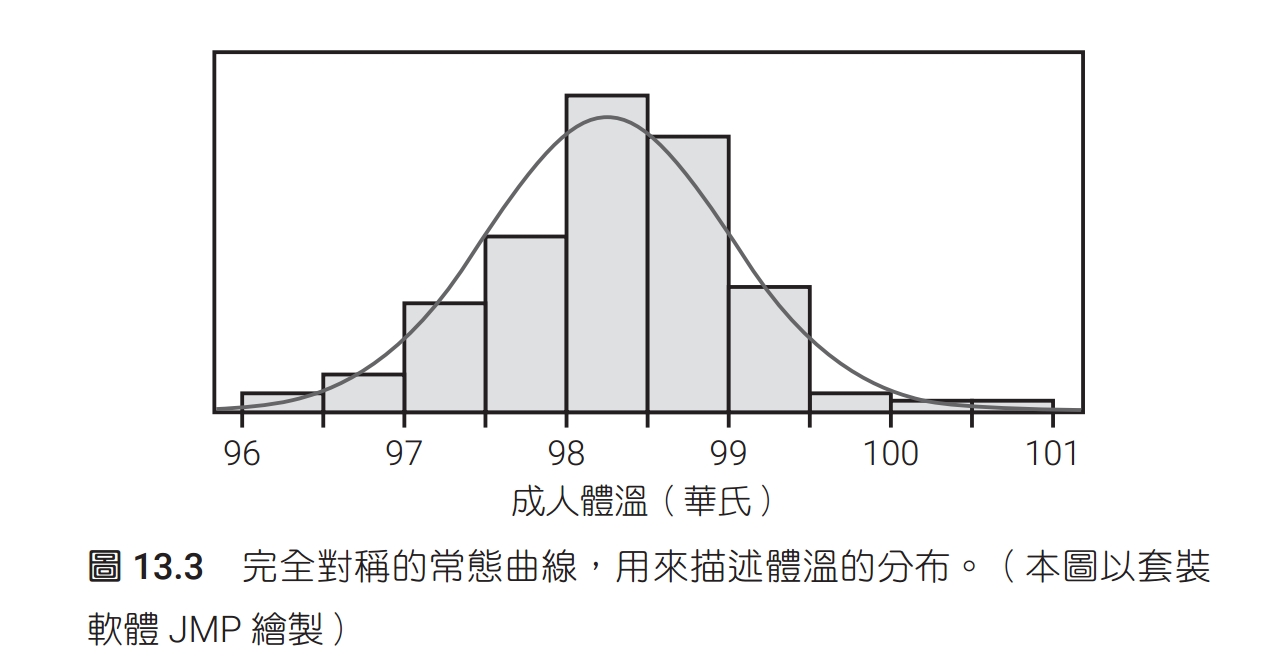
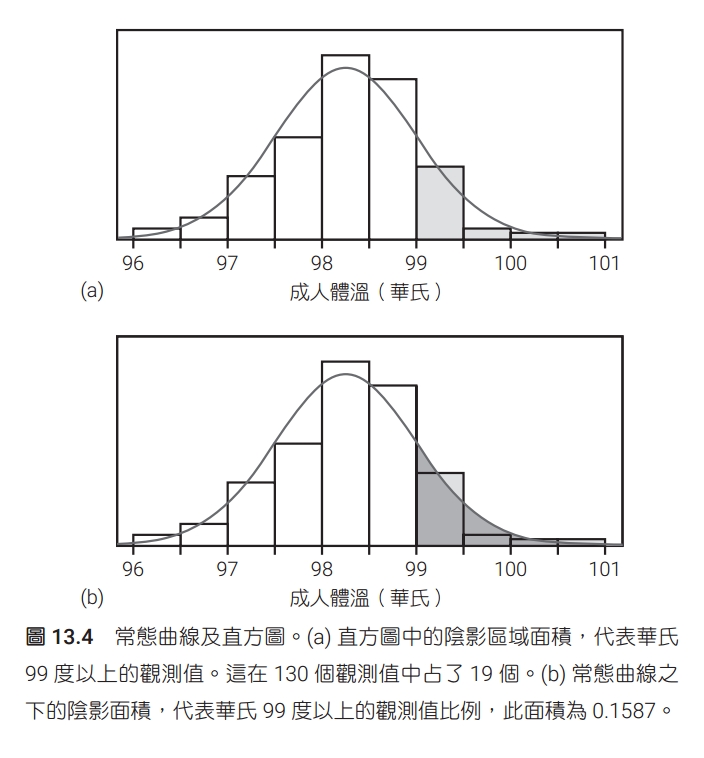
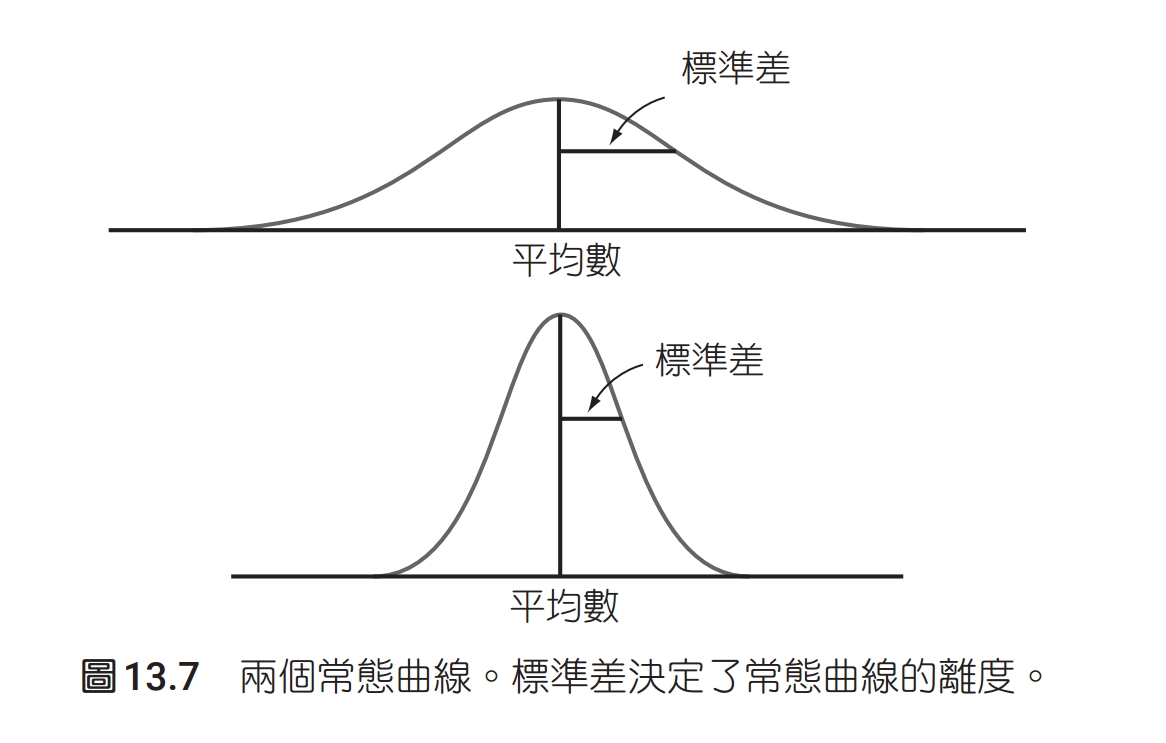
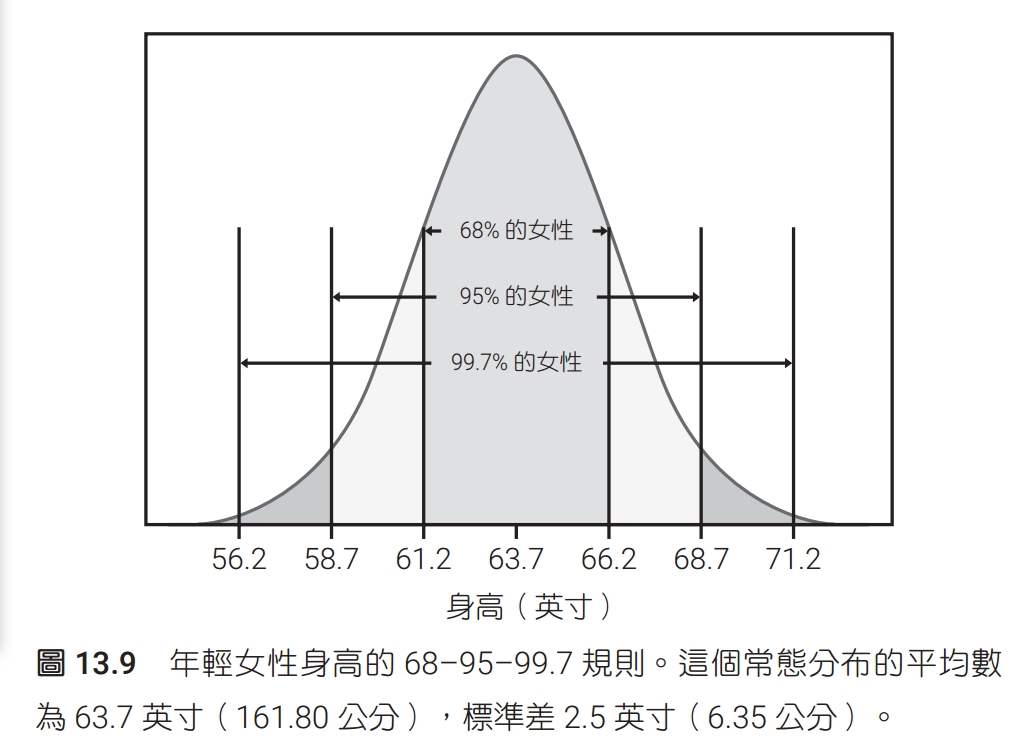
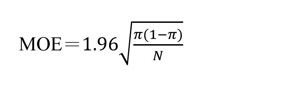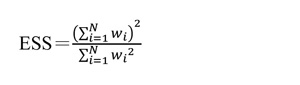常態曲線有個特別的性質是,只要知道平均數及標準差,整條曲線就完全確定了。平均數把曲線的中心定下來,而標準差決定曲線的形狀。變動常態分布的平均數並不會改變曲線的形狀,只會改變曲線在 x 軸上的位置。但是,變動標準差卻會改變常態曲線的形狀,如圖 13.7 所示。標準差較小的分布,散布的範圍比較小,尖峰也比較陡。以下是常態曲線基本性質的總結:
常態密度曲線的特性
常態曲線(normal curve)是對稱的鐘形曲線,具備以下性質:
只要給了平均數和標準差,就可以完全描述特定的常態曲線。
平均數決定分布的中心,這個位置就在曲線的對稱中心。
