
「其實我已經不是最年輕的老師了!」陳縕儂笑著說,臺大資工系已經有比她更年輕的老師了,不到30歲就回臺任教不算少見。至於外界好奇她為何捨棄微軟千萬年薪工作回臺大當教授,她的答案很簡潔就是「喜歡」。

喜歡教書、喜歡台灣自由的研究學風,做自己喜歡的事情比較重要。陳縕儂有著不隨波逐流的精神,十年前她選擇「語音辨識」作為研究領域時,資訊界盛行的研究是網路搜尋系統。
就讀研究所時,她跟著李琳山老師做語音辨識系統,當時在訓練機器做錄音和影片中的自動關鍵字擷取,主要是讓機器單向理解人類語言,後來至卡内基梅隆大學攻讀博士,開始做雙向的對話系統,機器不只要理解你說什麼,還要回應、給予相關的協助。
她的目標是讓機器成為鋼鐵人語音助理「賈維斯」(Jarvis)一樣,不只跟你說話,還會幫完成你交辦的訂機票、分析報表等一切任務。隨著深度學習演算法提出,這件事在將來變得可能。
不過,現階段開發的語音助理Siri或Alexa都離Jarvis還有段距離。陳縕儂表示,訓練語音助理的一切事宜,包括:語言理解、自然語言處理、對話系統和機器智慧,都是她的研究範圍。
訓練一位Jarvis要克服哪些問題呢?現在就讓陳縕儂為我們解答吧~
和機器聊天有何困難?
你有沒有發現使用Siri時,常常話不投機半句多,更別說要幫忙處理訂車票、推薦飯店等雜事了。陳縕儂表示,機器要做到可以對話及像真人般的助理服務,從麥克風收音、語音轉成文字、語意理解,最後到協助擷取有用的資訊,每一步都是難關。
Siri是大家常接觸的語音聊天機器人,但它的功能還不算完備(圖片提供/Wikipedia)。
雖然「神經網絡」架構提升語音辨識之準確度,但比起影像辨識或單純語意理解,對話困難許多,因為每句話都有關聯性,百種人有百種答案,而百種答案可能也有百種的回應方式,因此傳統單純塞資料給機器的學習法是行不通的。
陳縕儂表示,要克服這個難題,通常會設計兩台機器,將所有使用者的問題灌入機器中,一台機器當客服人員、一台機器當顧客開始互動,互動一段時間開放真人互動,想辦法讓互動變得更順暢,這是現行最好的方式了。
假使機器與人類可以對答如流,下一步面臨的問題就是機器能不能幫你辦事,當你跟他說「想去東京玩」時,他不會打哈哈叫你搭飛機去東京,而是能依據你的需求,提供你機票、住宿和旅遊景點的建議。
這下可就複雜了,試想你若是個旅行專員,除了回答自己已知的事項,如:旅遊注意事項、服務內容說明,還需要將各地的旅遊景點、飯店和餐廳資訊倒背如流,這對機器來說就得去找自己資料庫外的內容,可能是看完google的資訊或旅遊雜誌,才能回應客戶的需求。
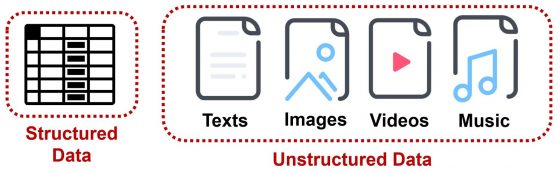
陳縕儂表示,語音助理若要成為Jarvis必須要擅長處理結構化(structured data)和非結構化(unstructured)兩種類型的數據資料。結構化數據是指已經整理成表格的資料,有欄位和數據,可立即做數據分析,這類似語音助理已經內建、整理好的資料庫,提到相關問題可以立即回覆,不需要額外找資料。
然而,大部分的資料都是非結構化資料,像是文字、圖片、網頁和影片等,因此如何快速將沒結構化的資料結構化就是挑戰,這將大大影響機器人提供服務的速度與品質。陳縕儂坦言,目前這兩部分都做得不夠完善,因此她的研究會朝這部分努力。
遇到口音問題怎麼辦?
讓機器成為個人助理之前,更根本的是解決「聽不懂人話」問題,不同的口音確實常讓機器混肴,若把「台式餐廳」聽成「泰式餐廳」,助理找出來的東西就完全不同了!
因此,語音辨識得考慮聲音的錯誤,人才能順暢地與機器對話。陳縕儂表示,她是以跟BERT類似的GPT-2架構來做預訓練模型。概略來說,就是訓練機器學習語言的架構,然後讓機器會根據語音的內容去推估後面兩個字,這部分從Siri轉成文字很像,能依據你講的內容選字。
此時,再把語音的差異納入考量,並將發音相似的字像是「泰、台」調整為同個向量,使得機器得以辨識類似的發音,當機器判讀可能發生誤聽的狀況時,便能再次向使用者確認。
不過陳縕儂坦言,這並不容易,因為聲音資料取得困難,大部分拿到的都是文字資料,再加上機器會算出最合適的語詞和句子結構,所以不同選字會影響後面的詞彙選取,「如何讓機器辨析口音問題」就是個挑戰。
熱愛教學 實踐夢想
語言理解、對話系統和機器智慧是很廣泛的領域,不缺研究主題,陳縕儂認為自己很幸運搭上這股熱潮,且最終回到研究自由度高的台灣繼續努力,她一點都不覺得捨棄微軟工作很可惜。
「教學是很快樂的事情!」她笑說,把自己會的東西交給學生,看到學生從不懂到成為專家,可以跟妳一起討論研究問題,是一件無比有成就感的事。

今年初,陳縕儂帶領臺大團隊在科技部「科技大擂台:與AI對話」比賽拿下冠軍,成績甚至超越華碩電腦達文西實驗室。她形容這是場艱難的馬拉松,從初賽、複賽至決賽比了快一年,決賽題目比照「華語文能力測驗」,機器在比賽現場得聽完一段文章和選項,並選出正確答案,除了選擇題,還有簡答題。
陳縕儂笑說,學生為了訓練機器、調整類神經網絡,以及整合成一個系統熬了無數個夜,這對學生和她來說是個難得的體驗,目前團隊決賽成績是1000題中拿下約54%的正確率,希望未來能再提高,讓機器的成績有機會超過人類。

很多學生覺得自己不夠聰明,沒辦法學好code,陳縕儂認為,聰明確實可以幫你快速掌握code的規則,但是多練習也可以補足,它不會像物理或數學一樣轉不過來就是沒辦法。
她坦言,自己博班時也很拼,一部分是課業負擔重,一部分則是想縮短臺美遠距離戀愛的時間,所以硬是在四年半拼完博士。每天只睡四、五個小時,一睜開眼就坐在電腦前打code,「不過該玩的還是有玩,我是寧可犧牲睡眠,也要玩到的人!」
陳縕儂表示,她比其他人幸運,能一路延續研究旨趣,選到自己熱愛的研究主題。她建議國高中課程可以提早將寫程式納入課程中,這就像Excel和輸入法一樣是未來必備的技能,從中學生也可以挖掘未來志趣,對資訊科學有興趣的,就一起進來努力吧!










































{kind=link}
{kind=link}
{kind=link}