我們需要覆蓋率更高的網路!低軌道衛星通訊的好處在哪?臺灣有機會發展自己的「星鏈」嗎?
要是海底電纜被截斷,馬斯克的星鏈又不幫忙?台灣會不會成為資訊孤島?
近年 SpaceX 不斷發射 Starlink,看起來野心滿滿,多到都成為光害了。
在烏俄戰爭爆發後,Starlink 為烏克蘭提供的不間斷網路服務,更讓全世界看見低軌道衛星通訊的重要性。
通訊戰已經逐漸打到太空,台灣也不遑多讓。今年 11 月 12 日,鴻海與中央大學合作的兩枚低軌道通訊衛星珍珠號,以及成功大學與智探太空合作的立方衛星「IRIS-C2」已經成功升空,三顆衛星都已經取得了聯繫。台灣,也能很快擁有自己的星鏈嗎?我們還欠缺哪些關鍵技術呢?
什麼是低軌道衛星?它可以取代海底電纜嗎?
在全民都會上網的現代,我們的電腦網路依靠光纖等實體線路,手機、WIFI 通訊則仰賴周遭的基地台,因此只要手機離基地台太遠,就會收不到訊號。未來,這些問題低軌道通訊衛星都能解決。這些在天上快速移動的衛星,只要數量夠多,就能覆蓋整個地球表面。因此不論你是在遠離基地台的深山,甚至是高空中的飛機,都能透過通訊衛星來連線上網。
除此之外,在 5G 通訊逐漸成熟的現在,下一代通訊技術 B5G 追求更快、更低延遲的數據傳輸,也會需要低軌通訊衛星來解決傳統基地台功率與覆蓋性不夠的問題。
但因為人口密集、土地面積小,台灣現在的無線網路服務覆蓋率已經很高了。台灣需要擔心的另一個問題是對外的海底電纜斷裂,使我們與世界失去聯繫手段。
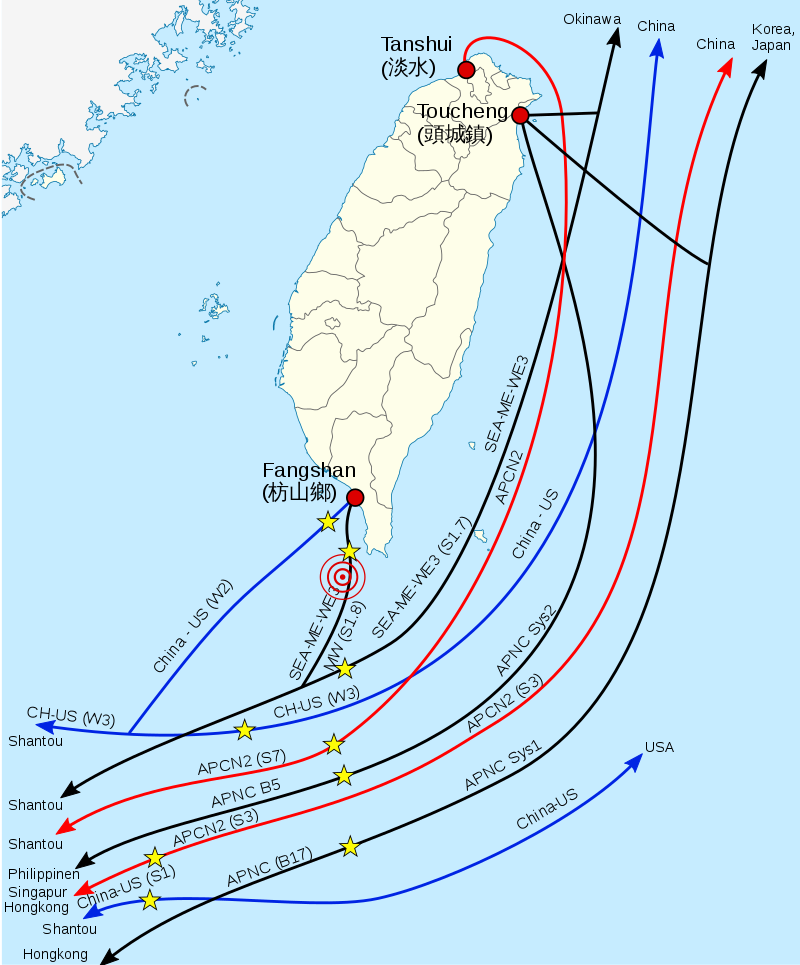
除了要擔心戰爭爆發時敵人為了封鎖台灣消息,而主動破壞電纜以外。台灣周邊的電纜也常因為底拖網、抽砂船作業時被破壞,甚至天災都可能導致電纜被破壞。例如 2006 年恆春地震發生時,高屏海底峽谷就產生海底濁流,也就是海底的土石流。這股海底濁流一衝而下,破壞了呂宋海峽的數條電纜,不只影響了整個東亞以及東亞到美國、英國之間的通訊,包括許多跨國銀行交易。海底電纜斷裂的影響層面非常廣,2006 年恆春電纜斷裂事件發生後,還被聯合國國際減災策略署(ISDR)形容為「現代新型態災難」。