標準差決定曲線的形狀,標準差是指從平均數到平均數左側或右側的曲率變化點的距離。
為什麼常態分布在統計裡面很重要呢?首先,對於某些真實數據的分布,用常態曲線可以做很好的描述。最早將常態曲線用在數據上的是大數學家高斯(Carl Friedrich Gauss, 1777 – 1855)。
人類智慧高低的分布,是不是遵循常態分布的「鐘形曲線」?IQ 測驗的分數的確大致符合常態分布,但那是因為測驗分數是根據作答者的答案計算出來的,而計算方式原本就是以常態分布為目標所設計的。要說智慧分布遵循鐘形曲線,前提是:大家都同意 IQ 測驗分數可以直接度量人的智慧。然而許多心理學家都不認為世界上有某種人類特質,可以讓我們稱為「智慧」,並且可以用一個測驗分數度量出來。
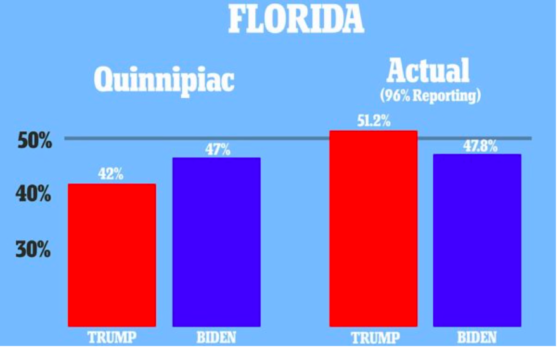
首先解釋第一個問題:所謂「抽樣誤差」(margin of error)的是當母體比例為π時,重複抽取許多樣本所得樣本比例 P 的標準差乘以 1.96。更詳細地說:當母體比例為π時,重複抽取許多樣本數為 N 的樣本會得到許多不同的P值,這些 P 值的分佈稱作 P 的「抽樣分佈」(sampling distribution)。
-----廣告,請繼續往下閱讀-----
