
-----廣告,請繼續往下閱讀-----












Google Tensor 處理器是什麼?厲害在哪?

Google 新出的 Pixel 7 Pro,其核心繼續沿用上一代開始自行研發的晶片,並且升級為 Google Tensor G2。
由 Google 開發、號稱專為 AI 設計打造的 Tensor 晶片,尤其著重在 TPU。打開處理器 Google Tensor 一探究竟,裡面放著 CPU、GPU,以及擁有 AI 運算能力的 TPU(Tensor Processing Unit)張量處理單元。
什麼是 TPU?與 CPU、GPU 有什麼不同?要了解 TPU,先來看看他的前輩 CPU 和 GPU 是如何運作的吧!
TPU 處理器晶片是什麼?先從了解 CPU 開始!
不論手機、電腦還是超級電腦,當代計算機的通用架構,都是使用以圖靈機為概念設計出來的馮紐曼架構,這個程式指令記憶體和資料記憶體合併在一起的概念架構,從 1945 年提出後就一直被使用到現在。
除了輸入輸出設備外,架構中還包含了三大結構:記憶體 Memory、控制單元 CU 與算術邏輯單元 ALU。在電腦主機中,控制單元 CU 和算術邏輯單元 ALU 都被包在中央處理器 CPU(Central Processing Unit)中;記憶體則以不同形式散佈,依存取速度分為:暫存器(Register)、快取(Cache)、主記憶體(Main memory)與大量儲存裝置(Mass storage)。
-----廣告,請繼續往下閱讀-----
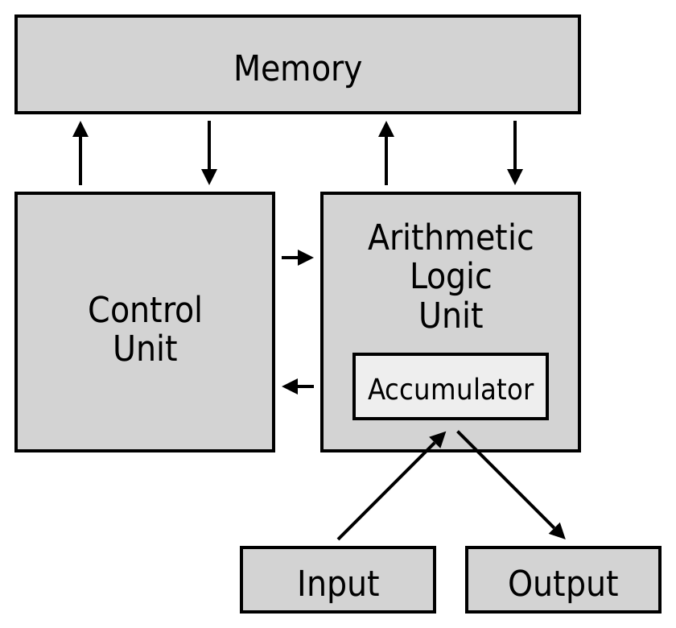
算術邏輯單元 ALU 負責運算,透過邏輯閘進行加減乘除、邏輯判斷、平移等基礎運算,透過一次次的運算,完成複雜的程式。有了精密的算術邏輯單元,還有一個很重要的,也是控制單元 CU 最主要的工作——流程管理。
為了加速計算,CU 會分析任務,把需要運行的資料與程式放進離 ALU 最近、存取速度最快的暫存器中。在等 ALU 完成任務的同時,CU 會判斷接下來的工作流程,事先將後面會用到的資料拉進快取與主記憶體,並在算術邏輯單元完成任務後,安排下一個任務給它,然後把半完成品放到下一個暫存器中等待下一步的運算。
CPU 就像是一間工廠,ALU 則是負責加工的機器,CU 則作為流水線上的履帶與機械手臂,不斷將原料與半成品運向下一站,同時控制工廠與倉庫間的物流運輸,讓效率最大化。
然而隨著科技發展,人們需要電腦處理的任務量越來越大。就以照片為例,隨手拍的一張 1080p 相片就含有1920*1080 共 2073600 個像素,不僅如此,在彩色相片中,每一個像素還包含 R、G、B 三種數值,如果是有透明度的 PNG 圖片,那還多一個 Alpha 值(A值),代表一張相片就有 800 萬個元素要做處理,更不用說現在的手機很多都已經能拍到 4K 以上的畫質,這對於 CPU 來說實在過於辛苦。
-----廣告,請繼續往下閱讀-----