不論海底電纜斷裂的原因會是什麼,我們都需要有充足的準備來應對,而低軌道通訊就是其中的首選。
目前全球有在發展低軌道通訊的不只有 SpaceX 的 Starlink,其他還有 Amazon 的 Kuiper、加拿大的 Telesat 和由美國、歐洲、日本等企業投資的 EutelSat OneWeb 等等。
當然,其中最受矚目的當然還是 Starlink,而且它的發展速度真的有夠誇張。Starlink 在 2020 年才開始在北美提供服務, 去年 4 月我們製作了一集節目在介紹 Starlink,當時就已經總共有 2,000 顆星鏈衛星被發射上太空,服務使用者有 25 萬人。到了今年 8 月,短短又 16 個月經過,在低軌道運行的衛星數量,從兩千顆增加到了 4500 顆,用戶人數從 25 萬人暴增到突破 200 萬人,這肯定是打了針或是吃了藥。當然,訂閱 Starlink 的服務可能需要考慮考慮,但訂閱泛科學頻道,請不要再考慮了,就在這邊,趕快按下去吧! 然後別忘了,SpaceX 的野心,是在天上佈下總計 42000 顆的通訊衛星,大約是現在數量的再十倍,當這個目標達成時,我們的通訊手段可能將迎來天翻地覆的變化。
你可能好奇,這些距離地面遙遠的通訊衛星,能提供多快的上網速度?會不會衛星通訊到頭來只是個噱頭?在光纖電纜的技術進步下,海底電纜的速度確實已經非常快,傳輸速度是低軌衛星的五千到十萬倍左右,這根本是阿烏拉對上芙莉蓮,只有被虐的份啊!
世界越快心則慢,但網路越慢心更急。Starlink 到底夠不夠用呢?依照 Starlink 實際用戶的實測回饋,雖然星鏈服務的 Ping 值多落在 15~60ms 左右,下載約 100 Mbps,上傳約 15Mbps,但對於一般消費者來說已經算是能接受的了。尤其對於偏遠地區、研究站的通訊,又或是未來 B5G、6G 物聯網中,與大量自動駕駛汽車、智慧裝置的連動,通訊衛星都將成為可考慮的另類選擇。
但如果我們未來不想只看馬斯克或是大公司的臉色,勢必需要發展屬於自己的通訊衛星。那麼,發展一顆通訊衛星,需要哪些技術呢?
低軌道有多「低」?低軌道通訊衛星需要哪些技術?
