸入輸出格式相對容易設計,能一次輸出大量資料點。「 U-net 可以一次輸出單一時間的所有肢體骨架點,而非一個一個骨架點逐步輸出。」蘇黎說。
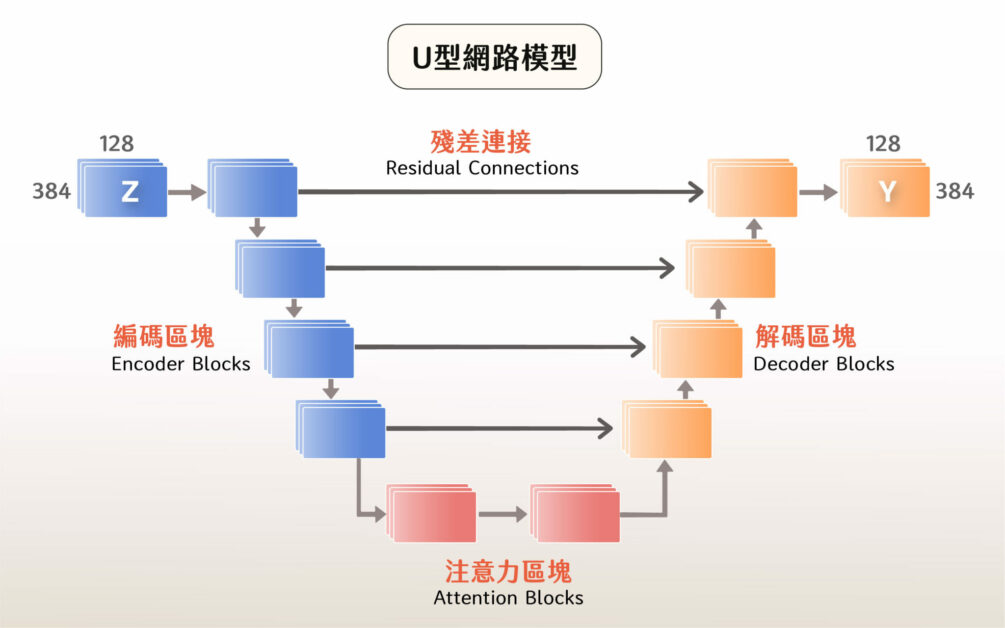
除此之外,還有自注意力(self-attention)機制,讓 AI 學習判斷肢體動作與音樂的相關性。因為肢體動作跟音樂都是序列形式,有時間上的關聯性,假設真人音樂家某個動作在大鼓響起時一直出現,就會判定兩者存在關聯。之後自注意力機制在虛擬動作生成過程中,只要聽到該音樂的大鼓聲出現,就會發出明顯訊號,認為此時要搭配相應的肢體動作。
簡單來說,想要自動化生出虛擬小提琴家,不僅聲音要到位,動畫也要足夠精準。音樂需要自動伴奏系統,即時追蹤真人演奏者的進度並觸發伴奏;而相應的肢體動作,則有賴透過 U 型網路與自注意力機制,讓 AI 在音樂現場了解此時要搭配何種動作。