由於 CPU 只有一條生產線,能做的就是增加生產線的數量;工程師也發現,其實在影像處理的過程中,瓶頸不是在於運算的題目過於困難,而是工作量非常龐大。CPU 是很強沒錯,但處理量能不夠怎麼辦?
那就換狂開產線的 GPU!
比起增加算術邏輯單元的運算速度,不如重新改建一下原有的工廠!在廠房中盡可能放入更多構造相同的流水線,而倉庫這種大型倉儲空間則可以讓所有流水線共同使用,這樣不僅能增加單位體積中的運算效能,在相同時間內,也可以產出更多的東西,減少一張相片運算的時間。
顯卡大廠 NVIDIA 在 1999 年首次提出了將圖形處理器獨立出來的構想,並發表了第一個為加速圖形運算而誕生、歷史上第一張顯卡—— GPU(Graphics Processing Unit)NVIDIA GeForce 256。
在一顆 GPU 中會有數百到數千個 ALU,就像是把許多小 CPU 塞在同一張顯卡上;在影像處理的過程中,CU 會把每一格像素分配給不同的 ALU,當處理相同的工作時,GPU 就可以大幅提升處理效率。
-----廣告,請繼續往下閱讀-----
這也是為什麼加密貨幣市場中的「礦工」們,大部分都以 GPU 作為挖礦工具;由於礦工們實際在做的計算並不困難,重點是需要不斷反覆計算,處理有龐大工作量的「工作量證明機制」問題,利用 GPU 加速就是最佳解。
不過,影像處理技術的需求隨著時代變得更加複雜,這就是人工智慧的範疇了。以一張相片來說,要能認出是誰,就需要有一道處理工序來比較、綜合諮詢以進行人臉辨識;如果要提升準度,就要不斷加入參數,像是眼鏡的有無、臉上的皺紋、髮型,除此之外還要考慮到人物在相片中的旋轉、光線造成的明暗對比等。

每一次的參數判斷,在機器學習中都是一層不同的過濾器(filter)。在每一次計算中,AI 會拿著這個過濾器,在相片上從左至右,從上至下,去找相片中是否有符合這個特徵;每一次的比對,就會給一個分數,總分越高,代表這附近有越高的機率符合過濾器想找的對象,就像玩踩地雷一樣,當這邊出現高分數的時候,就是找到目標了。
而這種方式被稱為卷積神經網路(Convolutional Neural Networks, CNN),為神經網路的一種,被大量使用在影像辨識中。除了能增進影像辨識的準確度外,透過改變過濾器的次數、移動時的快慢、共用的參數等,還可以減少矩陣的運算次數、加快神經網路的計算。
-----廣告,請繼續往下閱讀-----
然而即便如此,工作量還是比傳統影像處理複雜多了。為應對龐大的矩陣運算,我們的主角 TPU(Tensor Processing Unit)張量處理單元就誕生了!
TPU 如何優化 AI 運算
既然 CNN 的關鍵就是矩陣運算,那就來做一個矩陣運算特別快的晶片吧!
TPU 在處理矩陣運算上採用脈動陣列(Systolic Array)的方式;比起 GPU 中每個 ALU 都各做各的,在 TPU 裡面的資料會在各個 ALU 之間穿梭,每個 ALU 專門負責一部分,共同完成任務。這麼做有兩個好處,一是每個人負擔的工作量更少,代表每個 ALU 的體積可以再縮小;二是半成品傳遞的過程可以直接在 ALU 之間進行,不再需要把半成品借放在暫存區再拿出來,大幅減少了儲存與讀取的時間。
在這樣的架構下,比起只能塞進約 4000 個核心的 GPU,TPU 可以塞進 128*128 共 1.6 萬個核心,加上每個核心負擔的工作量更小,運算速度也就更快、耗電量更低。我們經常使用的 google 服務,許多也是用了 TPU 做優化,像是本身就是全球最大搜尋引擎的 google、google 翻譯、google map 上都大量使用了 TPU 和神經網路來加速。
-----廣告,請繼續往下閱讀-----

2021 年,Google 更把 TPU 導入到自家手機產品中,也就是前面我們提到的 Google Tensor;今年更是在 Pixel 7 中放入升級後的 Google Tensor G2。
Google 表示新款人工智慧晶片可以加快 60% 的機器學習速度,也加快語音助理的處理速度與增加功能、在通話時去除雜音增進通話品質等,不過最有感的還是圖像處理,像是透過 AI 多了修復模糊處理,不僅可以修正手震,還能把舊相片也變得清晰。
現在新款的手機為凸顯不同,越來越強調自家晶片設計與效能的差異;除了 Google 的 TPU 外,其他公司也朝著 AI 晶片的方向前進,包括蘋果、高通、聯發科、中國的寒武紀等,也都發表了自行研發的神經網路處理器 NPU。
歡迎訂閱 Pansci Youtube 頻道 獲取更多深入淺出的科學知識!
發表意見

所有討論
0



{kind=link}