實際上,在低軌通訊衛星出現之前,我們早就有使用衛星進行通訊的經驗,例如衛星電視使用的廣播衛星。然而廣播衛星和低軌道衛星卻有著完全不同的設計邏輯,這是挑戰,也是機遇。
廣播衛星位於地球同步軌道,距離地面約 4 萬 2 千公里,優點是距離地面遠,因此一顆衛星的覆蓋範圍極廣,只要三顆衛星就能覆蓋地球大部分地區。缺點就是距離地面真的太遠了,就算以光速傳遞訊息,來回 8 萬 4 千公里,就有 0.28 秒的延遲,想必沒有人希望用這種速度來上網。 而低軌道衛星,例如 Starlink,就將他們的衛星分布在距離地面 350 至 1500 公里之間,只有地球同步軌道的 120 分之一到 28 分之一的距離和訊號延遲。反過來說,低軌道的優點是延遲短,缺點就是覆蓋面積小,因此才需要那麼多的衛星來覆蓋整個地球。
再來,在天線的設計上也完全不同。接收廣播衛星訊號的天線,就是我們暱稱為小耳朵的衛星碟形天線,通常設計成凹面鏡的樣子。根據光學原理,平行光入射凹面鏡後,會聚焦在焦點。也就是說,接收器不是圓盤本身,我們會將接收器放置在焦點來接受最強的訊號。除了小耳朵之外,大型電波望遠鏡的設計,也是出於同樣的原理。
Starlink 的做法則不是這樣,因為用戶不只有接收訊息,還需要發送訊息。Starlink 的天線,是一個稱作 Dishy McFlatface 的小圓盤,只是後來變成方形了就是了。當你在自家屋頂或庭院設置了 Dishy,它內建的 GPS 會鎖定自己與附近 Starlink 衛星的位置,並且建立點對點的雙向資料傳輸。
重點來了,要做到點對點的傳輸,代表這些電磁波訊號不能再是廣播衛星那種廣發的波狀訊號,而是要聚集到一條又窄、能量密度又高,如同雷射般的筆直路線上。
有在看我們節目的泛糰肯定有印象,這是我們今年第三次提到這個技術了。沒錯,在無線獵能手環還有宇宙太陽能這兩集中,都有遇到需要遠距傳遞電磁波能量或訊號的情況。其實用到的技術都相同,那就是波束成型(Beamforming)。誒,我們都報明牌那麼明顯了,還不趕快找概念股,然後訂閱一下泛科學嗎?
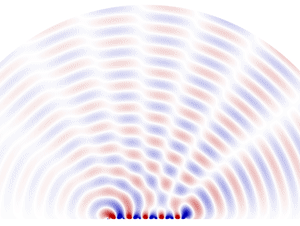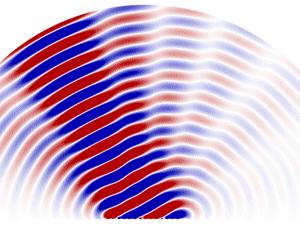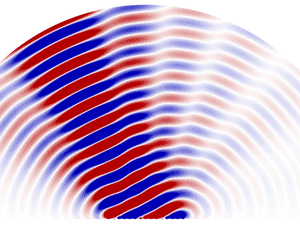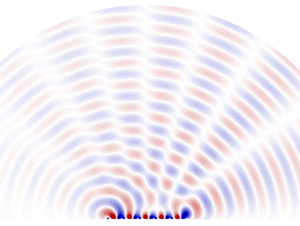
一般來說,電磁波都會如同水波般向外發散,波束成型會先把一個訊號源拆成數個小訊號源,將這些訊號源排成一排,並且控制大家的相位。在電磁波的互相干涉下,就會形成一條筆直前進的電磁波。你可以想像一群本來正各自單兵作戰的士兵,透過整隊與喊口號將大家都動作同步,那麼這些士兵就會一起筆直地朝一個方向前進。在比較舊的 Dishy 型號中,寬 55 公分的圓形接收器上,裡面共有 1280 個六角型,每個六角形裡面都是一個天線,這些天線在波束成型後,會構成一個筆直、能量又強的電磁波束,與天上的衛星展開通訊。