進階挑戰:由聽覺到視覺的跨感官轉換
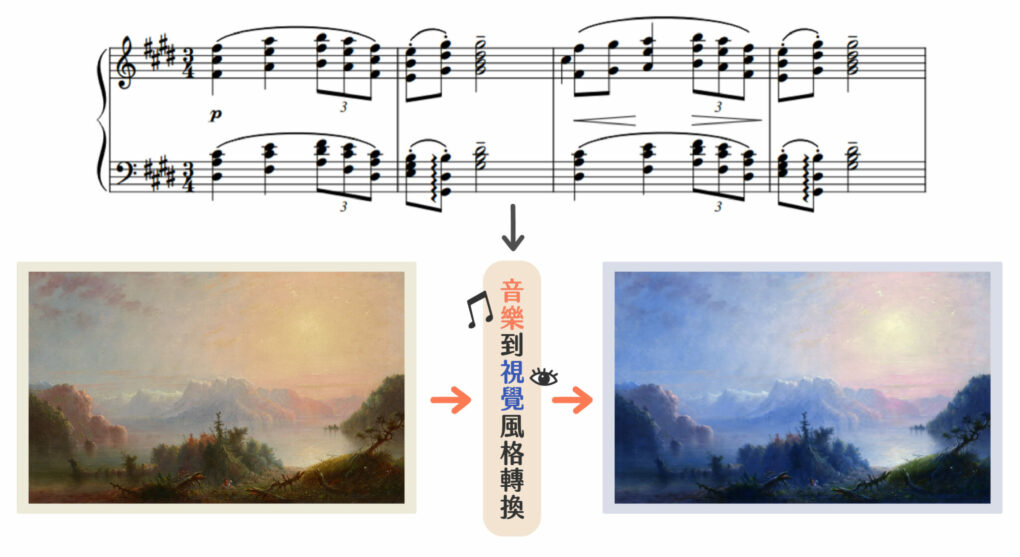
自動生成聲音和影像後,研究團隊還有一個更進階的目標。「我們想讓機器聽到某一首歌,就聯想到一幅畫。但坦白講,這種音樂到視覺風格轉換(music-to-visual style transfer)非常困難。」蘇黎說。當初有學生向他提出這個構想,想要訓練 AI 將音樂與畫面連結。只是這設定一開始就困難重重,因為最重要的訓練資料幾乎是無法取得。
AI 並非無中生有,機器學習有賴龐大、高品質的資料。
想要讓 AI 學習聽音樂聯想畫面,就必須要有真人示範,聆聽音樂並畫出心中所浮現的畫面來當作訓練資料。找人聽音樂不難,但找來的人未必善於繪畫;即使花大錢請畫家參與實驗,人少沒有代表性,人多則風格又可能大相逕庭。「演奏動作還有跡可循,但大家聽音樂腦補的畫面都不一樣,這樣是沒辦法當作訓練素材的。」蘇黎點出其中關鍵。
研究團隊決定退而求其次,改成在一組音樂跟一組影像資料庫,透過兩者之間共享的語義標註(labels),試圖建立起對應關係。就像是電腦在連連看,如果配對起來共通點還算合理就成功。此時問題又來了,所謂「合理」實在難以界定,於是執行標準只好再一次降低,音樂與畫面的共同標註越簡單越好。
「雖然這跟當初想像中的差距非常大,但目前我們也只能用創作年代來當標註。」蘇黎說,經由創作年代這個共同標註,電腦聽到 1800 年的樂曲就會連到同樣年代的圖畫。即使不符原本理想,模型建立起來後,在虛擬音樂家系統裡還是可以發揮一些功能,像是為演奏會搭配符合音樂年代的背景畫面,或色彩效果。
如何成為音樂資訊研究者?
在虛擬音樂家系統之前,蘇黎與實驗室團隊(音樂與文化科技實驗室)在自動音樂採譜方面的研究已經有豐厚成果,他們研發出開源工具《Omnizart》。
《Omnizart》是音樂與文化科技實驗室研究成果集大成的實用開源工具。
它具備當前全世界最多樣樂器組合的分析功能,只要輸入一段音樂,不管是鋼琴獨奏、多重樂器、打擊樂,還是和弦辨識、節拍偵測,甚至是困難的人聲處理,都會幫你分析。
「像鋼琴這類樂器的話,是音樂進去《Omnizart》,生出 MIDI;而人聲進去會輸出成供電腦判讀的數位資料。」蘇黎解釋,透過這些數字化的音訊數據能了解每一瞬間的音高變化,或是泛音、抖音等手法。研究自動採譜 AI 是因為,蘇黎想探究如蕭邦的夜曲等,這些百年來不斷被重複演奏超過千百次的古典樂,在不同時代、風格迥異的音樂家手中究竟是如何被詮釋。
而這次蘇黎用 AI 創造虛擬音樂家系統,同樣也是源於本身對音樂的喜愛與好奇。不是科班出身的他能彈奏鋼琴、吉他,會吹小號,喜歡聽經典的古典樂。對蘇黎來說,興趣是驅使研究向前的一大動力,他認為身為研究者必須要時常探索新的領域,因此常會要求自己不斷接觸世界各國的在地歌謠。
蘇黎的下一步,是以現有虛擬音樂家系統為基礎,加入更多細膩動作(例如臉部表情)的虛擬多人樂團。他也坦言目前自動伴奏系統、肢體生成還有風格轉換這三項技術,都還有很大的進步空間。想訓練電腦產生出更貼近真人演奏者動作的虛擬音樂家,必須花大量人力取得更多影片資料。「民眾常以為不用多做什麼 AI 就會自己學習,但真相是沒有夠好的資料什麼都不用談。」蘇黎解釋,AI 研究者的時間幾乎都耗在蒐集資料上。
同時,研究室也在規劃下一場發表。蘇黎認為,實體演奏會是考驗研究品質最好的方式。除了訓練好模型,現場還有很多要克服的變數,像是很多音樂廳沒有網路,團隊必須將整場演奏會所需的模型,事先設計成用一台筆電就能執行。「總不可能演奏到一半,資料量太大電腦跑不動,然後要跑出去連網路吧。」蘇黎笑著說,音樂會現場要面對很多做研究時不曾碰到的狀況,是很刺激、有挑戰性的任務。
AI 將是未來主流,是好、是壞終究取決於人心。
AI 出現之後,自然也面臨許多批判,例如工作是否會被 AI 取代,甚至以 AI 操控虛假言論或用在軍事用途,但蘇黎覺得,主導權終究還是躲在背後操作的「人」。同樣,隨著虛擬音樂家系統日漸完善,真人音樂家是否擔心未來飯碗被搶走?令人意外的是,蘇黎說身邊最期待這個系統的反而就是與他合作的藝術家,「別小看他們,藝術家可是一群勇敢、期待新事物、信仰未來的人。」

延伸閱讀:
- 蘇黎(2021)。〈我們與機器的距離:與人類互動的虛擬音樂家系統〉,《中研院訊》。
- 張凱鈞(2017)。〈天才莫札特的傳說很狂?現在只要一鍵就做得到!〉,《研之有物》。
- 音樂與文化科技實驗室,《Omnizart: Music Transcription Made Easy》。
- Wu, Y. T., Chen, B., & Su, L. (2020). Multi-Instrument Automatic Music Transcription With Self-Attention-Based Instance Segmentation.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 28, 2796–2809.


































{kind=link}