根據中央極限定裡,P 的抽樣分佈是以π為中心的常態分佈,其變異量是 π(1-π)/N。我們若以π為中心取一個區間(π-m, π+m)讓 P 落在區間內的機率為 95%,則代表此區間寬度的 m 即為 95% 信心水平之下的抽樣誤差,其公式為:
一般民調樣本因為不是使用「簡單隨機抽樣」(simple random sampling)得到的結果,母體中每人被抽到的機率並不一致。因此,樣本中某些族群的代表性並不能反映它們在母體中的代表性。為了讓各族群在樣本中的代表性和母體一致,樣本必須經過加權處理。上述聯合報和蘋果日報的報導便報告了它們民調的抽樣設計和加權的概略步驟。一般民調機構會把加權所使用的權重存為資料中的一個變數,其數值代表樣本中每個受訪者所代表族群的權重。
台大電機系畢業,美國明尼蘇達大學政治學博士,
現任教於美國德州大學奧斯汀校區政府系。
林教授每年均參與中央研究院政治學研究所及政大選研中心
「政治學計量方法研習營」(Institute for Political Methodology)的教學工作,
並每兩年5-6月在台大政治系開授「理性行為分析專論」密集課程。
林教授的中文部落格多為文學、藝術、政治、社會、及文化評論。