咦?但衛星一直在動啊,難道天線也要一直追著衛星跑嗎?其實不用,我們只要對這群士兵下向左轉、向右轉的口令就好。例如我們喊向左轉,那只要左邊的士兵步伐放慢,右邊的士兵加快速度,就能完成轉向。同樣的道理,我們只要改變每個訊號源發出訊號的時機,改變每個波的相位,就能讓干涉出的訊號朝向特定角度,而不用機械式的移動天線本身。而能做到這種功能的天線,我們稱為相控陣列天線。
相控陣列天線(Phased array)的工作原理是改變每個訊號源發出訊號的時機和每個波的相位,讓干涉出的訊號朝向特定角度。圖/wikimedia
知道了地面天線如何和低軌道通訊衛星取得聯繫後,還沒完。這些丟出去的指令,衛星收到了沒錯,但如果你想要連上網際網路,最終這些訊號還是要能連上有線網路。
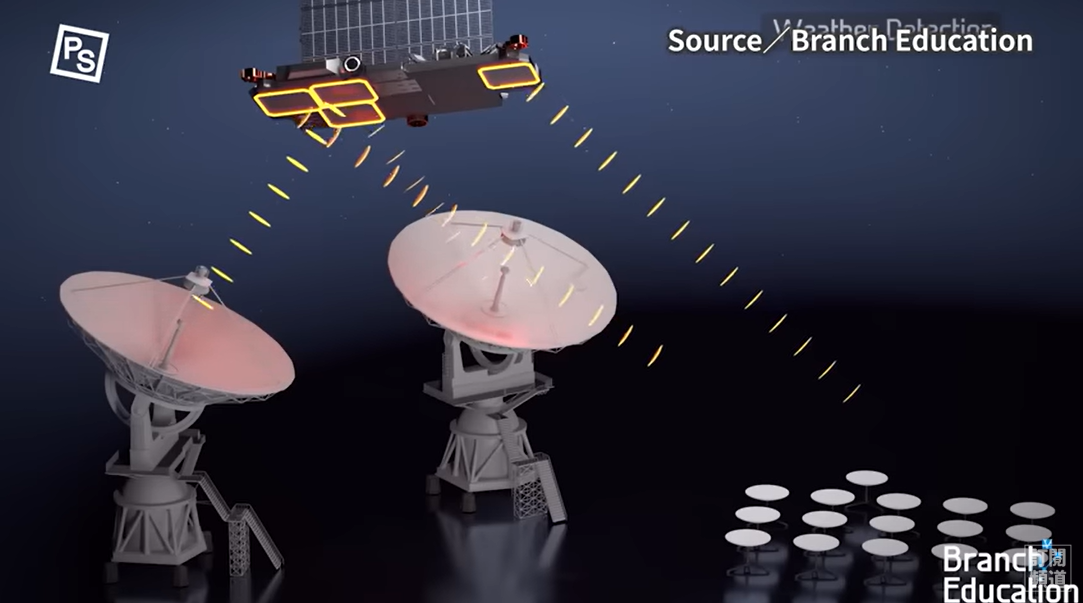
在星鏈 1.0 時,每顆 Starlink 衛星都是單獨運作,衛星在接收地面天線發出的訊號後,會傳遞到附近的地面接收站 Gateways,接著 Gateways 一樣會走光纖電纜的方式與網際網路連接,讓用戶得以上網。地面接收站一般設有 9 個雷達天線,每個直徑 2.86 公尺。衛星本體,例如 Starlink 2.0 上,則配有四個陣列天線,兩個用來與使用者相連,兩個連向地面接收站。
然而,這樣的設計限制了 Starlink 的服務,因為這代表地面接收站與你的天線,必須同時在同一顆衛星的訊號範圍內。但是低軌衛星的覆蓋範圍又不大,一個地面站只能照顧方圓 800 公里內的用戶。因此如果你家附近沒有地面接收站,抱歉,你還是收不到訊號的。如果你在廣闊的大海上,就更不用想了。再來,就算 Starlink 提供全台灣的無線網路服務,但如果這個地面接收站就設置在台灣,那麼當台灣的對外海底電纜斷了,就一樣回天乏術,星鏈的設置可說是毫無價值。
SpaceX 當然也想擺脫地面接收站的束縛,況且如果到了海上就收不到訊號,那可遠遠無法稱上「全球通訊」。因此到了 Starlink 2.0 時,衛星間通訊技術 LISL (Laser Inter Satellite Link) 全面安裝到了衛星上,藉由衛星間的通訊,取代海底電纜的作用,進行跨地區的通訊服務。你看,現在不只海底有資訊高速公路,在天上也出現了網路任意門。比起過去衛星間使用的無線電傳輸,使用 LISL 技術的衛星與衛星之間,用的是雷射。雷射傳訊不僅頻寬較寬,因為光在真空中的速度是最快的,比在光纖中還快。因此與海底電纜相比,傳輸速度反而有可能更快,衛星間的雷射通訊技術,也成為目前太空研究領域中非常重要的一環。
在通訊研究中,除了硬體技術的革新外,另一個最大的問題是,如此龐大的星鏈星座網路該怎麼設計?如何選擇地面天線要與哪個衛星通訊?每個衛星該攜帶多少個雷射發射器與接收器?資料傳輸要經過幾個衛星,才不會因為過多的路由,造成網路延遲飆升。哇~諸如此類的網路設計難題,都是因應通訊衛星而生的新型態網路結構所需面對的課題。而當這些問題被解決,那麼 Starlink 將真正全面擺脫地面接收站,並且能向地球上任何一個角落提供不受限的網路服務。
台灣的低軌道通訊衛星
根據中央社報導,台灣和 SpaceX 從 2019 年開始就展開嘗試性商談,但至今仍未能談妥。今年 11 月 14 日,中華電信成功與另一家公司簽署了台灣低軌衛星的獨家代理合約。這間搶在 SpaceX 之前簽約的公司,就是前面也提到過的 Eutelsat OneWeb。相較於 SpaceX 已經發射升空的 Starlink 大約有 4500 顆,Eutelsat OneWeb 現在的低軌衛星數量大約有 600 顆。台灣的目標,則是在 2024 年底前,布建國內 700 個、國外 3 個非同步軌道衛星的終端設備站點、以及 70 個將資訊候傳的設備站點,建構能完整覆蓋全台的衛星通訊。
除了與現有的低軌道通訊服務公司簽約外,在打造自製台版星鏈的道路上,也傳來令人振奮的消息,就在簽約的兩天前,11 月 12 日,由中央大學與鴻海科技集團共同研發的珍珠號 PEARL-1C 和 PEARL-1H,兩顆立方衛星升空,並且與地面取得聯繫。搭載的儀器除了中央大學的電離層探測儀之外,還包含了 Ka 頻段的通訊酬載以及剛剛介紹的相控陣列天線,希望能為台灣自製的低軌道衛星通訊打下基礎。
國家太空中心則預計在 2026 年,將第一顆低軌通訊衛星送入太空,2028 年發射第 2 顆。希望能推動 B5G 的發展,並成為發展台版星鏈的敲門磚。
目前台灣的太空領域,許多的技術都正在發展、測試階段。除了這集提到的相控陣列天線、衛星間通訊技術,還有這集還來不及提到的長時間航行的充電問題、姿態校正問題,甚至是未來自行發射衛星的所需要的火箭科技,都需要一步步來解決、實踐。而且根據太空中心估計,至少要擁有 120 顆低軌道通訊衛星,才能確保全台 24 小時的通訊都不間斷,要達成這個艱鉅的任務,我們還有好多路要走,好多衛星要升空。
但千里之行,始於足下,千星之鏈,始於發射架。從福衛系列衛星到獵風者衛星,台灣的太空路線越來越鮮明,也讓人期待包括火箭、衛星到通訊技術的未來發展。
這集我們以 Starlink 為例,詳細的介紹了低軌通訊衛星的重要性,以及需要面對的技術突破。
也想問問大家,你覺得未來低軌通訊衛星,會如何改變網路市場呢?
衛星通訊成為常態,到哪都可以上網,等等這代表不管去哪都無法以網路不穩當藉口了嗎?可惡!
衛星通訊只是壁花配角,有線的海底電纜終究是主流
先等等,衛星競爭太激烈,衛星都比星星還要多了,真的不會在天上發生連環車禍嗎?
歡迎訂閱 Pansci Youtube 頻道 獲取更多深入淺出的科學知識!
參考資料









































{kind=link}
{kind=link}